需要用到hive了,我来看看我之前配置的hive能使用吗
但是在>hive 输入命令就无响应,很长时间后就报这样的错误
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException:
我查询半天无果,一直无反应,直到过了好几个小时,
我终于发现一个很坑的地方,因为是笔记本所以一直连的不同的WIFI所以需要在hive-site.xml 文件中修改mysql的地址
就可以了
又发现一个非常奇怪的问题,有时候写insert 可以成功,有时候失败, 我感觉是hadoop的mapreduce执行的问题但是很怪。有这样的错误
Error during job, obtaining debugging information...
Examining task ID: task_1632745139502_0003_m_000000 (and more) from job job_1632745139502_0003
Task with the most failures(4):
-----
Task ID:
task_1632745139502_0003_m_000000
URL:
http://hadoop103:8088/taskdetails.jsp?jobid=job_1632745139502_0003&tipid=task_1632745139502_0003_m_000000
-----
Diagnostic Messages for this Task:
[2021-09-27 20:26:35.473]Container [pid=9197,containerID=container_1632745139502_0003_01_000005] is running 256072192B beyond the 'VIRTUAL' memory limit. Current usage: 90.4 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1632745139502_0003_01_000005 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 9208 9197 9197 9197 (java) 304 15 2501140480 22858 /opt/module/jdk1.8.0_212/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/module/hadoop-3.1.3/data/nm-local-dir/usercache/jxp/appcache/application_1632745139502_0003/container_1632745139502_0003_01_000005/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1632745139502_0003/container_1632745139502_0003_01_000005 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.10.102 43227 attempt_1632745139502_0003_m_000000_3 5
|- 9197 9196 9197 9197 (bash) 0 0 9789440 288 /bin/bash -c /opt/module/jdk1.8.0_212/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/module/hadoop-3.1.3/data/nm-local-dir/usercache/jxp/appcache/application_1632745139502_0003/container_1632745139502_0003_01_000005/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1632745139502_0003/container_1632745139502_0003_01_000005 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.10.102 43227 attempt_1632745139502_0003_m_000000_3 5 1>/opt/module/hadoop-3.1.3/logs/userlogs/application_1632745139502_0003/container_1632745139502_0003_01_000005/stdout 2>/opt/module/hadoop-3.1.3/logs/userlogs/application_1632745139502_0003/container_1632745139502_0003_01_000005/stderr
[2021-09-27 20:26:35.632]Container killed on request. Exit code is 143
[2021-09-27 20:26:35.634]Container exited with a non-zero exit code 143.
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
在网上找到一个暂时的解决方法,就很怪;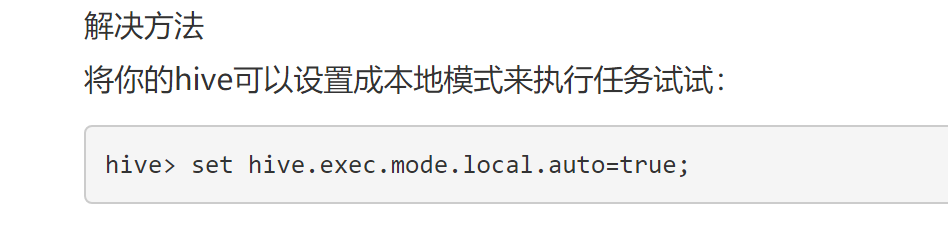
他是用本地模式来执行,是不是这样就违背了hadoop呢 ,我不知道为什么hadoop会内存不够,这部分我不知道。
也可以这样来控制内存用量

这样就是运行mapreduce了。 太多坑了。
学习时间:17:52到22:35