当我们对于一些查询条件需要用到复杂子查询时,聚合函数操作起来非常麻烦,因此使用开窗函数能够轻松实现
窗口函数的引入是为了解决想要既显示聚集前的数据,又要显示聚集后的数据。 开窗函数对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
强调:使用 mysql8.0版本方可实现
语法:函数名(列) over(选项) 选项可以为 partition by 列 order by 列
over() 按所有行进行分组
over(partition by xxx) 按xxx分组的所有行进行分组 over(partition by xxx order by aaa) 按列xxx分组,按列aaa排序
over(order by aaa) 按aaa列排序
over括号中的partition by和order by的使用根据具体情况选择
示例
数据在本文的最后
开窗函数的分类
- 聚合开窗函数
函数名如果是聚合函数,则成为聚合开窗函数
语法:聚合函数(列) over(partition by 列 order by 列)
常见的聚合函数有:sum() count() average() max() min()
需求:计算每个学生的及格科目数
聚合函数执行结果
select student_id,count(sid) from score where num>= 60 group by student_id;
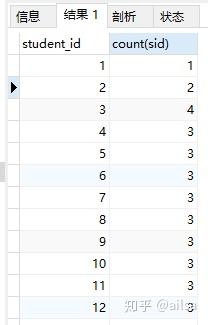
我们可以看出,通过普通的聚合函数分组计算后,数据表结构发生了变化,他会根据分组进行显示,并且,如果你是根据学生ID分组,那你查询的字段应该也是学生ID,不然会影响到分组结果所对应的数值,例如现在查询条件再添加一个SId
select sid,student_id,count(sid) from score where num>= 60 group by student_id;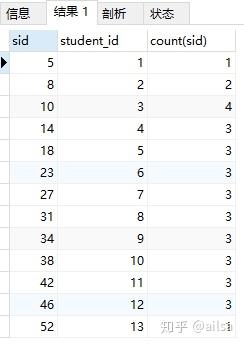
我们会发现sid的数据并没有实际意义,因为数据表已经根据分组发生了变化。
开窗函数的执行结果
select sid,student_id,count(sid) over(PARTITION by student_id order
by student_id) 及格数 from score where num>= 60;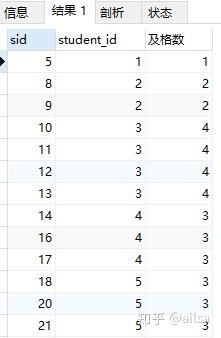
总结:我们会发现开窗函数不会修改源数据表的结构,也是在表的最后一列添加想要的结果,如果分组存在多行数据,则重复显示,因此对于既想要分组结果,又不想改变数据表的结构时,使用开窗函数效果非常好,但是对于聚合开窗函数来说,个人觉得大部分情况下还是采用聚合函数比较多。
对于排序来说,开窗函数确实好用
- 排序开窗函数
row_number(行号)
rank(排名)
dense_rank(密集排名)
ntile(分组排名)
都是排名函数,不同之处在于对于名次相同的数据处理方式
我们通过一个实例,来区分它们之间的不同之处
需求:查询各科成绩前三名的学生可成绩信息
如果使用聚合函数就比较麻烦了,再考虑到分数相同的情况的话会更麻烦,要多层嵌套才能实现,因此这个时候就凸显开窗函数的优势了
对每门课程进行分组排序,然后取出前三名即可
step1 先对所有数据进行排序
select s.sid,s1.sname,s1.gender,c.cname,s.num, row_number() over
(partition by c.cname order by num desc) as row_number排名,
rank() over (partition by c.cname order by num desc) as rank排名,
dense_rank() over (partition by c.cname order by num desc) as dense_rank排名,
ntile(6) over (partition by c.cname order by num desc) as ntile排名
from score s join student s1 on s.student_id = s1.sid
left join course c on s.course_id = c.cid结果如下
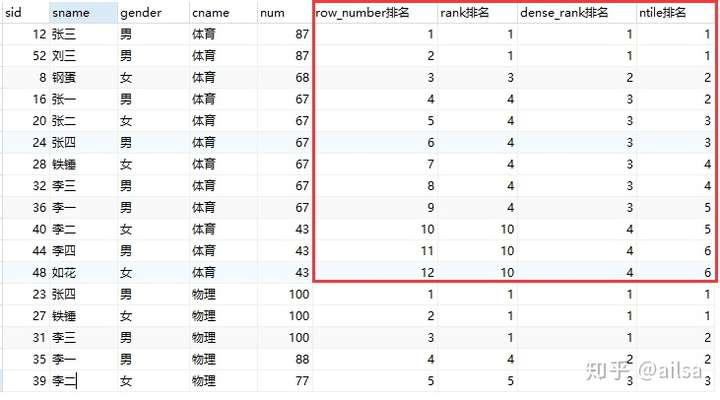
我们一个一个来分析
row_number
