第七周作业
1.进程描述符task_struct数据结构(一)
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
struct task_struct数据结构很庞大
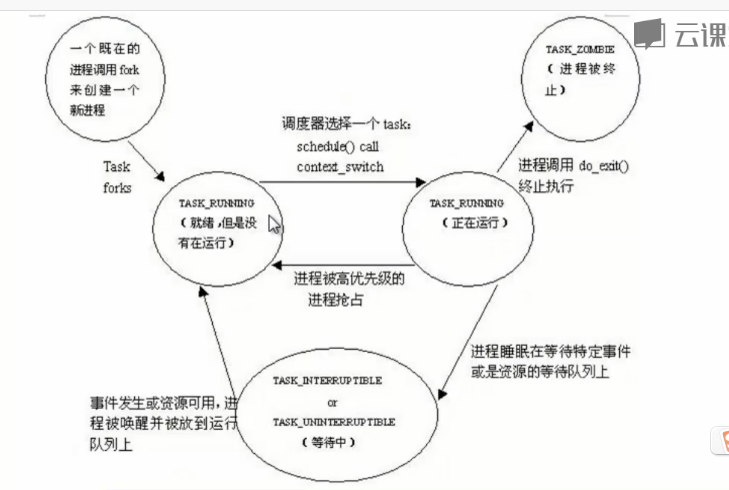
Linux进程的状态与操作系统原理中的描述的进程状态似乎有所不同,比如就绪状态和运行状态都是TASK_RUNNING,为什么呢?
进程的标示pid
所有进程链表struct list_head tasks; 内核的双向循环链表的实现方法 - 一个更简略的双向循环链表
