GitHub地址
https://github.com/bugLoser/clubProject
1.数据生成说明
数据模型
部门
// 部门编号
private int clubId;
// 部门招收学生最大数量
private int maxRecruitStuNum;
// 部门特点标签
private List<String> featureTags;
// 部门常规活动时间
private List<String> routineTimes;
学生
// 学生编号
private int stuId;
// 绩点
private double gpa;
// 兴趣标签
private List<String> interestTags;
// 申请部门的编号
private List<Integer> applyClubId;
// 空闲时间
private List<String> freeTimes;
数据样例
部门
{"clubId":6,"featureTags":["特点48","特点5"],"maxRecruitStuNum":10,"routineTimes":["星期四 14:00-17:30","星期二 19:00-21:30"]}
学生
{"applyClubId":[15,12,18],"freeTimes":["星期二 19:00-21:30","星期日 19:00-21:30","星期六 08:00-12:00","星期五 19:00-21:30","星期四 19:00-21:30","星期三 19:00-21:30","星期日 08:00-12:00","星期六 19:00-21:30","星期日 14:00-17:30"],"gpa":3.3296728134155273,"interestTags":["特点30"],"stuId":1}
数据生成
部门
部门ID按顺序编号生成,部门招收学生的学生数随机生成,部门特点标签从固定数组中抽取个数为n(1<=n<=5,n随机生成)的元素。考虑到部门活动时间多数为学生非上课时间段,而这个时间段一般比较固定,为了模拟现实情况,所以在生成部门活动时间段数组时也是从一个固定数组进行随机抽取。如数据样例中所示,编号为6的部门其常规活动时间为星期二和星期四晚上,比较接近现实情况。
学生
产生学生数据和产生部门数据类似,为了达到兴趣匹配,学生兴趣标签和部门特点标签都是从同一个固定数组中进行随机抽取。同时,为了让学生能有更多时间去参加部门活动,学生的空闲时间段也是从产生部门活动时间段那个固定数组中抽取,最好地保证学生能够按时参加活动,模拟现实状况。
数据输出输入
本次任务数据保存为JSON格式,JsonWriter类已对写文件操作进行了一定的封装。
使用ClubReader、StudentReader两个接口作为数据的输入,如果要进行数据源的切换(如切换到数据库),可以用新的类去实现接口就行。
2.匹配算法描述
程序的匹配部分主要分为
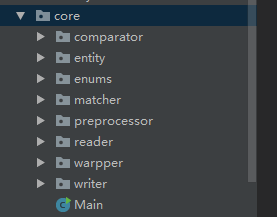 这些部分,其中Main为生成可执行程序的接口。在entity中主要有club和student的实体类,也就是基本信息,而在warpper包中的则是有着他们的包装类,以及为匹配器服务的MatchWarpper包装接口,该接口定义了匹配中所需要的一些操作。
这些部分,其中Main为生成可执行程序的接口。在entity中主要有club和student的实体类,也就是基本信息,而在warpper包中的则是有着他们的包装类,以及为匹配器服务的MatchWarpper包装接口,该接口定义了匹配中所需要的一些操作。
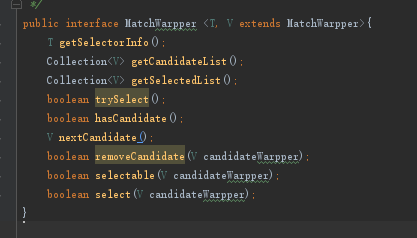
然后reader中则是对文件的读入部门学生信息以及将转化为包装类的信息。writer则是最后输出信息。
Enums则是定义了一些枚举量便于使用。
matcher匹配器包的matcher是匹配入口中,它需要的参数为MatchWarpper的集合以及preprocessor预处理器。

我这边的基础匹配方案是先确定挑选者,可以按学生选部门或者部门选学生,然后根据每个挑选者去选择他的候选者,在选择的时候也有挑选者优先还是候选者优先的不同,前者是挑选者一次性从候选列表中选中所需要的学生,后者则是挑选者每次选一个。

