protobuf协议研究
- 什么是protobuf
protocol buffer简称protobuf,是google开发的一种语言无关、平台无关、扩展性好的用于通信协议、数据存储的结构化数据串行化方法。其相关资料文档都可以在这找到https://developers.google.com/protocol-buffers
附:目前常见的数据序列化方法效率对比见这https://code.google.com/p/thrift-protobuf-compare/wiki/Benchmarking
- protobuf优缺点
优点:相对于xml,json等序列化协议,protobuf更加高效、灵活、简单,在时间解析和空间压缩方面比其他大多数协议高效很多;支持大数据量数据传输;可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。
缺点:由于protobuf序列化后的是二进制字节的数据,相对于与xml,json来说,视觉上不是那么友好;目前支持仅支持c++,java,python三种语言
- protobuf使用及消息结构
首先定义一个.proto文件,定义你需要的串行化的数据格式,这里定义为Person.proto,表示一个人的信息;
message Person {
required string name = 1;///sdfsfsdffds
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
repeated PhoneType pt = 7;
message PhoneNumber1 {
required string aaa = 1;
optional uint64 bb =2;
}
repeated PhoneNumber phone = 4;
repeated PhoneNumber1 phone1 = 6;
}
如你所见,protobuf文件看起来有类似于c++,什么int,enum,string;
protobuf消息结构
protobuf消息结构都已“message msgname”开头,其中msgname是你要定义的消息段名,这里为Persson;
接下来一般每一行都是类似于 “修饰词 数据类型 数据名字 = 序号 [default=默认值]”,
修饰词有required,optional,repeated三种,required表示该值是必须要传的,而且只能出现一个;optional该值可以有零个或一个,可以查询其存在与否;repeated该值相当于一个数组或有序列表,改值可为0个、1个、或多个,可以使用选项packed = true来进行高效的编码。
数据类型16种,其中基本数据类型15种加上message嵌套共16种;15种数据格式如下;根据需要选择相应的数据类型
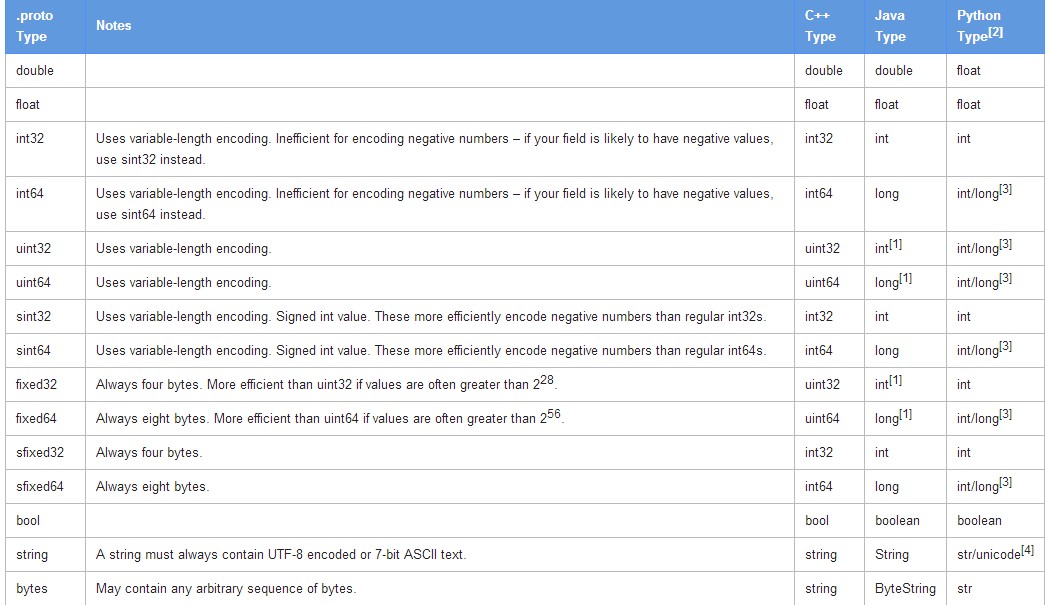
数据名字就是合法的关键字就行了
序号就是该字段在该消息中出现的顺序编号,可以从0~2^29-1次方之间(因为每个字段类型都由一个int32的key表示,其中类型字段占后3位,剩下2^29个编号,一般从1往下顺序开始,故最大可容纳2^29个字段)
[default=默认值]表示可以规定默认取值,该属性只对optional修饰的字段有效,表示如果没使用此字段但是规定了默认值,那么序列化的时候就按默认值序列化
- protobuf序列化原理
每一个消息字段序列化可以归结为key:value的配对,key可以唯一确定该字段类型,序号;value可以确定其值
按照 “修饰词 数据类型 数据名字 = 序号 [default=默认值]”格式定义来分析其key和value构成
key的构成: 由一个int32的4字节码表示;其公式为:(序号 << 3) | 字段归一类型;由varint编码序列化;字段归一类型如下所示
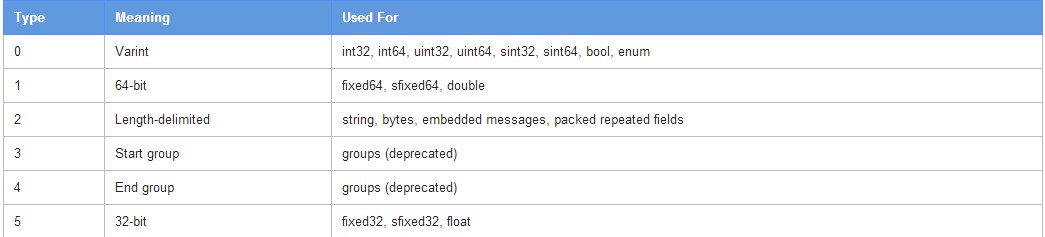
字段归一类型由3位表示,最多能表示8种类型,由上图知目前已使用6种类型(其中3,4已经在2.0以后弃用,其他不变):注意:在实际实现过程中,repeated fields字段并不是按照2算的,是按照其数据类型算的