程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
进程处于内核态时使用,不同于用户态堆栈,即PCB中指定了内核栈,那为什么PCB中没有用户态堆栈?用户态堆栈是怎么设定的?
内核控制路径所用的堆栈很少,因此对栈和Thread_info来说,8KB足够了
struct thread_struct thread; //CPU-specific state of this task
文件系统和文件描述符
内存管理——进程的地址空间
Linux内核状态转换图:
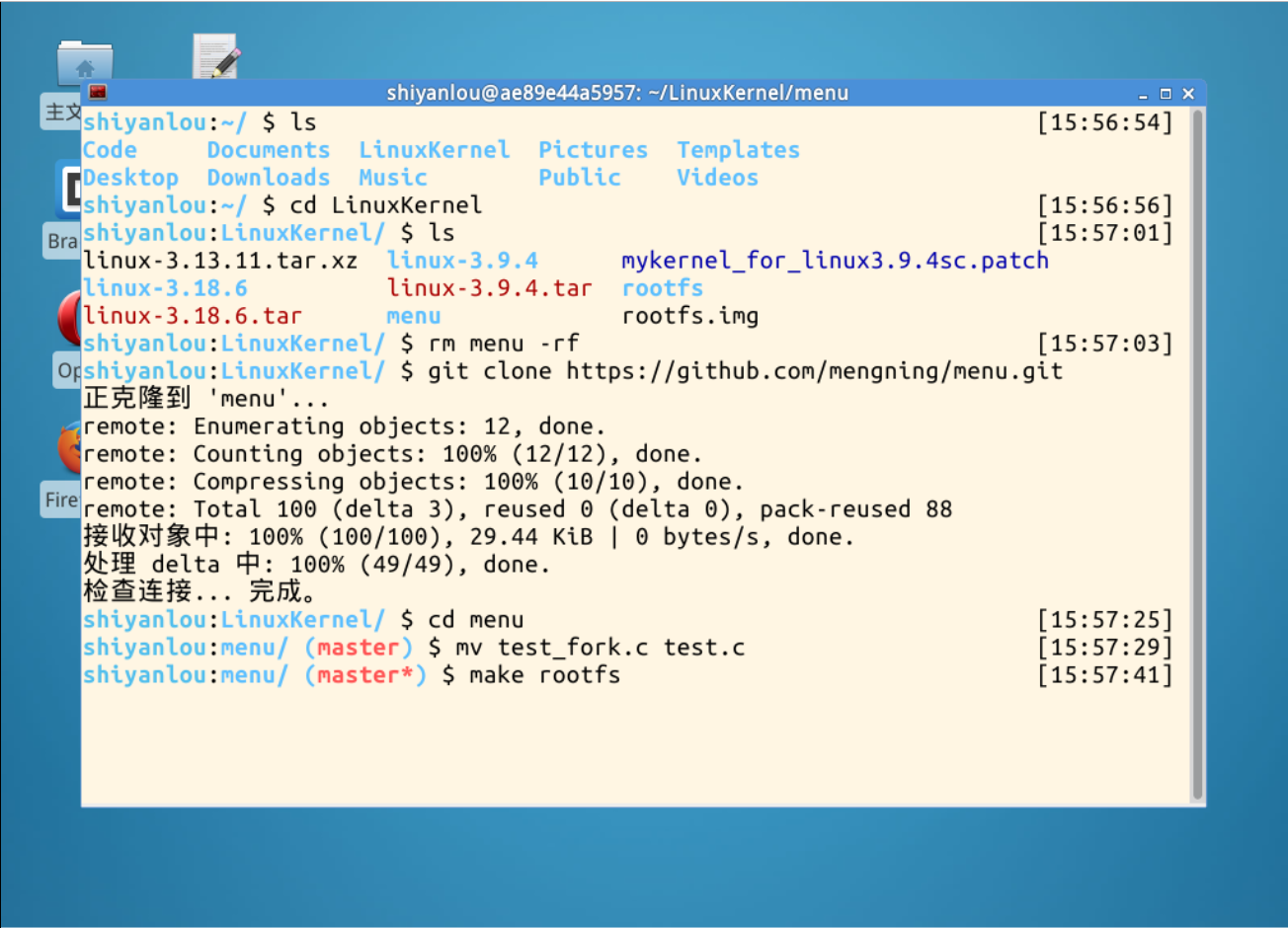
复制menu代码到最新版本,使用make rootfs,用help进行查看,添加进新的fork命令
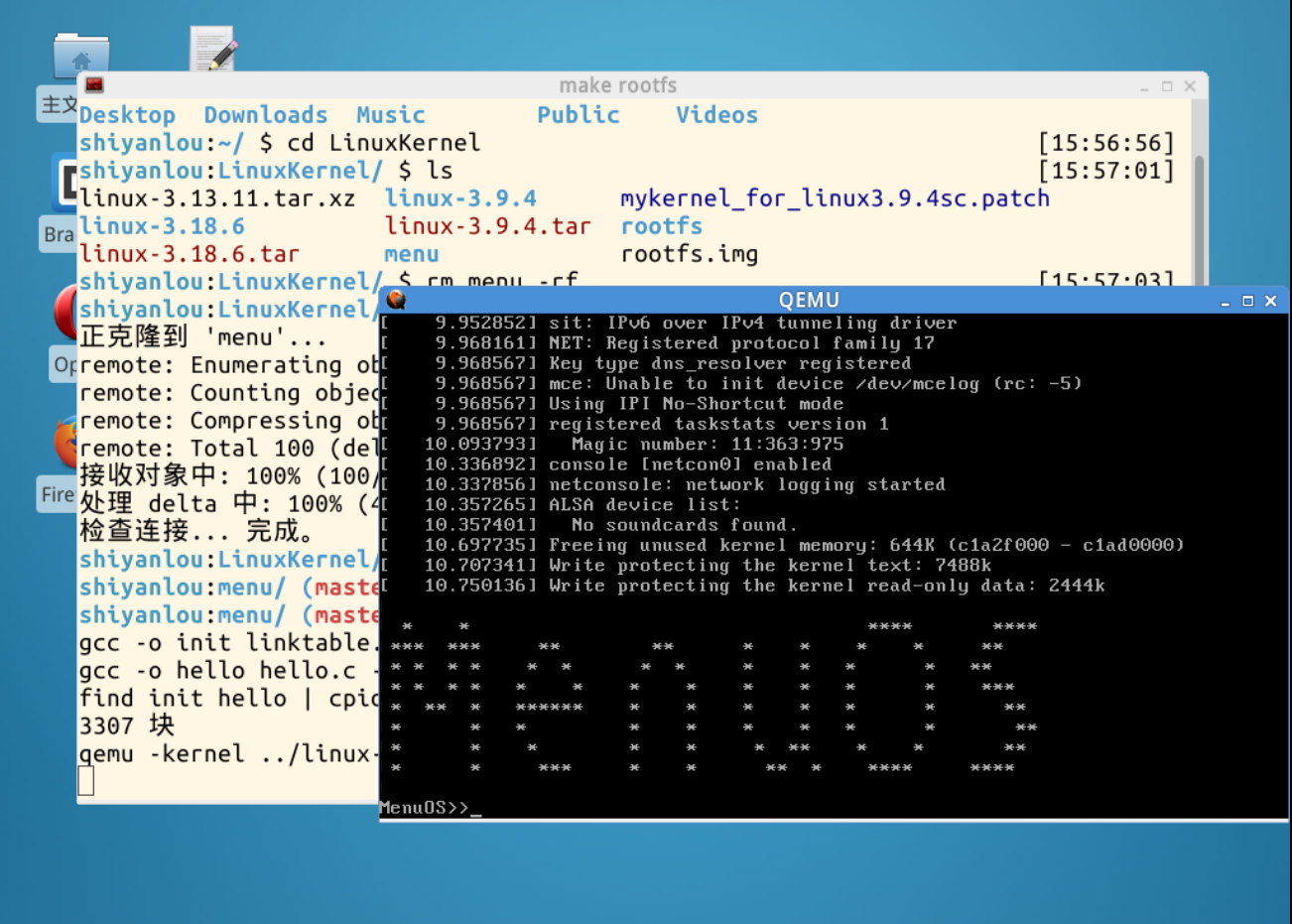
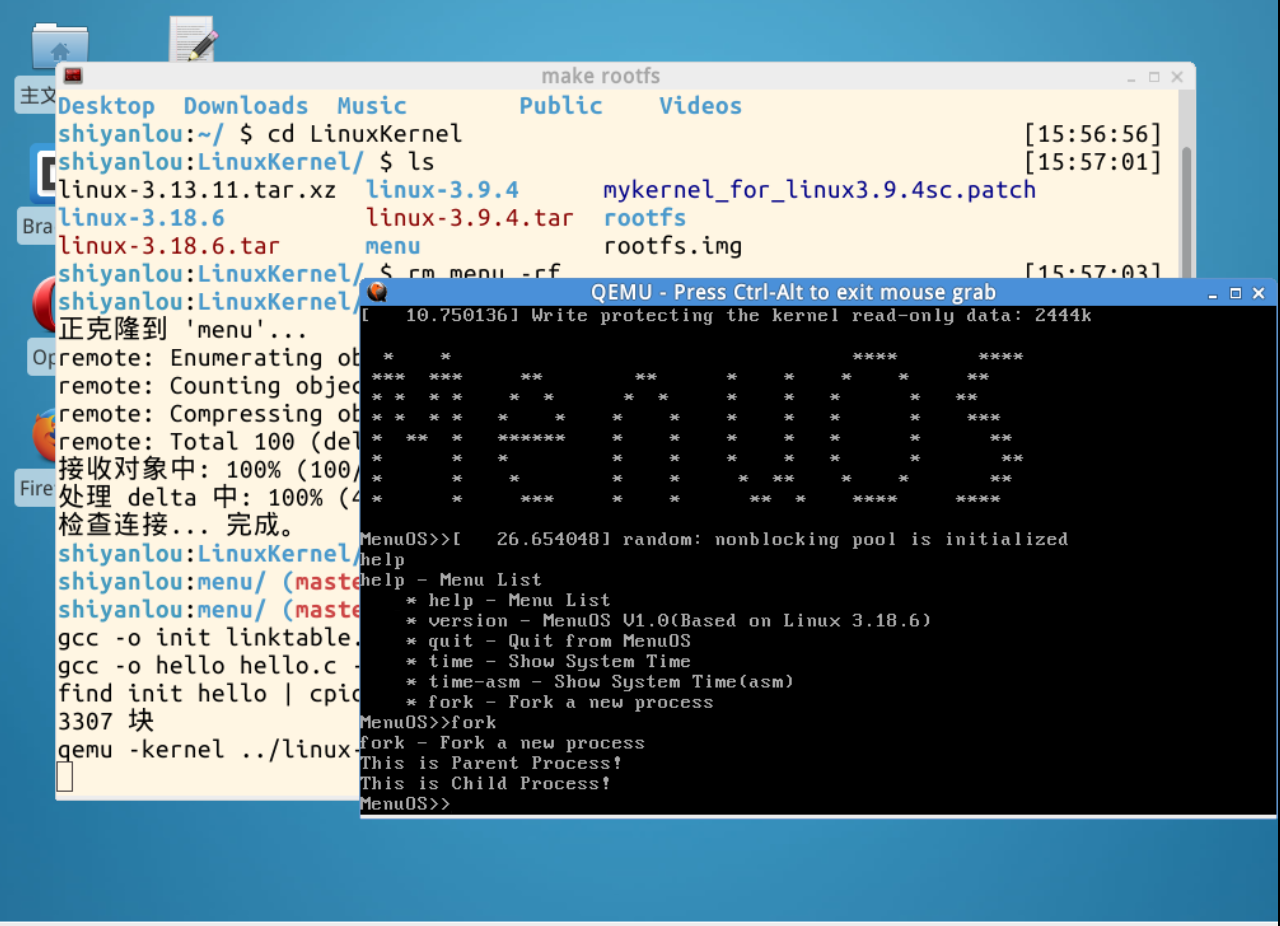
内核正常编译,能够查看到正常的menous,查看到新的fork命令
另开一个terminal,进行gdb的打开
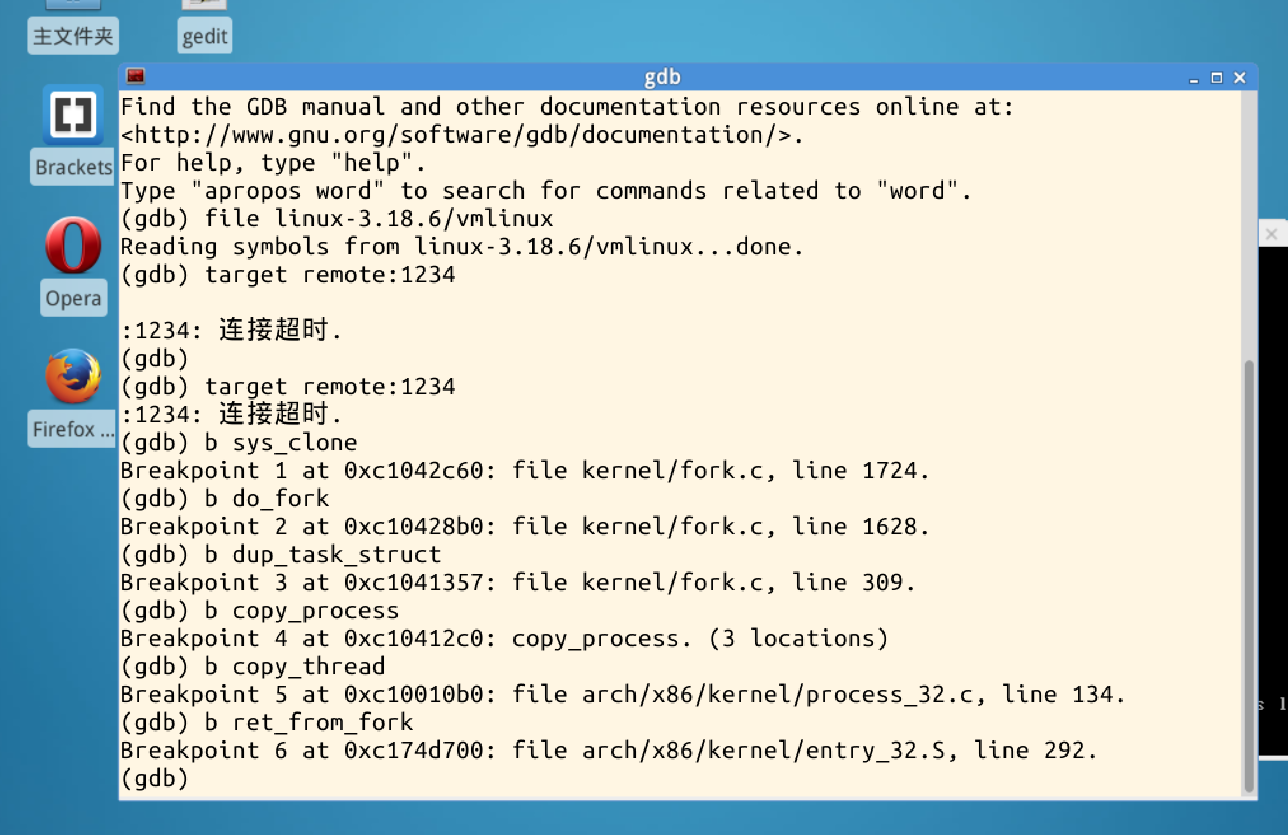