在默认的匹配器中,通过以上的preprocessor预处理器接口,可以在匹配开始前,每次匹配前,每次匹配后,匹配结束后分别对匹配元素集合进行处理。在这次的提供的两种匹配方法中,主要重写了前两个方法。如绩点优先在学生挑选的情况下是匹配开始前对整个学生集合排序,在部门挑选的情况下是每次匹配前对部门下的候选学生集合排序。在排序中,则使用到了comparator的排序器。
按照该种方案,可以有良好的扩展性。如果需要增加优先条件,只要继承预处理器Preprocessor实现自己的预处理器加上添加一个比较器即可。
3.代码规范
1、包名规范,在建立工程时,一起讨论各个子模块,创建相应的包,在后面的开发中,就将类按照要求放入相应的包中。
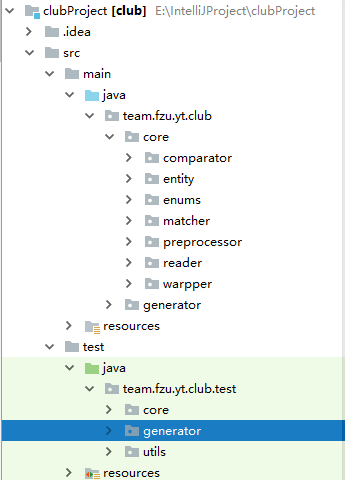
2、类名规范,如bean类使用简单易懂的名词来表示,而带有特定功能的类需要在类名中加上一定的后缀,比如XXGennerator、XXReader、XXWriter等等。

3、变量函数规范,要求变量名能直接从英文中看出用意,而函数名主要采用动宾结构。
4、对重要的函数加以注释说明,因为时间的限制,我们在开发中不强求每个点都写注释,也会通过交流的方式来互相帮助对方理解代码。
5、接口规范,在设计阶段,就给出大部分接口的定义,包括输入输出参数等。
6、考虑使用泛型来提高程序的复用性。
7、测试规范,使用XXTest进行单元测试,保存测试用例。
4.测试报告
| 优先条件 | 匹配学生个数 | 未匹配学生个数 | 实际耗时(s) | 输出文件路径 |
|---|---|---|---|---|
| 绩点优先 | 116 | 184 | 0.044 | https://github.com/bugLoser/clubProject/blob/master/test/match_result_gpa%2Ctxt |
| 兴趣优先 | 121 | 179 | 0.022 | https://github.com/bugLoser/clubProject/blob/master/test/match_result_interest%2Ctxt |
从测试结果可以看出,未匹配的学生较多,主要原因在于受数据随机性大的影响,部门招收数量是从[0,15]中生成,最后随机产生的结果招收总数在150左右,又因为学生有多个志愿,可以同时在多个部门中,所以匹配的学生又进一步减少,但实招人数占预招人数80%左右。在不提高招收总数的情况下,为了提高匹配成功率,需要调整匹配算法成优先照顾未被匹配的学生,而对于已经被其他部门匹配的学生归为较低的优先级。
5.结对感受
170320074
在设计过程中,考虑到变化的可能性,比如在本次任务中,多种匹配方式的改变,或者再到多种匹配方式的组合,组合又有多种情况,如权重积分、层层过滤等。这些需求虽然不一定在本次任务中实现出来,但是要在设计阶段就要开始应对这类变化,提供良好的接口,减少代码修改的影响面。所以,在设计过程中,我们的工作主要放在如何应对匹配方式变化上。
但是在本次任务中,在设计阶段总感觉有些想法不错,但不知道能不能实现,所以需要通过代码去验证,相对而言,还是编码的时间用的比较多,而较好的软件开发过程设计阶段应该占据较多的时间。所以,在后面的结对作业中,我希望能根据这几次作业的经验,比如设计与实现之间的差距,把控各个阶段的时间分配等,建立起较好的软件开发习惯,在实践中体会软件工程的各个过程。
170320076
这次的结对作业,由于考虑到算法的拓展性,我们花了很久时间来讨论。在这期间,很大的问题就是讲不清听不懂!自己所想的想法很难用言语准确地传达给对方,花了一大堆时间讨论,常常在最后来一句“原来是这个意思啊,你早这样讲我不久懂了”的感叹。在这,还要多谢我的小伙伴能不厌其烦的听我的想法,很有耐心。
然后这次的想法很丰富,不过在实际的编写情况下,常常会遇到难以实现的情况,或者突然而来的优化灵感,也造成程序是不断地写写改改。不过也许是功能分离的比较好,在调试中花的时间很少。
在这次作业过程中,由于各种原因,加班加点,虽然最终还是在凌晨把这个东西结束了,但程序赶出来也就会存在一些问题没解决。这也是前期的规划问题,在这个方面还是得好好下功夫处理下。
PS:周五下午发布的作业,周六花了点时间想,写了点,周日基本在休息,两人不在一起,也没怎么做,周一周二又全是课,赶作业赶到头疼。能不能以后在上课当天发作业,周四周五时间比较多呀。