这个是小森森中了ICCC的那篇论文,暂时还没有论文链接和代码链接,在这里替他总结一下。首先这篇论文是在MDNet的基础上实现的。
1) 题目:Learning Spatial-Channel Attention for Visual Tracking
2)主要贡献:
- 在MDNet的框架上增加了两个注意力模块来提取更好的特征,分别是一个空间注意力机制和一个通道注意力机制(MDNet对于特征图上每个特征点的关注程度是相同的,对所有通道也是同等对待的);
- 提出了一个新的损失函数:inter-instance loss,充分利用多域网络的特点(MDNet只注意在同一个域中区分目标和背景,忽略了不同域之间的目标之间的差异也会对特征的学习产生影响)。
3)介绍:
通常提高网络的辨别能力有两种方法,增加网络深度,如ResNet,或者增加网络宽度,如Inception。但这两种方法在跟踪问题中都不太适用,一是因为跟踪问题需要更多的目标位置信息,但深层网络只能得到更好的语义信息,二是无论加深还是加宽网络都需要增加很多计算量,不能满足跟踪应用中实时的要求。
MDNet的损失函数是针对同一域中的目标和背景的二分类交叉熵损失,忽略了不同域之间目标的差异性,当出现了和目标同一类别的物体时,跟踪性能将受到很大的影响。
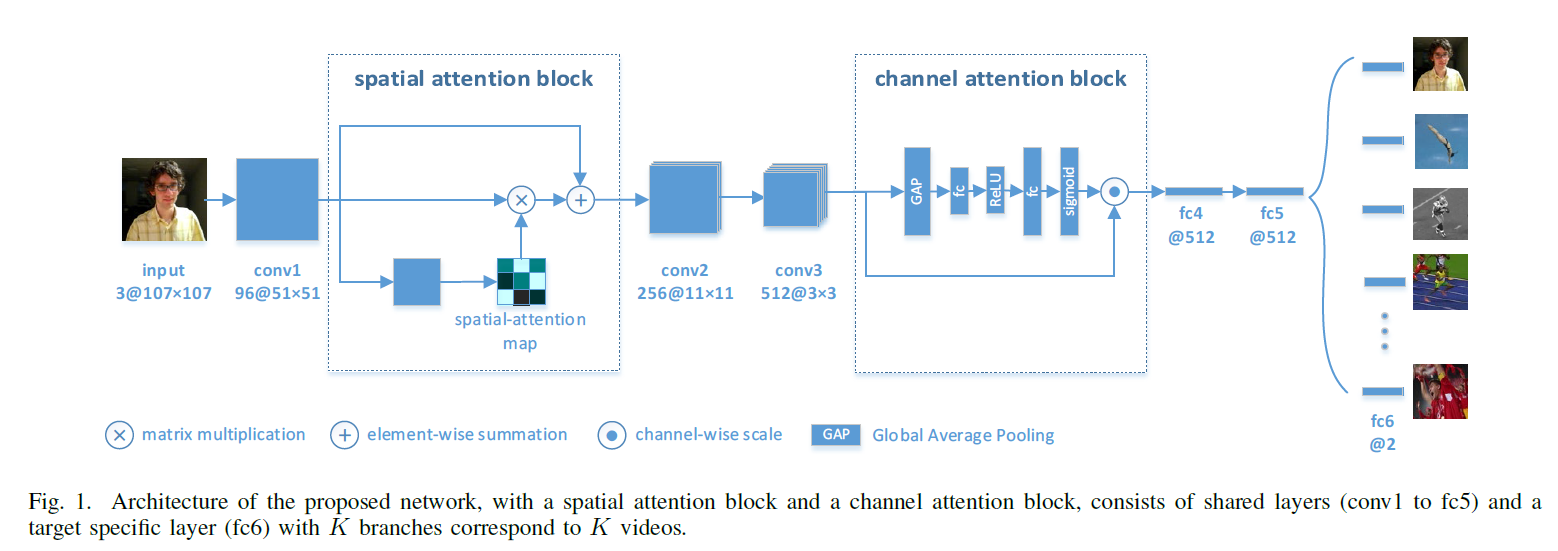
4)网络结构:
保留了MDNet网络结构中的3个卷积层(预训练的VGG-M)和3个全连接层的基本结构,前5层为共享层,最后一个卷积层为target specific layer。在第一个卷积层的ReLU后添加空间注意力模块,在第三个卷积层之后添加通道注意力模块。