在gdb中使用
file linux-3.18.6/vmlinux
target remote:1234
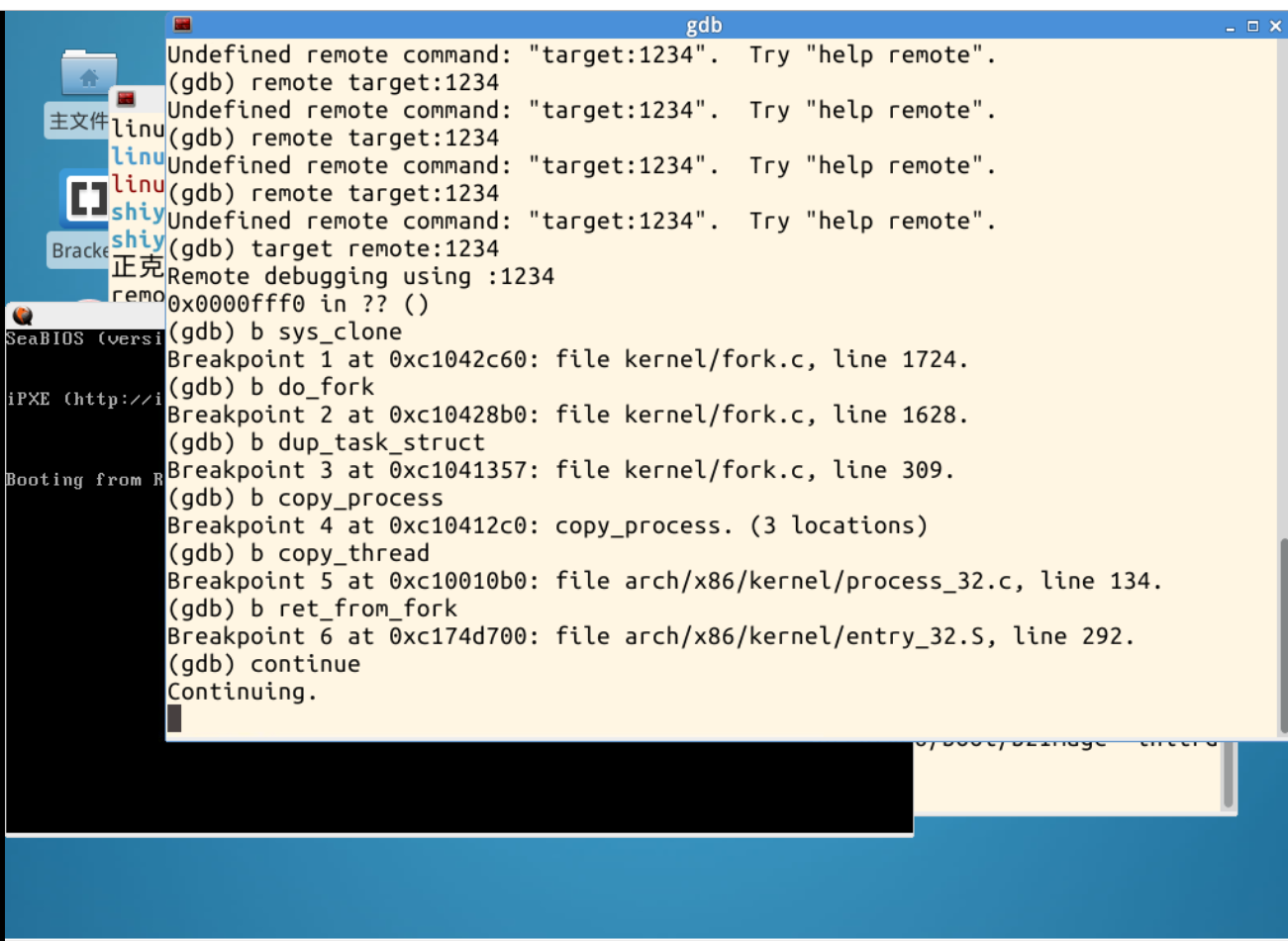
对内核当中的sys_clone,fork,dup_task_struct,copy_thread,copy_process等函数进行端点设置
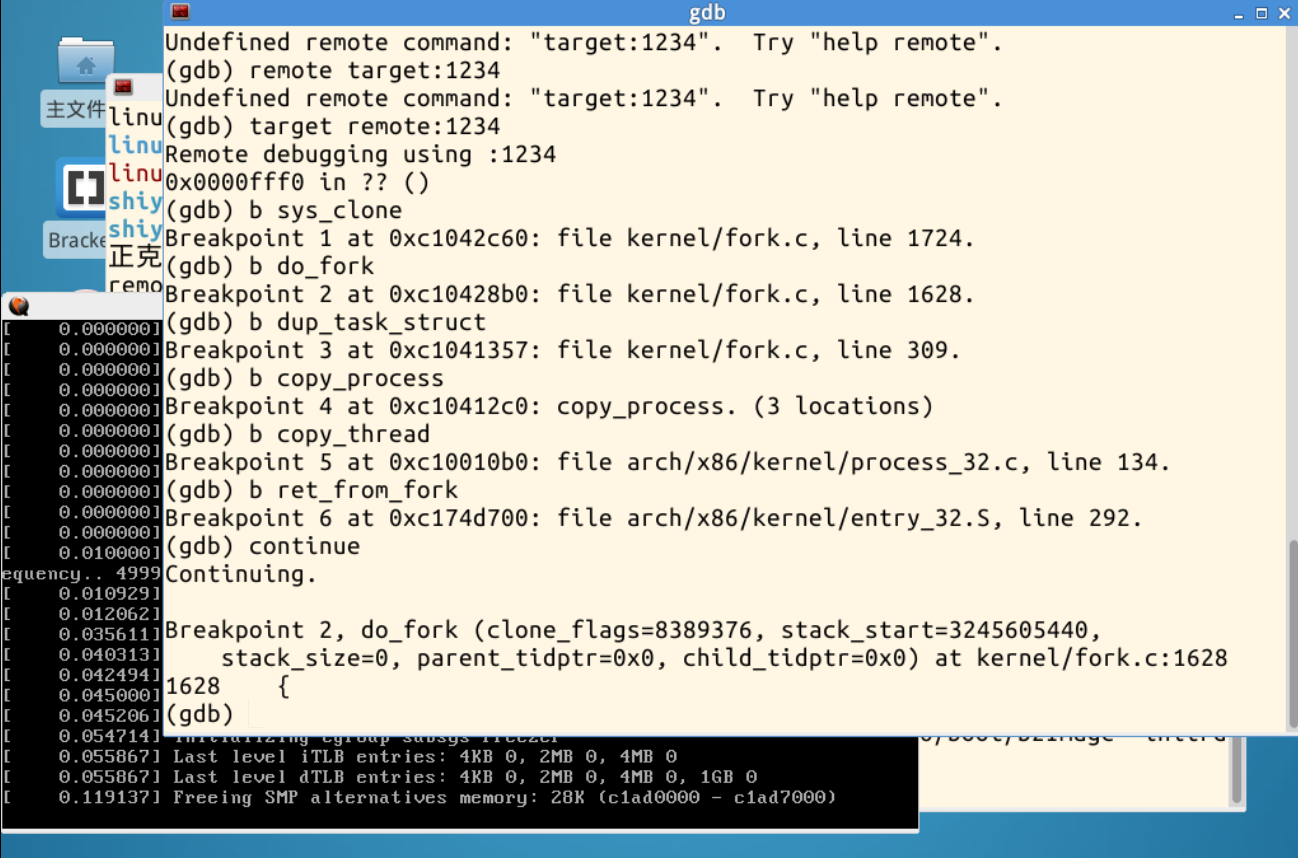
进行continue查看内核函数具体
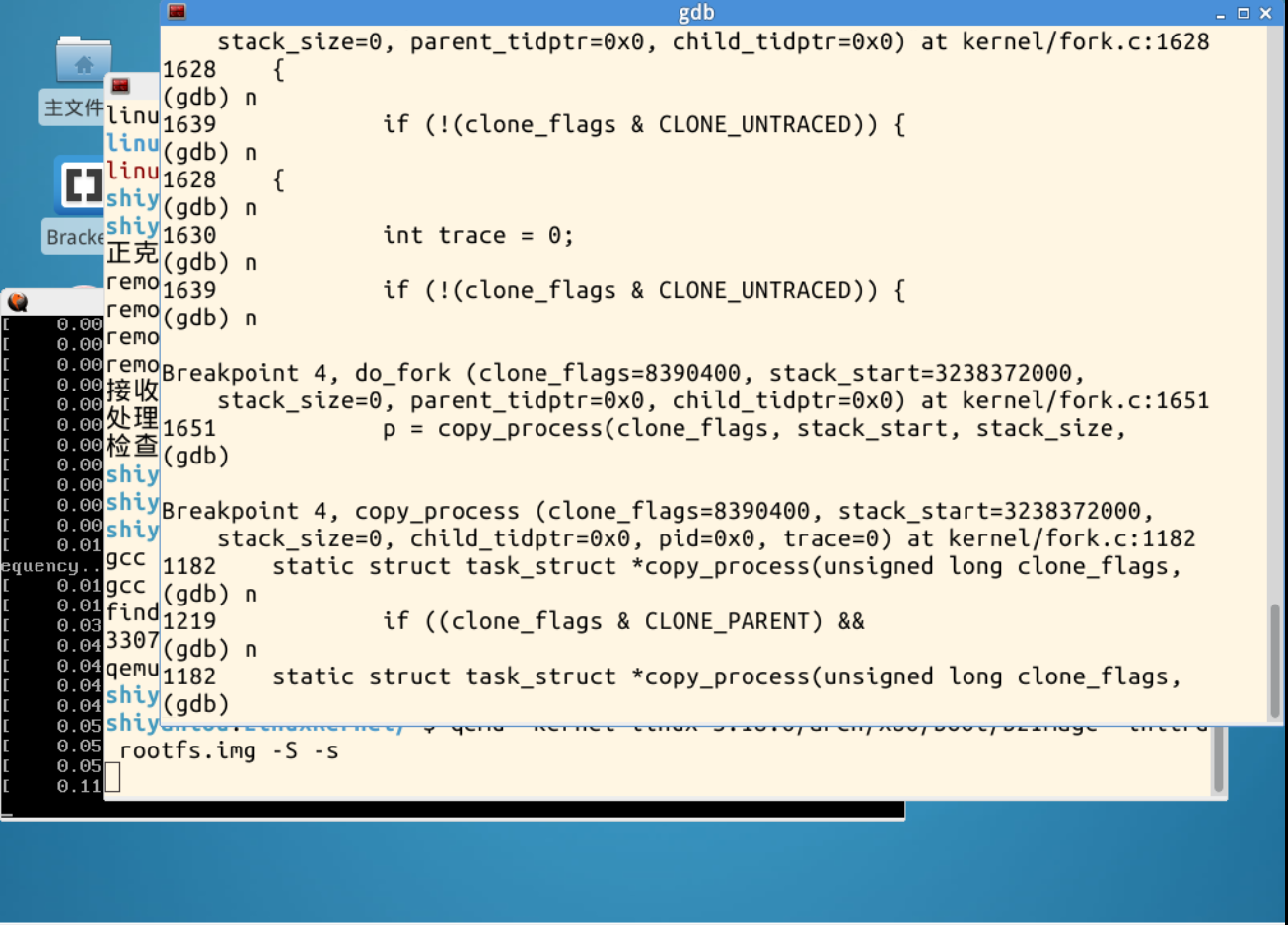