原理:根据课程进行分组,然后对每组内的成绩进行降序排序
我们可以看出row_number对于同组内的相同成绩并没有做特殊处理,而仅仅是生成连续的序号,因此用row_number 做成绩排序貌似不准备,当然它通常也不用在此处,这里只是为了方便对比,row_number 常用于按照某列生成连续序号,例如web程序的分页等等
rank
rank函数用于返回结果集的分区内每行的排名,简单来说rank函数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,通过上面的例子我们也可以看出,rank考虑到值相同情况,并且它的排名存在跳跃性。
dense_rank
从字面意思理解,密集排名,也是他在考虑了值相同时排名也相同,但是序号不跳跃,紧跟上一个序号,例如题目中体育成绩有2位同学(张三和刘三)并列第一,如果使用rank排名 ,那钢蛋就是第三名,而如果采用dense_rank 那钢蛋就是第二名,这个很容易理解吧。
ntile
我们从代码中可以看出,ntile()中有个数字,那其实ntile有一个叫“桶”的概念
原理是这样的
首先,ntile会先根据你的分组依据,本题中是课程名称,然后把每个组的总记录数进行按照你给的ntile()里的数字进行,这个数字就是桶数,相当于是把体育课程总共12条记录,尽量等划分成5桶,然后按照num的排序等级划分,每个桶两条记录,也就是112233445566的排序结果了,很显然,这个排序结果的数字大小只能用于桶与桶之间,而桶内部记录虽然序号相同,但是num不一定相同。
回到本题当中
统计各科成绩前三,那很显然,采用dense_rank 更合适
代码如下
select * from
(select s.sid,s1.sname,s1.gender,c.cname,s.num,dense_rank()
over (partition by c.cname order by num desc) as dense_rank排名 from score s
join student s1 on s.student_id = s1.sid
left join course c on s.course_id = c.cid) as e
where dense_rank排名 <= 3;- 其他
lag(col,n)
用于统计窗口内往上第n行值
lead(col,n)
用于统计窗口内往下第n行值
这两个函数可以用于同列中相邻行的数据相减操作
需求:对于下面的数据,对于同一用户(uid)如果在2分钟之内重新登录,则判断为作弊,统计哪些用户有作弊行为,并计算作弊次数
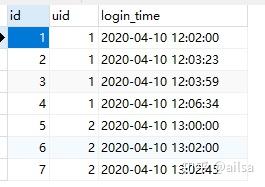
数据代码
create table lag_table(id int primary key,
uid int not null,
login_time datetime not null);
insert into lag_table values(1,1,"2020-4-10 12:02:00"),
(2,1,"2020-4-10 12:03:23"),
(3,1,"2020-4-10 12:03:59"),
(4,1,"2020-4-10 12:06:34"),
(5,2,"2020-4-10 13:00:00"),
(6,2,"2020-4-10 13:02:00"),
(7,2,"2020-4-10 13:02:45") 思路:
根据题目要求,如果能把相邻两列的下面那一列与上面那一列变成同一行,不就能实现相减了么,因此我们可以多生成一列,例如:我们可以把uid都为1的第二行记录生成到第一行,以此类推,这就可以用到lead往下移动的操作了。
select id,uid,login_time,lead(login_time,1) over(partition by uid order by login_time) lead_time from lag_table;
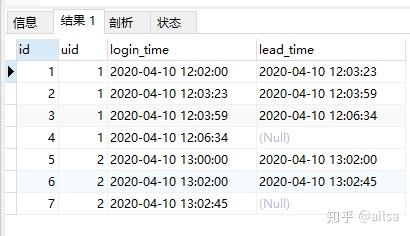
我们发现,根据不同用户,第二行的数据已经移动到第一行了,接下来进行相减操作就可以了
select *,format(相差秒数/60,3) 相差分钟数 from
(select id,uid,login_time,
lead(login_time,1) over(partition by uid order by login_time) lead_time,
