
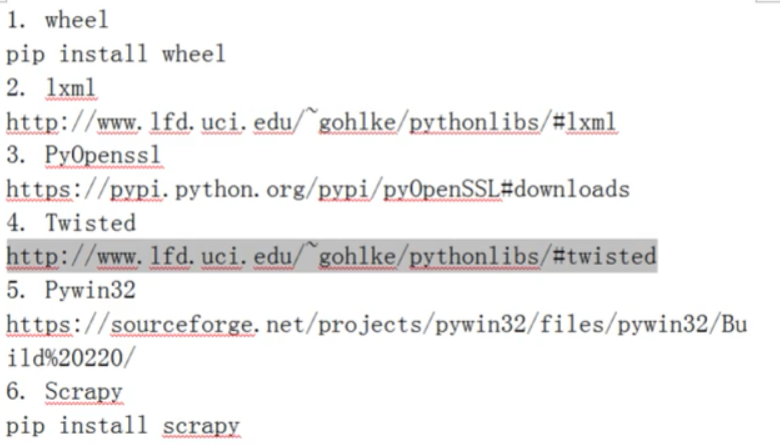
安装依赖
基础运用

在item中定义一个类(scrapy.Item)来保存 类似于django

yield返回两种东西,一种是在items中定义好的类 一种是新的请求
css选择器选取的标签
如果要保存到数据库 或者对数据进行一些处理 在pipeline中进行操作
处理可以返回两种值
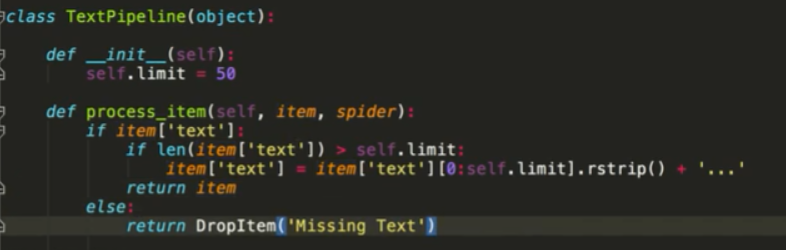
如果要存入数据库
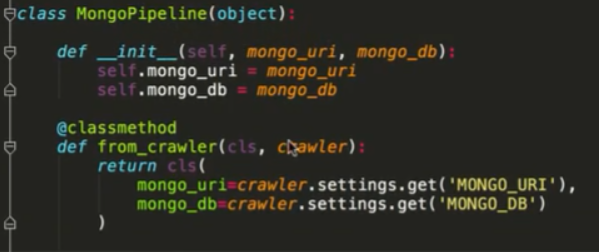

要记得修改pipeline设置

命令行命令
scrapy createproject projectName [dir]
开始新项目
scrapy genspider name url
创建爬虫
scrapy crawl name
执行对应爬虫命令 在class ClassName(scrapy.Spider)中定义类属性name
scrapy crawl [name] -o xxxx.json(.jl .csv .pickle .marshal ftp://user:pass@ftp.example.com/path/xxx.csv)
scrapy check 检查是否有错
scrapy list 查看所有爬虫