系统调用内核处理函数sys_fork、sys_clone、sys_vfork
理解如下:
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建,do_fork完成了创建中的大部分工作,该函数调用copy_process()函数,然后让进程开始运行。copy_process()函数工作如下:
1.调用dup_task_struct()为新进程创建一个内核栈、thread_info结构和task_struct,这些值与当前进程的值相同
2.检查
3.子进程着手使自己与父进程区别开来。进程描述符内的许多成员被清0或设为初始值。
4.子进程状态被设为TASK_UNINTERRUPTIBLE,以保证它不会投入运行
5.copy_process()调用copy_flags()以更新task_struct的flags成员。表明进程是否拥有超级用户权限的PF_SUPERPRIV标志被清0。表明进程还没有调用exec()函数的PF_FORKNOEXEC标志被设置
6.调用alloc_pid()为新进程分配一个有效的PID
7.根据传递给clone()的参数标志,copy_process()拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间等
8.最后,copy_process()做扫尾工作并返回一个指向子进程的指针
总结:
- Linux通过复制父进程来创建一个新进程,通过调用do_fork来实现
- Linux为每个新创建的进程动态地分配一个task_struct结构.
- 为了把内核中的所有进程组织起来,Linux提供了几种组织方式,其中哈希表和双向循环链表方式是针对系统中的所有进程(包括内核线程),而运行队列和等待队列是把处于同一状态的进程组织起来
- fork()函数被调用一次,但返回两次