1. 调试模式和执行模式
1.1.调试模式
系统能够通过拖拽构造工作流。在编辑流的过程中,处于调试模式,为了保证快速地计算和显示当前结果(只显示前20个数据,可在调试的采样量中修改),此时,所有执行器都不会参与到工作流中,意味着数据库和数据表都不会被写入和更新。
(是否记得所有模块分为 生成,转换,过滤和执行四类?)
在调试时,从爬虫转换模块可能会请求web数据,为了提升性能,该模块对请求做了缓存。保证数据只需获取一次,如果想强制刷新数据,将从爬虫转换模块禁用,再启用,原始缓存数据就会被擦除。
 。
。
1.2执行模式
只有点击执行时,才会切换到执行模式。系统会切入到串行/并行模式,并行模式可以设置最大工作线程数,只有之前的工作线程完成工作,才会填入新的任务。
点击执行后,为了保证执行过程不受干扰,建议不要再修改各个模块的参数,此时刷新结果不可用。
当你想取消某一个任务,可以在任务管理视图的任务上,点右键选择取消任务即可。
2. 脚本系统
Hawk可以嵌入Python,以支持精细的控制,实现用图形界面难以操作的功能。Hawk使用IronPython作为解释器,其语法和Python3接近。
2.1 在工作流中使用脚本
我们用例子来讲解如何使用:
拖入生成区间数,添加一列,列名叫A,范围为1-20,间隔为1:
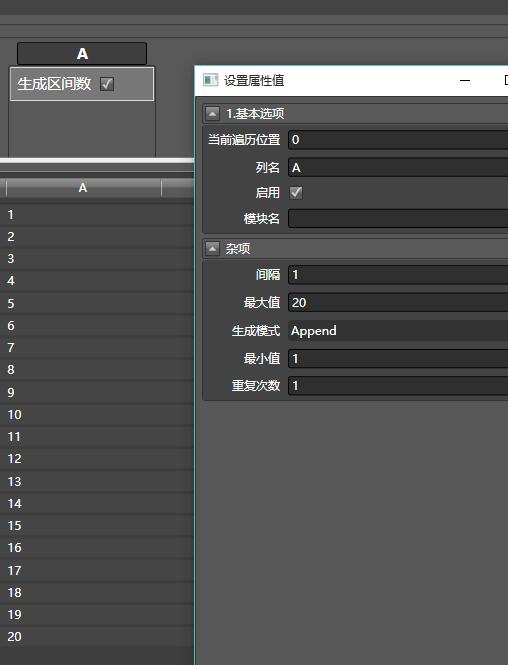
再拖入另外一个生成区间数,列名为B,范围1-40,间隔为2,注意生成模式为Merge。
此处介绍生成模式的区别:
- Merge:横向混合,形成另外独立的一列
- Append: 纵向添加,生成新的数据行,跟在后面
- Cross: 笛卡尔集,纵向组合,例如
(A,B) Cross (1,2,3) = A1,A2,A3,B1,B2,B3 - Mix:交叉混合:纵向组合,例如
(A,B,C) Mix (D,E,F)= A,D,B,E,C,F
基本上以上四种情况能足以应付绝大多数情形。
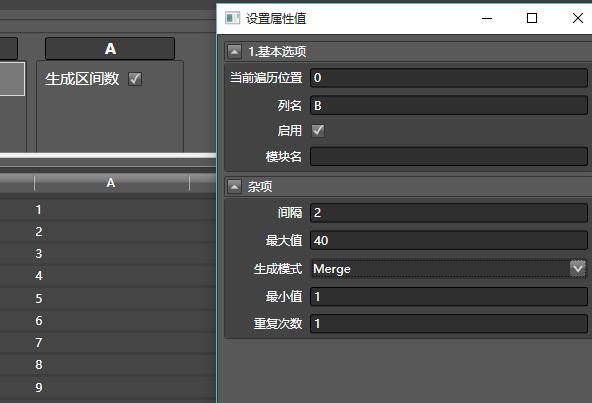
之后,将Python转换器拖入A列,设置如下:
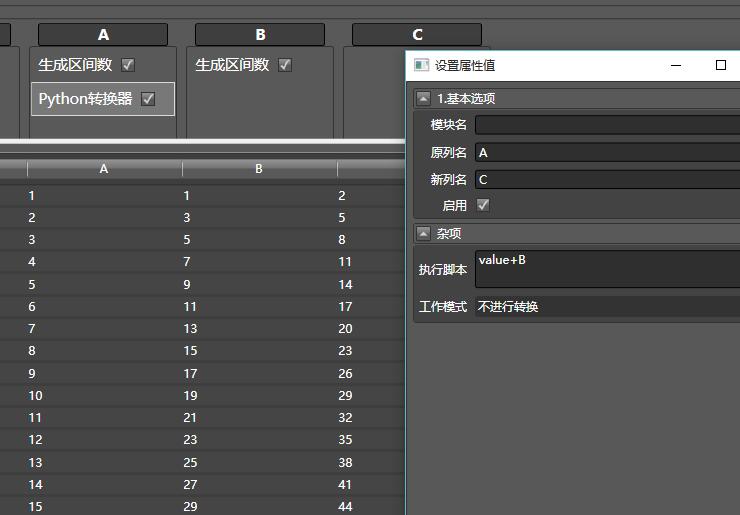
即可看到,多出了C列,且C=A+B。
脚本里,属性名可以直接作为变量使用,可以执行所有Python支持的操作。代码需要有返回值,但不需要return。拖入的列,除了可以用列名引用外,还可以使用value。当前的数据字典名称为data,因此上面的代码还可以写为:
data['A']+data['B']
值得注意的是,Python是强类型的语言,因此如果读入的是文本,上面的代码就会出错,应当改为:
int(A)+int(B)
2.2在加载任务时使用脚本
在定制抓取任务时,我们可以在界面上双击模块,修改工作流的参数,如采集不同城市的数据,之后再进行保存。
但这种做法比较麻烦,容易出错。因此,我们可以在工程文件的同一级目录放置Python脚本,在加载任务时,脚本会自动执行。
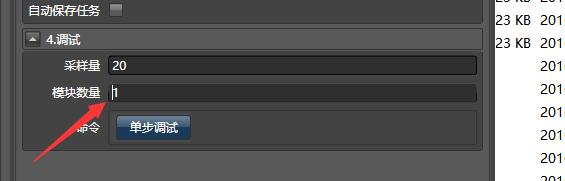
3.单步调试
已经编写的工作流,可能会因为某些外界环境的变化而出错,此时需要排除错误,我们可以使用单步调试:
还是上面A+B=C的例子:
在属性对话框,调试窗口里,填写模块数量为1,点击刷新结果,此时,系统会只执行第一步,显示A列。
点击单步调试,模块数量变为2,显示A和B列。
本质上,单步调试只是提取了工作流的一部分进行操作,你可以在单步调试中,拖入新的模块。模块会自动插入在工作流中间。
4.组合多个工作流
有时,不可能把所有的任务都在同一个工作流中实现。如果把工作流拆成不同的子流,那么就能方便重用和组合。
组合子模块的功能包含三类:子流-执行,子流-转换和子流-生成。为什么不包括子流-过滤?因为过滤操作通常比较简单,不需要子流实现。
- 子流-生成,作为生成器,一般在主流的开头位置。
- 子流-转换,可看成转换器,通常位于中间位置。
- 子流-执行:作为执行器,一般位于末尾。
值得指出,子流还可以调用其他的子流,形成树状的调用结构。
当加载一个任务时,该任务依赖的子任务也会自动加载。对子流的修改,也会传递到主流上。
(未完待续)