redis:通常BOLEAN操作类型,操作成功返回1,操作失败返回0
通常如果往设置的key插入值,但是这个key不存在,redis则会创建
向redis里的某个key插入多个值时,值和值之间用空格隔开,不能使用(,)
redis操作里,b开头的都是代表阻塞的意思
key篇:
//这里的key为所有类型key的统称,包括包括string,hash等
1.del【key】:删除key,区别hdel(删除hash里的field)
2.exists 【key】:1表示有,0表示无
3.expire 【key】:给某个key设置过期时间,可以用做导航会话:
假设你有一项 web 服务,打算根据用户最近访问的 N 个页面来进行物品推荐,并且假设用户停止阅览超过 60 秒,那么就清空阅览记录(为了减少物品推荐的计算量,并且保持推荐物品的新鲜度)。 这些最近访问的页面记录,我们称之为『导航会话』,可以用 EXPIRE和 RPUSH命令在 Redis 中实现它:每当用户阅览一个网页的时候,执行以下代码: RPUSH pagewviews.user:<userid> http://..... EXPIRE pagewviews.user:<userid> 60 如果用户停止阅览超过 60 秒,那么它的导航会话就会被清空,当用户重新开始阅览的时候,系统又会重新记录导航会话,继续进行物品推荐。
4.keys [pattern]:按pattern去匹配key,但是一个大的数据库中使用它可能会造成性能问题,如果你需要从一个数据集中查找特定的 key ,你最好还是用 Redis 的集合结构(set)来代替。
redis pattern:有 *(0个或多个)、?(占位符一个)、[ ] (在方框里的,只能出现一次)、特殊符号用 隔开
查找所有符合给定模式 pattern 的 key 。
5.migrate :数据迁移,从一个redis实例将指定key序列化,传输到另一个redis,这个redis执行反序列化,并进行restore,然后原redis开始del,一套操作完成后,mrgrate返回ok
6.persist 【key】:移除给定 key 的生存时间,将这个 key 从『易失的』(带生存时间 key )转换成『持久的』(一个不带生存时间、永不过期的 key )。
7.ttl/pttl【ley】:查看某个key的剩余存活时间(秒/毫秒)// 注意:当key不存在时返回-2,当key已过期返回-1
8.randomkey:从数据库中,返回一个随机的key,当数据库为空时,返回nil
9.rename【key】/renamenx【key】:更改制定key的名字,不存在时,则报错,后者:如果key已经改名了,则不在去改名
10.dump 【key】:/restore【key】:序列化key/反序列化key
11.type 【key】:返回指定key的类型,返回值有:
List篇:
tip:不管是从左开始插入,还是右插入,左边为对头,右边为队尾。
1.从原有的或者可以新建list,从右向左插入,简称RPSUH:rpush key 【value...】,可以允许重复元素 eg:rpush demo a b c ,那么现在是a,b,c//先进先出(队列):rpush+lpop
2.从原有的或者可以新建list,从左向右插入,简称LPSUH:lpush key 【value...】,可以允许重复元素 eg:lpush demo a b c ,那么现在是c,b,a//先进后出(栈):lpush+lpop
3.rpop 【key】:移除并返回列表 key 的尾元素,有相对应的阻塞版。
4.lpop 【key】:移除并返回列表key的头部元素,有相对应的阻塞版。// 区别于lrange,lrange只是展示,而不是移除

5.lrange【key】【start】【stop】:返回列表 key 中指定区间内的元素,不影响原集合,区间以偏移量 start 和 stop 指定。start 和 stop 都以 0 为底,也就是说,以 0 表示列表的第一个元素,可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元 //这也是list查看元素的方式
每一次lpush或rpush操作,都是返回的集合长度
