1.计算:序列的变换
写了这么久的程序,不少人肯定会疑问,计算的本质是什么?对一台图灵机来说,那就是无限长的纸带和能够自如移动的读写头,这太抽象了。我们今天尝试换一种方式去理解计算:
计算的本质是通过有限的步骤,读入数据,将一串序列,转换为另外一串序列,再将其输出
这样的概念甚为朴素,你想想看,计算机说白了,操作的不就是内存和外部设备吗?我们看看能从这个想法中探寻出什么。
从小学时候,我们就知道怎么去让高级的计算器帮助计算数学题:
(2+3)*20/(12+7)
我一直幻想,如果编程也能像上面这个式子一样简单该多好。既然有了定义序列的转换,那如何表示操作符呢?最简单的想法,把操作符放在序列的开头位置,而剩下的部分是该操作符的参数:
(Revert A,B,C) -> (C,B,A)
类似的,我们也可以有:
(+ 2 3) -> (5)
将运算符前置,避免了运算符优先级和可变参数的问题,反正一个括号里后面的元素都是前面操作符的参数。
将运算符也看成数据,这很容易理解,比如switch-case,传入不同参数,函数的行为就有所不同。不同的运算符决定了不同的处理流程。将它们都看成数据,你会看到更强大的表达能力。
听过那门古老人工智能语言Lisp的同学说,这种括号表达式,不就是Lisp的s-表达式么。确实如此,我们就将这种表达方式叫做Lisp。
2.将序列表示为树结构
扁平的记录方式是计算机最喜欢的,因为能方便快速地寻址;但如果能将数据分门别类进行组织,那更符合人的思考模式。因此我们引入更多的层级:
(+ (+ 2 3) (+ 5 6))
这样的层次结构,模拟了结构体和类。回到计算的本质这个问题,可以修改为:
计算是将一棵树,变换为另外一棵树。
当然,计算肯定是有目标的,一般来说,计算是将树不断地规约,让其变得越来越简单,直到不能更简单为止。
计算机初学者难于跨越的三个坎,分别是:
- 赋值模型
- 循环和递归
- 异步和并行
我们来看看,这三个坎如何用这个概念来理解。
3. 赋值模型
何为赋值?赋值就是将一个值赋给另外一个变量。最简单的概念比如:a=5
在执行到这句代码时,5这个值是确定的。
但如果值依然没有确定呢?比如a=x+y,可是此时x和y都不知道是多少。你点了点头,恩,这不就是数学里的方程嘛,到最后把x和y的值代入表达式就可以了。
这种先推导公式,直到最后代入实际值的赋值过程,其实是延迟求值的。用代码可以表述为:
C#版本:
a= ()=>return x+y; //传递lambda表达式
python版本:
a= lambda ():x+y; #传递lambda表达式
Lisp版本:
(let a (+ x y)) ;令a=x+y,却是延迟求值的,let是Lisp的一个关键字
什么意思?当任何时候你要求a值的时候,程序都是现做,给你把x和y加起来返回。这就像包子铺一样,人们都买新鲜的包子,隔夜包子都不好卖的!
我们可以将变量赋值看成一棵树的规约过程,看这个例子:
;Lisp代码:
(let timenow (+ (clock now) 1)) ;获取当前时间,再加一个小时
(compare timenow timenow) ;比较两个时间是否相等
好,那compare的结果是什么?
如果两个包子是同时做出来的,那就相等。其实这取决于解释器是怎么做包子的(也就是执行的策略):
- 从左到右求值:先计算第一个timenow,再计算第二个,最后传递给compare
- 延迟执行:先执行compare,再在其内部需要timenow时再对其求值
- 从右到左求值:先计算第二个,再计算第一个,最后传给compare
- 缓存:计算第一个timenow,发现两个参数名称一样,认为两个timenow一致,直接返回结果
四种策略,计算的结果都不一致!每种策略都有适用的范围。通过控制解释器,因为本质上规约是在树上进行操作的,到底是前中后序,甚至层序,还是你想到的其他规约方法,都可以自己定义。
这里讲了两种变量赋值的方式,而函数传参方式有四种,在备注中会提到。
4.如何表达数据结构?
我们学了很多种数据结构,队列,栈,数组,链表,树,图等等。它们形态各异。我们能否用通用的方法来表示它呢?