TIMESTAMPDIFF(SECOND,login_time,(lead(login_time,1) over(partition by uid order by login_time))) 相差秒数
from lag_table)
as e现在进行相减操作
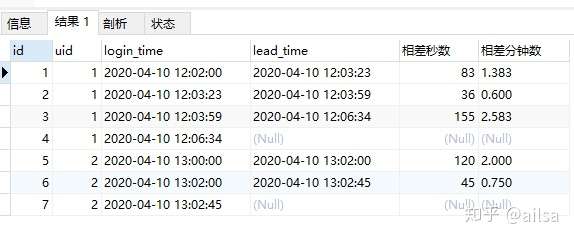
这里之所以相减单位设置为秒,是因为使用TIMESTAMPDIFF之后,会进行四舍五入,如果是2.3分钟的话,原则已经不算作弊了,但是我们计算时会统计上的,所以采用秒进行换算。
最终结果
select uid,count(1) 作弊次数 from
(select id,uid,login_time,
lead(login_time,1) over(partition by uid order by login_time) lead_time,
TIMESTAMPDIFF(SECOND,login_time,(lead(login_time,1) over(partition by uid order by login_time))) 相差秒数
from lag_table) as e
where format(相差秒数/60,3)<=2
group by uid;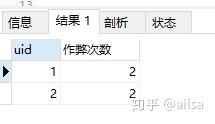
这里也可以考虑使用lag函数,只是相减的对象互换一下
select id,uid,login_time,lag(login_time,1)
over(partition by uid order by login_time) lead_time,
TIMESTAMPDIFF(SECOND,(lag(login_time,1) over(partition by uid order by login_time)),login_time) 相差秒数
from lag_table结果
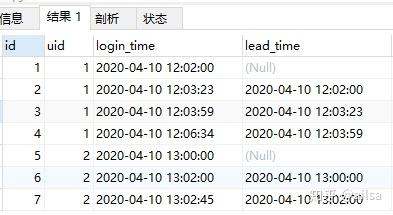
计算相差秒数及最终结果
select uid,count(1) 作弊次数 from
(select id,uid,login_time,
lag(login_time,1) over(partition by uid order by login_time) lead_time,
TIMESTAMPDIFF(SECOND,(lag(login_time,1) over(partition by uid order by login_time)),login_time) 相差秒数
from lag_table) as e where format(相差秒数/60,3)<=2 group by uid;first_value(column)
取分组内排序后,截止到当前行,第一个值
这个举个例子就明白了
select s.sid,s1.sname,s1.gender,c.cname,s.num,
first_value(num) over(partition by c.cname order by num desc) as first_value用法
from score s join student s1 on s.student_id = s1.sid
left join course c on s.course_id = c.cid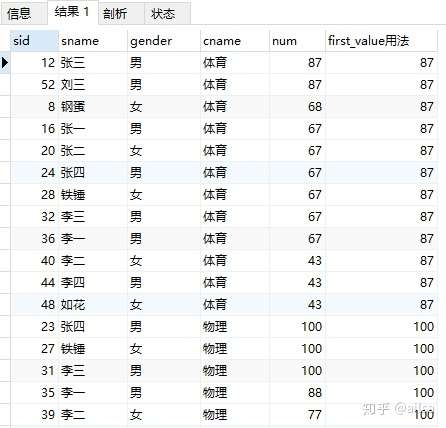
根据分组排序后,每组按照排序后第一个值进行显示
last_value(column)
取分组内排序后,截止到当前行,最后一个值
select s.sid,s1.sname,s1.gender,c.cname,s.num,
last_value(num) over(partition by c.cname ) as last_value用法
from score s join student s1 on s.student_id = s1.sid
left join course c on s.course_id = c.cid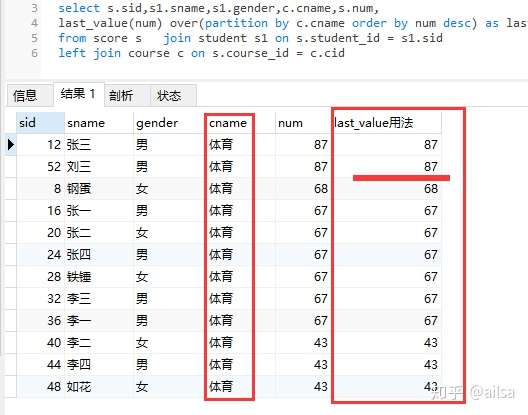
咦,为啥这里的last_value的用法不是按照每个组的最后一个值,也就是所谓的最小值来取值的呢?好像一个组中显示的结果也不一样,看着也没啥规律呀
其实,事实是这样的
last_value()默认统计范围是 rows between unbounded preceding and current row,也就是取当前行数据与当前行之前的数据的比较。
那我得改一下呀,这不是我们想要的效果,怎么改呢?