6.rpushx【key】【value】/lpushx【key】【value】:相比rpush,prushx不回去建list,也就是当key不存在的时候,什么也不做
7.ltrim【key】【start】【stop】:对list进行裁剪(移除),含头含尾,从0开始,返回ok //通常用来删除list中的某些元素,这个是根据index删除,而lrem是根据值进行模糊删除
8.rpoplpush【source】【DESTINATION 】://source和destination是不同的list,前者弹出尾部元素,后者将其加入头部,客户端收到前者弹出的尾部元素 // 记忆:蛇的尾巴被蛇咬
9.lset 【key】【index】【value】:针对某个list的某个index,替换!!!它的值(区别区linsert),返回ok,注意是替换,而且只能返回ok,很蛋疼
10.llen 【key】:返回list的长度
11.linsert 【key】before/after 【pivot(基准点的意思)】【value】:在key的pivot的前或后插入value
12.lrem【key】【count】【value】:与ltrim非常像,也是用来删除元素的,但是他是指定删除值为value的count个元素,当count=0时,删除值为value的所有元素
13.lindex【key】【index】:显示列表中下标为 index 的元素。index可以为负数,-1为倒数第一
14.brpop【key...】【超时时间s,如果为0,则为永久等待】:跟rpop没什么区别,就是得设置超时时间,他会在超时时间里一直阻塞直到有新的元素push,他才能去pop,否则回复超时时间 //blpop同理 他们可以代替轮询,去做事件提醒,当事件发生,将事件push入事件队列,然后另一侧blpop或brpop会弹出,接着去回调
但是值得注意的是,rpop只能操作单个key,但是brpop可以操作多个key!意义就是,当第一个key的集合pop完,不阻塞,开始继续pop第二个key的集合,直到所有的key的集合全部pop完,开始阻塞
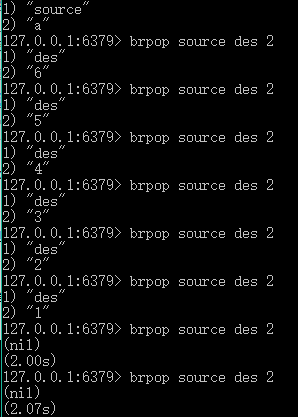
返回的第一行代表key名称,第二行代表pop弹出元素,当没有元素弹出的时候,返回nil和总共花费时间
15.brpoplpush【source】【destination】:rpoplpush的阻塞版本,当从sourcec里pop元素时,发现source为空,会阻塞,直到超时或者source被push新的元素
rpoplpush(尾被蛇咬)的补充:
1.安全队列(主备队列):
Redis的列表经常被用作队列,用于在不同程序之间有序地交换消息。一个客户端通过 LPUSH 命令将消息放入队列中,而另一个客户端通过 RPOP 或者 BRPOP 命令取出队列中等待时间最长的消息。
但是上面的队列方法是『不安全』的,因为在这个过程中,一个客户端可能在取出一个消息之后崩溃,但是消息队列的消息已经pop出了,没有备份的。
使用 RPOPLPUSH 命令(或者它的阻塞版本 BRPOPLPUSH )可以解决这个问题:因为它不仅返回一个消息,同时还将这个消息添加到另一个备份列表当中,如果一切正常的话,当一个客户端完成某个消息的处理之后,可以用 LREM 命令将这个消息从备份表删除。
最后,添加用于监视备份表的功能,它自动地将超过一定处理时限(客户端收到消息后会有个异步通知,如果超过时间还是没有收到来自客户端的确认,那么估计客户端down了)的消息重新放入队列中去(负责处理该消息的客户端可能已经崩溃),这样就不会丢失任何消息了。
2.循环列表(自身循环,可用做业务并行处理):
通过rpoplpush 【source】【destination】,让source=destination,完成循环队列功能:好处就是可以一个一个将队列中的元素push出,还不会丢失元素,不必像 LRANGE 命令那样一下子将所有列表元素都从服务器传送到客户端中
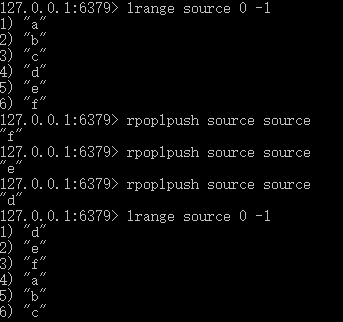
以上的模式甚至在以下的两个情况下也能正常工作:
- 有多个客户端同时对同一个列表进行旋转(rotating),它们获取不同的元素(并行处理),直到所有元素都被读取完(比如线程A读取a,b,线程B读取c,d,但是A,B都是为了检查abcd这四个字母的正确性,所以相当于任务分割执行了),之后又从头开始。
- 有客户端在向列表尾部(右边)添加新元素。
这个模式使得我们可以很容易实现这样一类系统:有 N 个客户端,需要连续不断地对一些元素进行处理,而且处理的过程必须尽可能地快。一个典型的例子就是服务器的监控程序:它们需要在尽可能短的时间内,并行地检查一组网站,确保它们的可访问性,相当于将一组网站设立为循环队列,多台服务器一起并行扫描,但是网站在队列里不会丢失,很安全
Set篇:
1.新建set或者向已有的set插入元素(不重复为1):sadd【key】【members...】,插入重复元素返回0,其他返回1
2.查看所有set元素:smembers【key】,如果key不存在返回empty list or set
3.检测set是否存在某member:sismember【key】【member】:如果key不存在,或者member不存在,则返回0
4.查看set集合长度 :scard【key】返回元素个数,区别于x类型的xlen语法,比如hash的hlen,但是都返回的是元素个数,从1开始
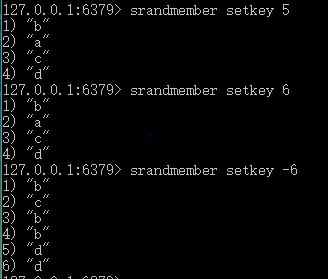
5.随机查看(注意不是移除)set集合中一个或多个元素:srandmember【key】【count】:count为正,显示的元素不重复 || count为负,显示的元素重复,取出count绝对值个
6.随机移除set集合中的一个或多个元素:spop【key】【count】:count可以不加 spop跟srandmember很像
7.移除set集合指定的一个或多个元素:srem【key】【member...】 5,6,7联合记忆

8.将一个set中(A)的元素移动到另一个set集合(B)smove【A】【B】【value】:如果A=B,则无改变,如果B已经存在value,则只是单纯的删除A中的value,如果B集合不存在,则自动创建B
9.sunion【A】【B】:返回A,B中的并集(不包含重复元素)
10.sunionstore【destination】【key...】:将多个key的并集保存到destination,这个destination可以是key...中的元素
11.sdiff【key...】:返回一个集合的全部成员,该集合是所有给定集合之间的差集(这里的差集:sdiff 【A】【B】,A包含a,b,c,B包含a,b,c,d,那么返回空集合,但是sdiff【B】【A】,则返回d)。注意,如果sdiff 【A】=>smembers【A】,查看set集合元素
12.sdiffstore【destination】【A】【B】【...】:作用和sdiff相似,但是,它可以存储AB差集到destination
13.sinter【key...】:做交集,与上面差不多
14.sinterstore【destination】【key...】:与上面差不多
总结tip:redis的两个set集合可以做差集,做并集,做交集,并且可以存储下来,
redis中查看一个set集合的元素:可以用smembers【key】,sunion【key】,sdiff【key】,sinter【key】
15.sscan【key】【cursor】match【xx】count【xx】
SortedSet篇:
1.添加或创建一个zset,再添加: zadd【key】【score空格member】【score空格member...】,这个score可以是整数或者是双精度类型,注意zset中,默认是按照score从小到达排序(zset特性)
2.给zset集合的某个成员''加薪":zincrby【key】【increment】【member】:zincrby host 10 brx,注意,浮点加浮点类型“工资”,比较好,整数+浮点有点误差
3.查看指定区间的zset元素(0,-1代表全部),关注点是index,区别于(zrangebyscore,关注点是分值区间):zrange【key】【start】【stop】【withscores】:默认按分值从小到大排序,相同分值,按字典排序(首字母顺序abcd),注意,zset类型,不像set那么多的查看手段(smembers,sunion,sinier,sdiff)
