==既比较地址又比较值,.equals()只比较值
java中一共分为8种基本数据类型:byte、short、int、long、float、double、char、boolean
java为每种基本类型都提供了对应的封装类型,分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean。引用类型是一种对象类型,它的值是指向内存空间的引用,就是地址。
整型byte、short、int、long的默认值都为0,浮点型float、double的默认值为0.0,boolean默认值为false,char默认值为空。对应的包装类型默认值都为null。
hashcode不等,equals一定不等,则无需比较equals,提升效率。hashcod相等,equals可能相等。
对象的初始化过程
Person p = new Person("zhangsan",20);
1、因为new用到了Person.class。所以会先找到Person.class文件并加载到内存中。
2、执行该类中的static代码块(静态代码块),如果有的话,给Person.class类进行初始化
3、在堆内存中开辟空间,分配内存地址
4、在堆内存中建立对象的特有属性,并进行默认初始化
5、对属性进行显示初始化
6、对对象进行构造代码块初始化
7、对对象进行对应的构造函数初始化
8、将内存地址付给栈内存中的p变量
- Thread.sleep(long millis),一定是当前线程调用此方法,当前线程进入阻塞,但不释放对象锁,millis后线程自动苏醒进入可运行状态。作用:给其它线程执行机会的最佳方式。
- Thread.yield(),一定是当前线程调用此方法,当前线程放弃获取的cpu时间片,由运行状态变会可运行状态,让OS再次选择线程。作用:让相同优先级的线程轮流执行,但并不保证一定会轮流执行。实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。Thread.yield()不会导致阻塞。
- t.join()/t.join(long millis),当前线程里调用其它线程1的join方法,当前线程阻塞,但不释放对象锁,直到线程1执行完毕或者millis时间到,当前线程进入可运行状态。
- obj.wait(),当前线程调用对象的wait()方法,当前线程释放对象锁,进入等待队列。依靠notify()/notifyAll()唤醒或者wait(long timeout)timeout时间到自动唤醒。
- obj.notify()唤醒在此对象监视器上等待的单个线程,选择是任意性的。notifyAll()唤醒在此对象监视器上等待的所有线程。
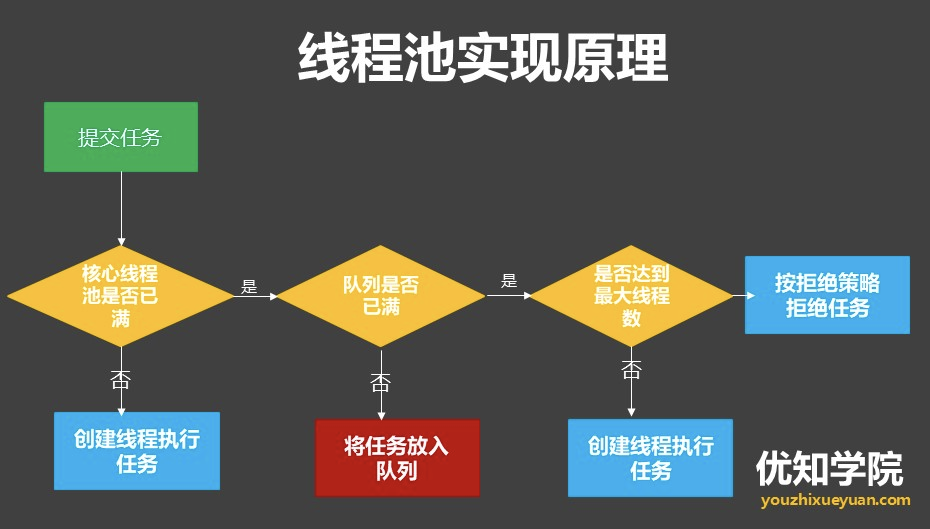
常见的5种线程池分别是:
1、FixedThreadPool,它的核心线程数和最大线程数是一样的,可以把它看成是固定线程数的线程池;
2、CachedThreadPool,可以把它叫做可缓存线程池,它的特点是线程数可以持续增加(理论最大可达Integer.MAX_VALUE=2^31-1);
3、ScheduledThreadPool,它支持定时或周期性的执行任务,有3个方法可以灵活的执行频率配置参数;
4、SingleThreadExecutor,它会使用唯一的线程去执行任务,适用于所有任务都需要按照被提交的顺序依次执行的场景;
5、SingleThreadScheduledExecutor,它和SingleThreadExecutor有些类似,它的核心线程数是1,但是最大线程数是Integer.MAX_VALUE。
ThreadPoolExecutor:
- corePoolSize: 线程池核心线程个数
- workQueue: 用于保存等待执行任务的阻塞队列
- maximunPoolSize: 线程池最大线程数量
- ThreadFactory: 创建线程的工厂
- RejectedExecutionHandler: 队列满,并且线程达到最大线程数量的时候,对新任务的处理策略