答案应该是二元组(car,cdr)。
队列和栈本来就是数组(也可以是链表),哈希表称为关联数组,自然也是能由数组构造的,数组和链表之间可以互相转换。
而链表就是二元组构成的链条,car代表该节点的值,cdr代表指向的下一个节点。

图可以转换为树,所有的树都能转换为二叉树。而二叉树的一个节点的car和cdr分别表示左右两个子节点。
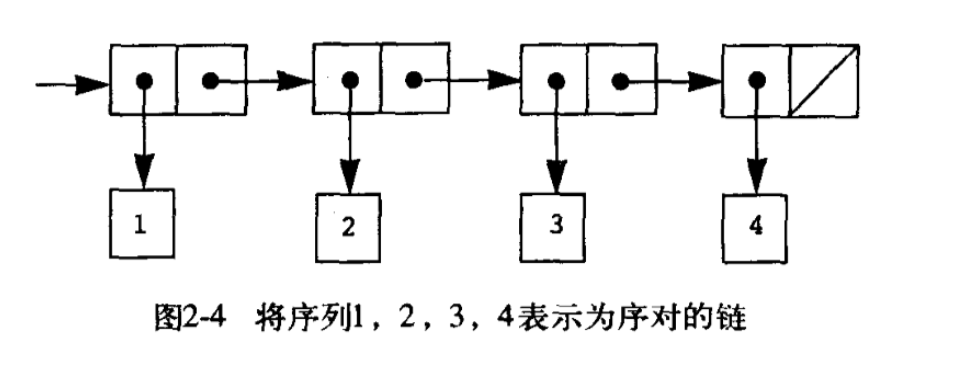
从上面的分析来看,我们确实能通过二元组的组合,定义绝大多数结构,如何定义二元组呢?
;Lisp版本:
(cons node1 node2) ;将node1和node2组合成一个二元组
(car pair) ;访问二元组pair的左值
(cdr pair) ;访问二元组pair的右值
为什么要去构造一个统一的结构来表示数据呢?因为这样让计算操作变得更加通用,只要三种运算符,cons,car和cdr,我们就能构造和访问绝大多数数据类型。
更重要的是,也许你创造出来的这个结构,它本身也许不存在!电脑里只有扁平的内存,那些数据结构,都是我们想象和建模的。通过对某种结构的一系列变换,这些变换将扁平的内存映射成了树,让它有了类似树的特性而已。
如果再加上寄存器和堆栈,我们就能实现一个上下文环境(env),进而环境可以为树规约提供参数值,规约后的结果也能影响环境,一个基本的计算体系就构建了出来。
5.编译和计算
程序的行为,分为编译期和运行期。绝大多数语言,都需要通过词法分析和句法分析,将源代码转换为抽象句法树(ast)。 除此之外,编译型语言还要生成中间代码,这一步可以通过对树结构进行后序遍历,生成三符号表达式,进而地翻译为机器码。而解释型语言则不需要中间代码生成,直接在树上操作即可。
那除了词法和句法分析,编译还做了什么事情呢?优化。
编译尽量提升运行时的速度,减少运行时的空间消耗。当然更多情况下是空间换时间。简单地说,编译就是对这棵树进行优化操作。编译优化应该包含几种策略:
- 将事先能计算的值提前计算 如看到(+ 2 3)直接转换为5,如果a=5, 那么(+ a b)就变换为 (+ 5 b);
- 将复杂的过程提前展开:如果有(complicatedFunc a b), 那么 complicatedFunc就会在编译期,被展开为它该有的形式,避免在运行时去查找其定义。
- 消除不必要的计算,编译时应该确定哪些变量是不需要的,进而对该符号进行剪枝。
熟悉函数式编程的同学会说,上一节的延迟计算,不就是高阶函数嘛!那么,函数作为一个对象,它存储在哪里,占用的是堆内存还是代码区?组合两个函数获得的“那个东西”,是否创造了新的函数?