输入为107*107的RGB图像,训练时输入的是在gt周围均匀采样的图片块,在线跟踪阶段输入的是上一帧确定的目标周围3D高斯分布采样的图片块。输入的图片块经共享层提取特征,最后一层给出一个正得分和一个负得分,图片块根据这个得分被判定为正样本或者负样本,即目标还是背景。
5)空间注意力:
卷积操作是一种局部操作,只关注于输入图片的一部分,为了增大感受野,这里采用空间注意力机制,其不会引入很多计算量,不影响算法速度。通俗来讲,空间注意力机制就是给特征图上不同的位置以不同的权重,因不同的位置在特征提取上的重要性是不同的。本文中采用的是经调整后的Non-local模块。
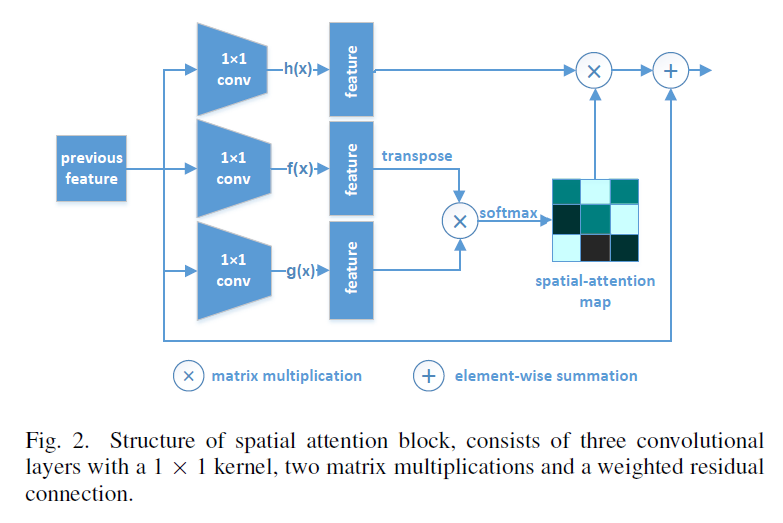
首先将输入特征图分别给三个1*1的卷积核的卷积层,进行语义转化(这个地方,小森森说是在对特征图进行人为操作之前都要对特征图进行这样一个语义转化),得到如下三个函数
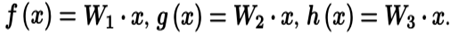
将f(x)和g(x)输出的特征图reshape一下,然后进行矩阵相乘,得到大小为WH*WH的特征图,经softmax之后得到空间注意力。Sq,p表示特征图上第q个位置和第p个位置之间的相关性,空间注意力就是由Sq,p构成的矩阵。

再令S矩阵与h(x)做矩阵乘法,乘以系数beta后跳连与特征图x相加,得到经空间注意力调整后的特征图。beta初始化为0,因为逐渐增加注意力会使特征更为有效。
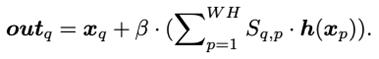