在order by 条件的后面加上语句:rows between unbounded preceding and unbounded following
可以理解为:当前分组数据中的所有数据进行比较,取最后一条记录
修改SQL
select s.sid,s1.sname,s1.gender,c.cname,s.num,
last_value(num) over(partition by c.cname order by num
desc rows between unbounded preceding and unbounded following) as last_value用法
from score s join student s1 on s.student_id = s1.sid
left join course c on s.course_id = c.cid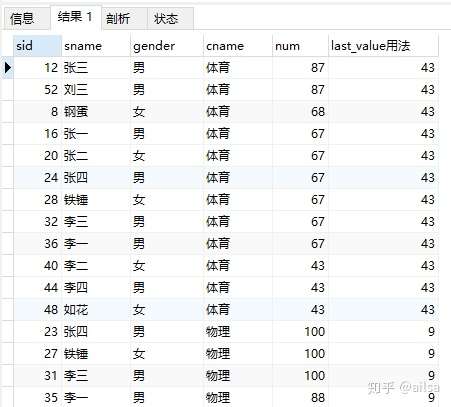
达到了我们想要的效果
详细解释:
rows beteween XXX and XXX
unbounded 无限制的
preceding 分区的当前记录的向前偏移量
current 当前
following 分区的当前记录的向后偏移量
附加思考
面试时有没有被问到过如何累计计算每个月的销售额
数据准备
某公司销售数据表
需求:计算每个月的销售额及累计销售额,结果如下:
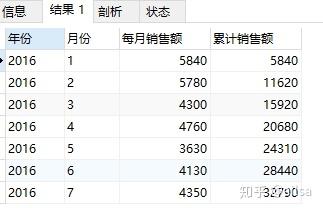
代码
select 年份,月份,sum(销售金额) 每月销售额,sum(sum(销售金额)) over(order by 月份
rows between unbounded preceding and current row) as 累计销售额
from sale group by 年份,月份;
数据库相关知识推荐:
ailsa:13 MySQL模块: 记录的增删改查zhuanlan.zhihu.com ailsa:12 MySQL模块:库表操作(DDL)zhuanlan.zhihu.com
ailsa:12 MySQL模块:库表操作(DDL)zhuanlan.zhihu.com
注:
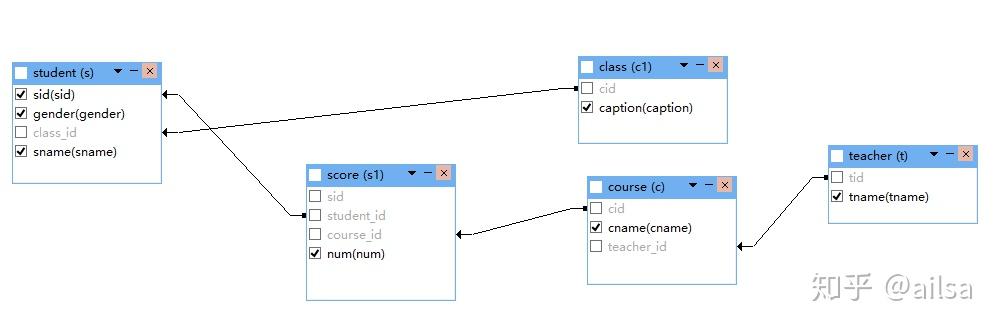
示例1--数据
CREATE TABLE class (
cid int(11) NOT NULL AUTO_INCREMENT,
caption varchar(32) NOT NULL,
PRIMARY KEY (cid)
) ENGINE=InnoDB CHARSET=utf8;
INSERT INTO class VALUES
(1, '三年二班'),
(2, '三年三班'),
(3, '一年二班'),
(4, '二年九班');
CREATE TABLE teacher(
tid int(11) NOT NULL AUTO_INCREMENT,
tname varchar(32) NOT NULL,
PRIMARY KEY (tid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO teacher VALUES
(1, '张磊老师'),
(2, '李平老师'),
(3, '刘海燕老师'),
(4, '朱云海老师'),
(5, '李杰老师');
CREATE TABLE course(
cid int(11) NOT NULL AUTO_INCREMENT,
cname varchar(32) NOT NULL,
teacher_id int(11) NOT NULL,
PRIMARY KEY (cid),
KEY fk_course_teacher (teacher_id),
CONSTRAINT fk_course_teacher FOREIGN KEY (teacher_id) REFERENCES teacher (tid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO course VALUES
(1, '生物', 1),
(2, '物理', 2),
(3, '体育', 3),
(4, '美术', 2);