函数是过程,但过程不一定是函数
打个比方说,定义两个子树: 它们的子节点都是a,b,只是父节点不同,分别是加法+和减法-;那么,如果把两个子树拼接起来,父节点是乘法*的话,那么我们就定义了新的计算:
result= (a+b)*(a-b)= > a^2-b^2;
我们并没有定义这个函数,却通过组合加法和减法和乘法,形成了一个平方差的过程。
从上面的例子可以看到,我们要定义任务时,定义函数只是其中一种手段。原因是这样好写,方便编译器优化和人类理解。但是,计算机其实不需要函数,它只关心任务怎么做,也就是计算的过程。
进一步地说,对于C#这样的静态语言,它是无法动态生成函数的,它只能重新组合函数,就像刚才组合二叉树一样(记不记得C#的ExpressionTree)? 对C来说,你可以用二叉树配合函数指针,实现和C#表达式树一样的功能,只是自己动手的工作量大一些。静态语言的函数存放在代码区,而代码区是不会改变的。
对Python来说,下面的代码确实动态创造了新的"函数":
code=
'''
def add(a,b):
return a+b;
'''
exec(code);
不过,对于解释型的动态语言来说,函数的定义大大弱化了。它已经远没有C里的过程体那么强硬而不可改变,Python编译器在执行上面的exec动态编译时,也是生成了一棵树。
所以,静态语言通过编译生成句法树(ast),动态语言在运行时生成ast;而Lisp,代码就是数据,它们都ast。总之,一个程序就是树,树的每个节点代表一个函数或过程名。
6.时间是个本质问题:流
我们再想一个问题,我们能处理无穷的序列吗?想象一个不停生产包子的包子铺,刚出笼屉就被买走了,我们称之为包子流,哈哈。
一个不停接受键盘命令的机器,处理的就是无穷流,它自己根本不知道该什么时候停止。如果数组是一个变量在空间维度的扩展,流就是在时间维度的扩展。所以,注意我们第一节用到的序列,这里,
序列=数组 或 流;
在包子铺窗口,每时你只能看到一个包子;但如果放在一个动态的时间角度,它其实沿着时间轴构成一个包子的序列(包子流)。看下面的代码:
#python代码
a='包子'
while(1):
print(a) #不停地打出包子,包子...
这是一个无穷的包子流,不断地输出包子,包子,包子...
再复杂一些,肉包子素包子交换销售:
index=0;
while(1):
if index%2==0:
print('肉包子')
else:
print('素包子')
index+=1;
#输出:肉包子 素包子 肉包子 素包子...
如果再复杂一些,老板要你先输出三个猪肉白菜,再输出两个牛肉大葱,再...
这就特别像刚开始学编程时,实现复杂逻辑用的状态机。你一定会很头疼switch-case里再嵌套if-else,while的这样的写法,老师教导我们应该将其解耦。但如果编译器能帮做到这件事该多好!
也就是说,你只负责生产空包子,后面有小妹A帮你给包子里填馅,后面还有小妹B帮你装袋子,每五个装一包。这样就构成了一条包子流水线,从此你的工作就轻松很多了。
如何用编程来模拟这些帮你打下手的小妹呢?
#python代码,定义两个函数
def generator(): #生成器,不断地输出原始的包子流
while(1):
yield '包子';
def map(items,func): #依次对包子加工,func从外部传入加工方法
for item in items:
yield(func(item));
def roubaozi(baozi): #将原始的包子加工成肉包子的函数
return '肉'+baozi;
map(generator(),roubaozi);
这样不就等价于刚才的那个函数,不停地输出肉包子这个序列吗?
那如果编译器更给力一点,将表达式倒过来写(我们习惯从左往右看),写成:
generator().map(roubaozi)
甚至
generator().map(func1).map(func2)...
这就构成了一个漂亮的流水线!
如果外面没有买包子的人了,这个流水线就自动停了,因为没有消费了。但如果又有人过来,流水线又开始生产,也就是按需消费。
如果用代码来表达,不论你用Python的生成器,还是C#的Linq,它们能从中断的地方恢复,看似神奇,本质在于它们被编译器重新编排在同一个函数里,使用着同样的堆栈和内存。但这种写法,给程序员提供了很多方便,是一个语法糖。
那流能做什么呢?
- 能截取流的一部分
- 两个流可以拼接,可以交叉,可以求笛卡尔集(参考备注)
- 流可以被过滤,被变换
那么,Lisp解释器是否也需要像Python编译器那样,去将一堆代码组合到一个函数里?答案是不需要。为什么?如果我们用递归定义的数据结构,配合递归函数,那么也能实现类似的功能,因为递归和循环是等价的,但递归能把函数描写地更加简便。具体的解释请参考附录
流的思路很清晰广泛,非常适合模块解耦,一个图遍历算法也能生成一个节点流,之后对节点的处理交给外界去负责,同样节点的处理模块也不关心遍历是深度优先还是广度优先的。
如果我说,流就是循环,流就是递归,你怎么看这个问题?