在此说明,注意力机制为一个模块,其可以添加到网络的任意部分,只是经过在本模型中添加到第一个卷积层后面的效果是最好的。因为到第3个卷积层得到的特征图太小了,其对应的是原图上比较大的一部分区域,这是在进行空间注意力的调整太过粗糙。
6)通道注意力:
通道注意力机制与空间注意力相似,就是给予不同的通道不同的重要性,即不同的权重。此处使用的通道注意力模块是一个SE-block。
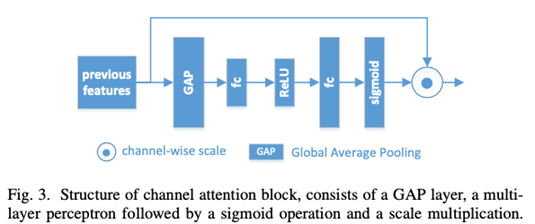
7)Inter-Instance loss:
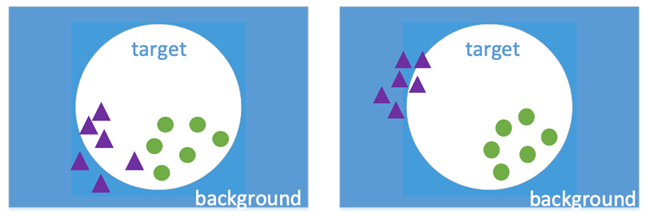
MDNet中由一个问题就是其只注重与区分当前序列的目标和背景,这样当背景中出现与目标同一类别的实例时,跟踪容易出现丢失的情况。为了解决这一问题,增加了一个多类别的交叉熵损失来区别不同序列中的目标,使其在特征域上距离更远,即特征更具分辨力。
如果只用binary cross-entropy loss来训练,可能使单个instances和他所在的视频的背景区分开,但实质上跟踪器很难将和他是同一类的实例区分开。如果用inter-instance loss来训练,可以有效利用起其他分支的实例,将他们作为当前视频的背景,能够更加关注同类别不同实例的区分。在特征域上距离更大有助于后续对目标和背景做分类。
这loss function能够用公式来表示。首先将当前视频的正样本输入多个分支计算得到不同分支的正得分s+,将这些正得分之间做一个softmax 操作得到p+,只有当前视频分支对应的正得分概率p+用来计算cross-entropy。其中引入了focal loss来作为每个部分的权重,减弱易分样本的作用,提高难分样本的作用。