CREATE TABLE student(
sid int(11) NOT NULL AUTO_INCREMENT,
gender char(1) NOT NULL,
class_id int(11) NOT NULL,
sname varchar(32) NOT NULL,
PRIMARY KEY (sid),
KEY fk_class (class_id),
CONSTRAINT fk_class FOREIGN KEY (class_id) REFERENCES class (cid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO student VALUES
(1, '男', 1, '理解'),
(2, '女', 1, '钢蛋'),
(3, '男', 1, '张三'),
(4, '男', 1, '张一'),
(5, '女', 1, '张二'),
(6, '男', 1, '张四'),
(7, '女', 2, '铁锤'),
(8, '男', 2, '李三'),
(9, '男', 2, '李一'),
(10, '女', 2, '李二'),
(11, '男', 2, '李四'),
(12, '女', 3, '如花'),
(13, '男', 3, '刘三'),
(14, '男', 3, '刘一'),
(15, '女', 3, '刘二'),
(16, '男', 3, '刘四');
CREATE TABLE score (
sid int(11) NOT NULL AUTO_INCREMENT,
student_id int(11) NOT NULL,
course_id int(11) NOT NULL,
num int(11) NOT NULL,
PRIMARY KEY (sid),
KEY fk_score_student (student_id),
KEY fk_score_course (course_id),
CONSTRAINT fk_score_course FOREIGN KEY (course_id) REFERENCES course (cid),
CONSTRAINT fk_score_student FOREIGN KEY (student_id) REFERENCES student(sid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO score VALUES
(1, 1, 1, 10),
(2, 1, 2, 9),
(5, 1, 4, 66),
(6, 2, 1, 8),
(8, 2, 3, 68),
(9, 2, 4, 99),
(10, 3, 1, 77),
(11, 3, 2, 66),
(12, 3, 3, 87),
(13, 3, 4, 99),
(14, 4, 1, 79),
(15, 4, 2, 11),
(16, 4, 3, 67),
(17, 4, 4, 100),
(18, 5, 1, 79),
(19, 5, 2, 11),
(20, 5, 3, 67),
(21, 5, 4, 100),
(22, 6, 1, 9),
(23, 6, 2, 100),
(24, 6, 3, 67),
(25, 6, 4, 100),
(26, 7, 1, 9),
(27, 7, 2, 100),
(28, 7, 3, 67),
(29, 7, 4, 88),
(30, 8, 1, 9),
(31, 8, 2, 100),
(32, 8, 3, 67),
(33, 8, 4, 88),
(34, 9, 1, 91),
(35, 9, 2, 88),
(36, 9, 3, 67),
(37, 9, 4, 22),
(38, 10, 1, 90),
(39, 10, 2, 77),
(40, 10, 3, 43),
(41, 10, 4, 87),
(42, 11, 1, 90),
(43, 11, 2, 77),
(44, 11, 3, 43),
(45, 11, 4, 87),
(46, 12, 1, 90),
(47, 12, 2, 77),
(48, 12, 3, 43),
(49, 12, 4, 87),
(52, 13, 3, 87);