7.异步,多线程和运行
我们已经把程序员的前两个坎迈过去了,现在看看第三个坎:异步和多线程。
7.1 异步的原理
包子铺销量好啊!但是包子怎么也得15分钟才能蒸熟啊。于是外面的顾客在排队,你这个时候坐在蒸笼旁边发呆,老板娘肯定过来就给你一脚,干活去!
那怎么办,设个闹铃啊,到了十五分钟,出笼不就好了,这个空闲时间,你还能做点杂活。这就是异步的意义。一旦某个任务完成,通知你去做剩下的任务就好了,而这个剩下的任务,就是回调(callback)。
所以,异步就是,让主线程不阻塞能接着干别的活,当包子蒸完了再接着卖包子的意思。
这里有两个关键点,
- 线程不阻塞还能干别的活
- 本任务完成后,通知线程接着处理剩下的内容
先看第一个问题,不阻塞干别的活,这不就是多线程?异步就一定是多线程吗?不一定!那怎么能实现同时干两个活?下面是答案:
- 对于单线程系统,实现异步的前提是支持中断。为什么会有DMA控制器,网卡控制器?因为这些控制器就是个CPU,它就是协处理器,当完成自身任务后,通知主CPU执行,主CPU能做其他事情,这种方法比实现多线程效率更高,因为充分利用了协处理器的能力。在包子铺里,那个工作的蒸笼就是协处理器!
- 对多线程系统,可以用线程来模拟异步,如开子线程,子线程完成任务后通过信号量通知主线程。比如帮你蒸包子的小妹。
- 如果既没有中断也不支持多线程,那么异步是不可能的!
通常来说,计算密集型的是多线程的,IO密集型的是基于中断的。
8.2 异步的回调函数
对第二个问题,如何告诉主任务如何处理剩下的内容,这就需要回调函数。回调函数要写起来漂亮,实现起来优雅。但是像javascript用在web开发中,而网络环境中都要求异步,所以会看到那么多的回调函数,头都晕了。
//js代码:
function myFunction(param)
{
var http= new XMLHttpRequest();
http.onreadystatechange=function() //第一层回调
{
var http2=new XMLHttpRequest();
http.onreadystatechange=function() //第二层回调
{
...
}
}
//这个访问服务器的js代码,是基于中断还是多线程?
这段代码的意思是发出一个请求A,A获得回复后再发出请求B,B获得回复后再...于是回调函数一层套一层,看起来好不爽快。
如果能把回调函数使用地优雅一点就好了!
C# 5.0实现了这样的语法, 就是async和await关键字,比如下面:
#C#的示例代码:
Task<string> GetValueAsync(string value){
return Task.Run(()=>{
Thread.Sleep(1000); //模拟长时间操作
return "完成"+value;
});
}
public async Process(string value)
{
var result= await GetValueAsync(value); //优雅的异步调用,调用线程不会阻塞
Console.WriteLine(result);
}
看起来很high是吧,比js的回调好看多了!我们先想想,刚才的那段C#代码是基于中断还是多线程?显然是多线程嘛。可是哪来的多线程?