- keeyAliveTime: 空闲线程存活时间
- TimeUnit: 存活时间单位
拒绝策略: - AbortPolicy(被拒绝了抛出异常)
- CallerRunsPolicy(使用调用者所在线程执行,就是哪里来的回哪里去)
- DiscardOldestPolicy(尝试去竞争第一个,失败了也不抛异常)
- DiscardPolicy(默默丢弃、不抛异常)

volatile是轻量级同步机制。在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,是一种比synchronized关键字更轻量级的同步机制。
保证内存可见性,禁止指令重排(执行顺序)
synchronized和ReentrantLock等独占锁就是悲观锁
乐观锁适用于多读的应用类型,这样可以提高吞吐量,在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。
synchronized和volatile的完美配合,便实现了线程安全的双检锁单例模式。
为了能让后继节点获取到其前驱节点,同步队列便设置为双向链表,而等待队列没有这样的需求,就为单链表。
Java引用:强 软 弱 虚
强:只要引用存在,垃圾回收器永远不会回收
软:非必须引用,内存溢出之前进行回收
弱引用 是在第二次垃圾回收时回收,短时间内通过弱引用取对应的数据,可以取到,当执行过第二次垃圾回收时,将返回null。
虚引用 是每次垃圾回收的时候都会被回收,通过虚引用的get方法永远获取到的数据为null,因此也被成为幽灵引用
泛型:
最后看一下什么是PECS(Producer Extends Consumer Super)原则,已经很好理解了。
Producer Extends 生产者使用Extends来确定上界,往里面放东西来生产
Consumer Super 消费者使用Super来确定下界,往外取东西来消费
1、频繁往外读取内容的,适合用上界Extends,即extends 可用于的返回类型限定,不能用于参数类型限定。
2、经常往里插入的,适合用下界Super,super 可用于参数类型限定,不能用于返回类型限定。
3、带有 super 超类型限定的通配符可以向泛型对象用写入,带有 extends 子类型限定的通配符可以向泛型对象读取;以泛型变量为参数(void set(T t))和以泛型变量(T get())为返回
如果是继承基类而来的泛型,就用 getGenericSuperclass() , 转型为 ParameterizedType 来获得实际类型
如果是实现接口而来的泛型,就用 getGenericInterfaces() , 针对其中的元素转型为 ParameterizedType 来获得实际类型
我们所说的 Java 泛型在字节码中会被擦除,并不总是擦除为 Object 类型,而是擦除到上限类型
能否获得想要的类型可以在 IDE 中,或用 javap -v <your_class> 来查看泛型签名来找到线索
类加载:
类加载有三种方式:
1、命令行启动应用时候由JVM初始化加载
2、通过Class.forName()方法动态加载
3、通过ClassLoader.loadClass()方法动态加载
forName和loaderClass区别
-
Class.forName()得到的class是已经初始化完成的。 -
Classloader.loaderClass得到的class是还没有链接(验证,准备,解析三个过程被称为链接)的。
三种类加载器,引导(启动)类加载器,扩展类加载器,系统类加载器(ClassLoader.getSystemClassLoader)

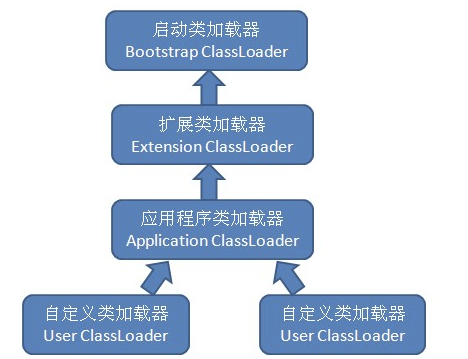
双亲委派模式的好处就是Java类随着它的类加载器一起具备一种带有优先级的层次关系,通过这种层级关系可以避免类的重复加载。安全,Java核心API中定义类型不会被随意替换。
-系统类防止内存中出现多份同样的字节码
-保证Java程序安全稳定运行
打破了双亲委派:
对于自己加载不了的类怎么办,直接用线程上下只要继承ClassLoader来重写findClass。如果想打破双亲委派,也要重写loadClass方法了,做到不委派
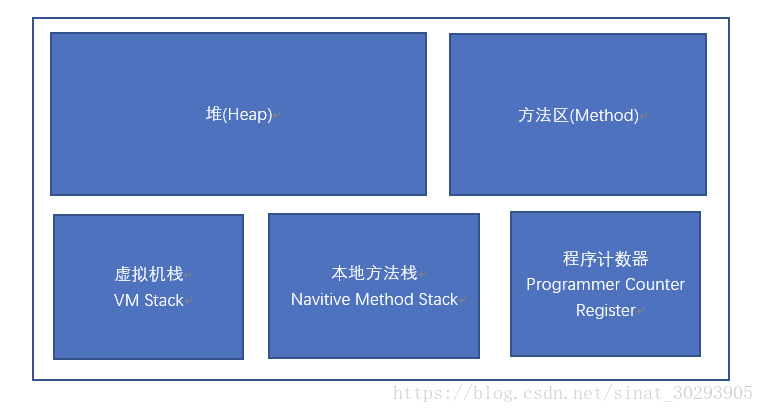

堆(GC区),方法区 线程共享
虚拟机,本地方法,程序计算器 线程私有
永久代 jdk1.8 后 元空间:
1、字符串存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
4、Oracle 可能会将HotSpot 与 JRockit 合二为一。
类加载的过程包括了加载、验证、准备、解析、初始化五个阶段。
GC:
标记:
Java1.2之前主要通过引用计数器来标记是否需要垃圾回收,而1.2之后都使用根搜索算法来收集垃圾
1.引用计数器算法 对象相互引用时候无效
2.根搜索算法(GC ROOT)
回收:
标记-清除算法:
就是当程序运行期间,若可以使用的内存被耗尽的时候,GC线程就会被触发并将程序暂停,随后将依旧存活的对象标记一遍,最终再将堆中所有没被标记的对象全部清除掉,接下来便让程序恢复运行
效率低
复制算法(新生态GC):
将原有的内存空间分为两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中的存活对象复制到未使用的内存块中,之后,清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收。
空间的浪费
标记-整理算法(老年态GC):
标记-整理/压缩算法适合用于存活对象较多的场合,如老年代。它在标记-清除算法的基础上做了一些优化。和标记-清除算法一样,标记-压缩算法也首先需要从根节点开始,对所有可达对象做一次标记;但之后,它并不简单的清理未标记的对象,而是将所有的存活对象压缩到内存的一端;之后,清理边界外所有的空间。
从效率上来说,标记/整理算法要低于复制算法。
(1)效率:复制算法>标记/整理算法>标记/清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。
(2)内存整齐度:复制算法=标记/整理算法>标记/清除算法。
(3)内存利用率:标记/整理算法=标记/清除算法>复制算法。
CMS是基于“标记-清除”算法实现的,整个过程分为4个步骤:
1、初始标记(CMS initial mark)。stop the world
2、并发标记(CMS concurrent mark)。
3、重新标记(CMS remark)。stop the world
4、并发清除(CMS concurrent sweep)。

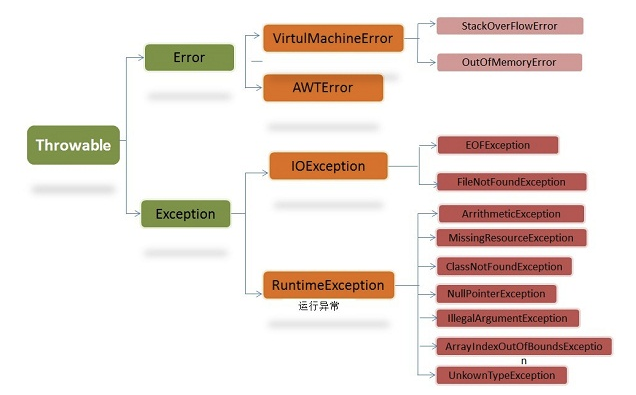
StackOverflowError代表的是,当栈深度超过虚拟机分配给线程的栈大小时就会出现此error。跟jvm的-Xss相关。
栈是运行时的单位,而堆是存储的单位
栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
栈内存溢出包括StackOverflowError和OutOfMemoryError。StackOverflowError:线程请求的栈深度大于虚拟机所允许的深度。OutOfMemoryError:如果虚拟机栈可以动态扩展,而扩展时无法申请到足够的内存;堆内存溢出是OutOfMemoryError。如果堆中没有内存完成实例分配,并且堆也无法再扩展时,抛出OutOfMemoryError异常。
方法递归调用产生StackOverflowError
FTP默认的数据端口号是20,21,22,23。 HTTP默认的端口号是25,80,1024,80。 HTTP服务器,默认的端口号为80/tcp
事务的四大特性分别是:原子性、一致性、隔离性、持久性
(1) git branch 上的修改可以保留,例如在某个branch上commit一个新的节点。checkout到其它branch后commit的节点不会丢。
(2) git tag上的修改 ,checkout到其它branch或者tag后,修改丢失。