1.根元素 /
必须逐层依次往下找,这个方式像是文件路径查找文件
listUrlA = response.xpath("/html/head/title/text()").extract()
2.直接定位元素 //
不需要每一层的路径都写上,直接查找它下面所有的标签
listUrlA = response.xpath("//title/text()").extract()
3.text()
只查找当前标签内的文字,不查找标签的属性和子标签的内容
*另
想查看所有内容末尾不要加/ 也不要加text()
4.@ 按标签的属性查找
按标签属性查找
//div[@id]
查找所有div标签的id属性值是content的
//div[@id='content']//span/text()
5.查找指定位置的元素
查找xx下的第2个span标签
../span[2]
查找xx下的倒数第二个span
../span[last()-1]
查找xx下的前二个span
../span[last()<3]
6.通配符
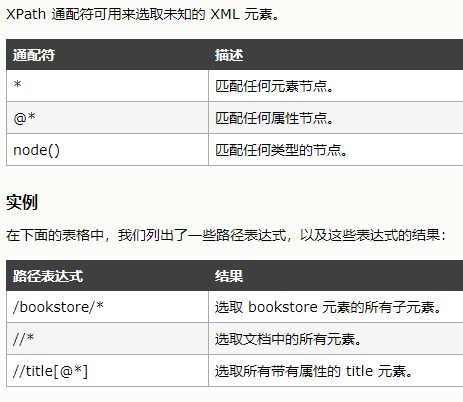
7.