注意那段GetValueAsync函数,return Task.Run...这是个编译器语法糖,在.Net库里实现并创建了线程池,并将这个任务交给了它。而绝大多数语言是不包含这样的语法的,所以才会有那么多C/C++/Python异步库,它内部都使用了线程池和队列,但好像实现这样的语法是不可行的。
OK!如果是Lisp实现异步呢?这个依然取决于Lisp解释器的实现,如果你愿意,解释器可以随时调整树结构,完全可以将完成后的操作的函数节点挂接上去就好了。
8.3 多线程
当程序运行时,代码树的结构一般是不发生变化的。程序计数器(pc)记录了当前访问的节点。当涉及函数调用时,向树的子节点运动,并将之前的参数和环境压入运行栈,从函数调用中返回后,再将结果从栈中弹出。
过程是编译期的概念,活动是运行期的概念,活动是运行的过程。
对单线程来说,任何时刻,一个树节点只可能有一个线程在访问。但对多线程来说,每一个执行线程,对应一个独立的栈,不同的线程在同一棵树上进行遍历访问,形成了不同的活动
并行的本质就是同时有多个工作线程在同一棵树上进行规约操作。自然而然地,如果同时修改和读取共同的节点或环境,那么肯定就会出现数据争用,如果不加锁,就有可能产生错误。
函数式编程能够尽量避免多线程的问题,是因为其操作以递归为主,因此对环境的依赖变弱。而过程式语言特别强调环境,因此在多线程环境中就需特别注意。
9.总结
计算的本质是什么?图灵的定义肯定是最好的,但它难以被形式化地描述,将其表达为序列的变换,再具体为为树结构的变换,应该是个不错的解释。
进而,大神发明了Lisp语言,用以形式化地描述这种“树结构的变换”。因此本文的很多讲解都提到了Lisp。
针对流,异步和赋值模型的讨论,仅仅是个皮毛,特别希望能够抛砖引玉,有任何问题,欢迎讨论。
本文是笔者针对《计算机程序的构造与解释》的读书笔记。
10.备注
10.1 函数参数传递机制
函数参数传递,分为四种类型:
- 传值调用:最普通也是很多语言(C,JAVA)唯一的传递方式,C传指针也是传值调用,因为指针也是值
- 传名调用:函数式编程中的延迟求值,实现时可以分为宏替换和lambda表达式传递。
- 引用传递: Fortran语言唯一的传递方式,C++的引用传递(&), C#的ref关键字
- 复制传递:先将实参复制到函数中,执行完后再将其复制到函数外,C#的out关键字
任何一本编译原理的书都会讲解这四种求值方式,本文从略。只是不同语言的支持不一样,C#支持以上所有四种方式。
10.2 Lisp实现包子流
一个产生无穷的包子流的Lisp代码,我保证你一定能看懂:
(define generator (str) ;define是Lisp的关键字,定义 generator函数
(cons ;记不记得刚才生成二元组的cons?
(str generator(str)) ;递归调用
)
)
(define map (proc items) ;定义map函数,proc是加工方法,items是传入值
(if (null? items) ;如果值为空,就返回,nil代表空
nil
(cons (proc (car items)) ;分解这个二元组,并进行加工,再拼接起来
(map proc (cdr items))
)
)
)
(map (generator "包子") print) ;最终的调用函数
如果用Python实现类似的功能:
def generator(s):
return (s,generator(s));
def map(items,func):
if isinstance(items,tuple):
return (map(items[0]),map(items[1]));
else:
return func(items);
map(generator('包子'),print);
我们试图构造一个递归的元组,也就是(包子,(包子,(包子,(包子..)))),然后送入map递归处理,但是却悲剧地发现,第一个函数无法工作,它会无穷递归!因为Python的解释器是处于前面提到的第一种求值模式(先求参数,再传入函数中)的。由于无法修改Python解释器,因此这样的写法是不行的。
(有人可能提出,在generator中,改成return (i,lambda ():generator(i)),这其实也不可行)
从这个例子上我们能看出,一个能自由控制求值策略的解释器是多么有用。
10.3 非确定性计算?
求笛卡尔集,在《计算机程序的构造与解释》(SICP)中被称为“非确定性计算”,参考4.4章,但笔者认为这种描述并不妥当,这只是一种类似在矩阵中一行一行地搜索行为,和非确定性没有关系。
10.4 Lisp和语言设计
最有趣的是,不同语言为什么要那么设计,甚至有人说,其他语言都是Lisp的真子集。对Lisp来说,编译和运行的界限变得非常模糊。连GCC生成的中间代码,都是Lisp风格的。还有为什么《黑客与画家》为什么如此地推崇Lisp?
在我看来,像Lisp这样的语言,既不需要词法语法分析,也不需要代码生成,所以你可以用非常简单的代码(不到100行),实现一个Lisp解释器,从而自定义地控制求值策略。Lisp语言还支持定义宏,在运行期对树进行类似编译时的操作。因为运行期可以获得环境的更多参数,所以这种操作非常有效。绝大多数编译原理的技术,都能通过Lisp,以极低的成本去设计和实现。相比其他语言,Lisp拥有了直接和造物主对话的权限,一个能让你直接编写中间语言甚至机器语言的高级语言,不强才怪。
那为什么Lisp没有广泛地运用在商业环境中呢?很简单,它虽然太强大了,但却以难以阅读著称;设计解释器太容易了,所以方言特别多;能写出复杂的宏,从而让语言完全自定义。但这些,都与社会化的软件开发套路相悖。
所以,学习Lisp不见得要用在开发中,但它的思路和设计,却能极大地影响你对编程的认识。