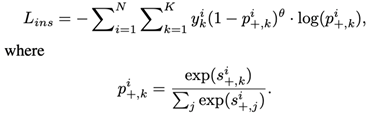
8)效果:
准确率提升1.9%,成功率提升1.6%。
在OTB2013和OTB2015上,分别于6个跟踪器做了比较,MDNet、ECO、ADNET、CREST、SiameseFC、CFNet。
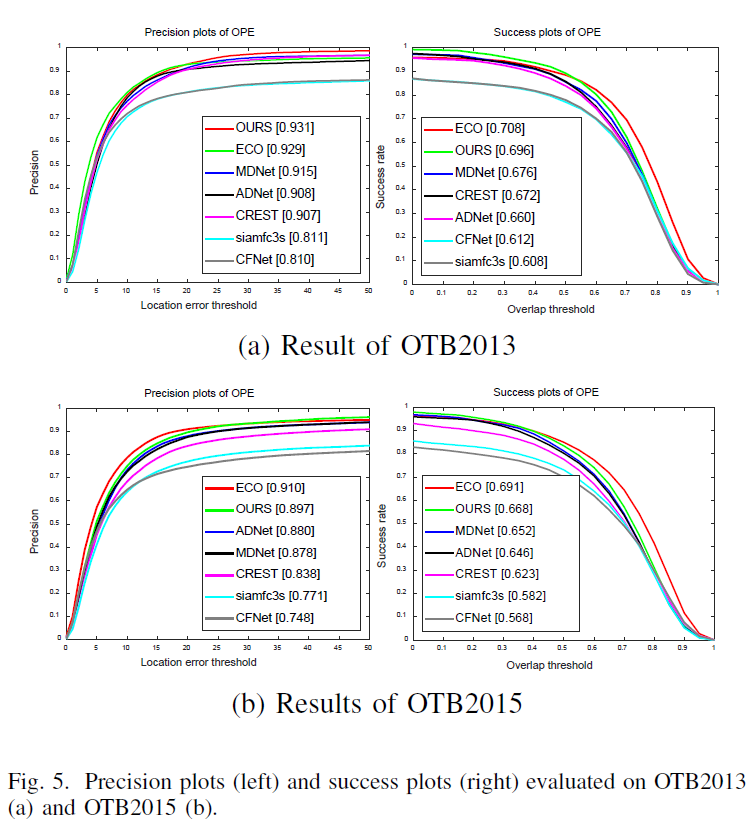
从图片中直观的也能看出,本文算法的跟踪效果还是不错的,画出的边界框更为精确。

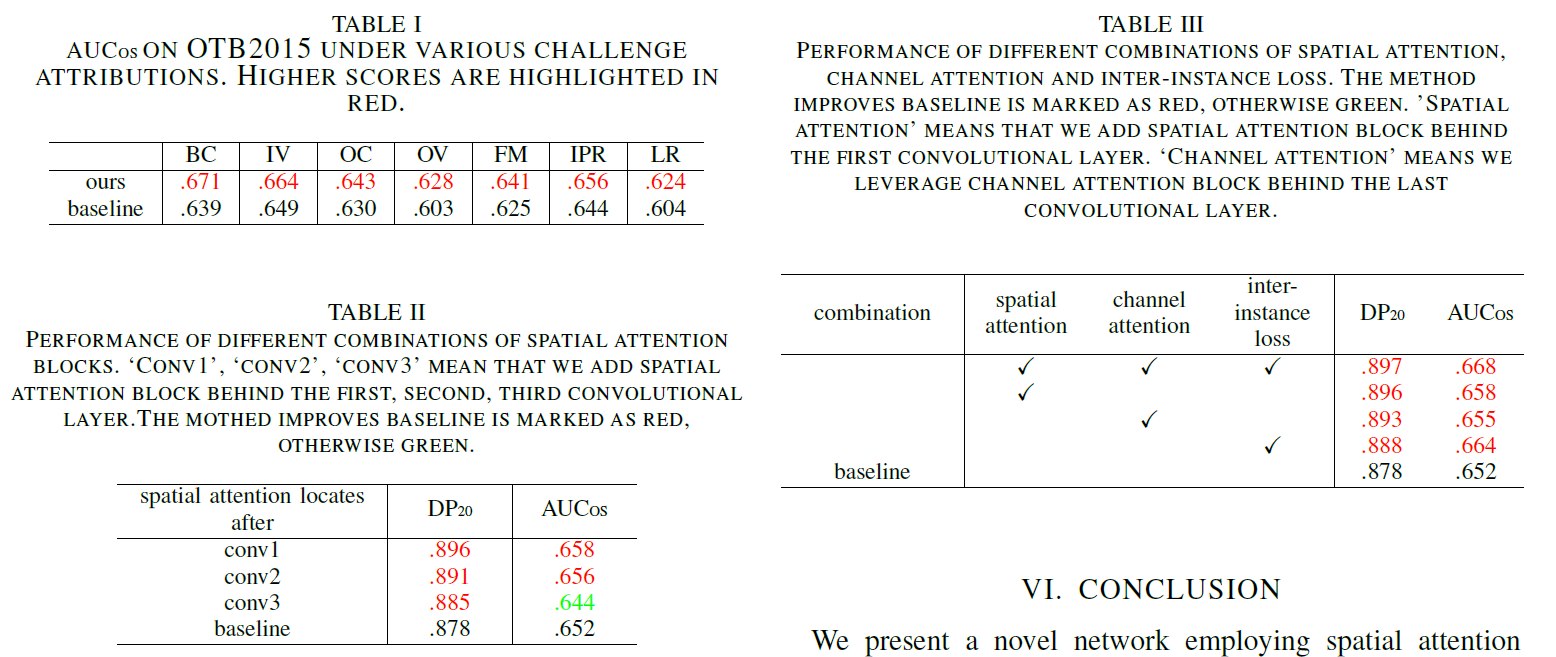
从表1可以看出,添加了注意力机制和inter-instance loss之后,算法性能在各种情况下都比MDNet表现更突出,证明注意力机制确实能帮助跟踪器更好的捕捉目标,防止丢失。
从消融实验中可以看出,每一部分对算法性能都是由贡献的,全部综合起来的贡献是最大的。表2是空间注意力机制放在不同卷积层后面的效果,可以看出在第3层后面的效果是最差的,这种现象的原因是第三个卷积层的输出特征图太小了。
9)Q&A:
我在presentation,被问到这样一个问题,就是为什么在空间注意力模块使用的都是卷积层,而通道注意力模块里使用的确实全连接层?
我当时是随便胡诌的,现在来说的话,在功能上卷积层能实现的全连接层都可以实现,但是卷积层的参数更少,而且不限制输入的特征图的大小。而全连接层是具有全局感受野的,在通道注意力模块中,我们需要得到的是每个通道的权重,这其实是需要包含全局信息的。