如optional int32 test = 1; 反序列化之后是:0x08=0000 1000
如optional string test1 = 2; 反序列化之后是:0x12=0001 0010
value的序列化:采用little endian的存储方式
Base 128 Varints编码
varint编码使用一个字节或多个字节来表示一个整数,是边长字节编码,数越小,所以字节越少;每个字节都是varint类型,除了最后一个字节因为最有一个字节有空位;每个字节的低7位来存数据,最高位来表示前后两个字节是否有关联,为1表示后面的字节的数据和当前字节数据属于一个整体;
对于正数编码:如300,其二进制是100101100;其varint编码是1010 1100 0000 0010<= 010 1100 + 000 0010 <= 0010 1100 + 0000 0001 litter endian<= 1 + 0010 1100
对于负数编码,统一采用10个字节表示(最多能表示10*7=70位)32位和64位在最后一个字节上表现有所不同,对于32位的负数最后一个字节采用0x01填充,64采用0x0f填充
如-4,二进制补码为0xfffffffb;采用32位vartint编码为:0xfbffffffffffffffff01;采用64位编码为:0xfbffffffffffffffff0f
综上:varint适合于正整数编码,对于负数编码浪费空间
Signed Integers的ZigZag编码
对于有符号整数,采用ZigZag编码;其编码转换如下图

即是:正数的2倍,负数的绝对值2倍-1;按照可得其公式:对于32位(n <<1)^(n >>31),相应的解码公式是(n>>1)^(n&0x01);对于64位(n<<1)^(n>>63),相应的解码公式是(n>>1)^(n&0x01);
在protobuf协议中,对sint32,sint64位先采用zigzag编码, 然后在使用varint编码得到
相对int32,int64来説,负数能节省空间;
固定字节编码(fixed编码自己取名)
采用固定4个字节:fixed32,sfixed32,float
采用固定8个字节:fixed64,sfixed64,double
无符号整数usint编码
sint32采用varint编码,所不同的是,对于32位采用5个字节最后一个字节使用0x0f,对于64位采用10个字节,最后一个自己使用0x01
相对于纯int32来説,负数能节省空间;
string,bytes编码(官方手册上把repeated,embeded message也归为这一类,个人在2.5上实现经过实践,不是这样)
如repeated string test = 2;test被初始化为"testing";那么其序列化后的值是12 07 74 65 73 74 69 6e 67;其中前第一个字节就是key的编码;第二个字节是字符串长度的varint编码;后面7个字节就是字符串的ascii
- protobuf使用实例及数据结构分析
先去google开源项目上下载最新的protobuf编译器https://code.google.com/p/protobuf/downloads/list
使用如下命令把自己的.proto文件编译生成对应的语言源文件
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR path/to/file.proto
IMPORT_PATH 指定要编译的.proto文件目录,默认当前路劲为指定路径;可以使用-I=IMPORT_PATH来代替--proto_path=IMPORT_PATH;由于package指定的文件可以在多个地方,故--proto_path可以使用多次来指定多个目录;
生成的源文件有3种选择--cpp_out表示生成c++源文件;--java_out表示生成java源文件;--python_out表示生成python源文件;后面跟着生成文件存放的目录
最后一个参数表示要编译哪个.proto文件