如果不加withscores关键字,那么只返回key的集合,不会返回分值,加上withscores后,返回member score //这里start,stop从0开始,-1表示最后一个元素
4.zrevrange 与上面的功能差不多,只是排序是按从大到小的分值来排。

5.根据给定的分值区间去分页查询:zrangebyscore【key】【min】【max】【withscores】【limit offset count】//zrevrangebyscore:从大到小排序
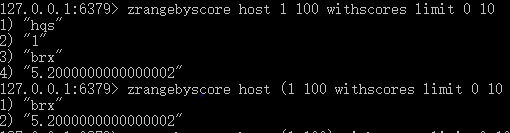

这里,zrangebyscore 【key】【min】【max】这里min,max默认闭区间,如果要开区间的话加入(符号,+inf代表正无穷,-inf代表负无穷
zrangebyscore host -inf 4 代表从host集合里筛选SCORE<=4的member
6.根据给定的分值区间去删除元素:zremrangebyscore【key】【min】【max】:支持(,+inf,-inf 注意:没有zremrange
7.zrank/zrevrank【key】【member】:查看某个zset中的某个member的排名,rank是分越小,排名越高// zrank游戏排名,zrevrank成绩排名
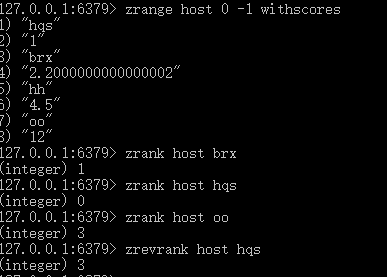
8.zscan【key】【cursor】match【pattern】count【count】
9.zcard【key】:返回zset的长度,都是从1开始
10.zcount【key】【min】【max】:根据分值区间,查找数目,支持(,+inf,-inf
String篇:
1.插入或取出:set 【key】【value】【过期时间s|ms】,setex(过期时间,以s为单位),psetex(过期时间,以毫秒p为单位),setnx(当key不存在,才插入),msetnx(多个key一起插入,插入成功条件:所有给定 key 都不存在,如果存在部分key,依然失败),setrange 【key】【offset】【value】//将指定的key的offset的位置(从0开始)替换为value,注意:对空字符串/不存在的 key 进行 SETRANGE,会用x00填充(代表一个位置),get/mget【key...】(取出value),getrange 【key】【start】【end】对原有的的key按start的位置开始(从0算起),截取到end位置,将start-end(含头含尾)内容返回给用户,不改变原有值。getset【key】【value】:设置新value,返回旧value,如果没有旧value,返回nil。
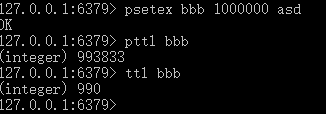

2.返回长度:strlen 【key】,只能使用于string类型,返回int值
3.原子递增/递减,固定步长递增/递减:incr 【key】如果这个key不存在,则自动新生成key,值为0,然后再执行incr。
通常incr+getset做计数器,getset主要是为了计数器清零
incr+expire做限速器(限制单位访问量),某一时间做key,首次访问设置过期时间,之后比如10次内,再次访问,incr,超过10次禁止访问,过了过期时间后,重新设置key//递归的过程
incrbyfloat:按给定的浮点类型数值增长value,并对value做一些类型转换,比如转为整数,4.00000->4,redis自动转换
4.append【key】【value】,如果key存在,给key对应的值尾部追加value,如果key不存在,那么就直接生成一个string类型,值为value。
通常用append+getrange(因为每一小块数据都是定常数据,所以后面序列增长,需要做二分法查找)做时间序列:
时间序列:一系列定长数据提供一种紧凑的表示方式
可以通过以下的方式访问时间序列的各项属性:
- STRLEN 时间序列中数据的数量
- GETRANGE 用于随机访问。只要有相关的时间信息的话,我们就可以在 Redis 2.6 中使用 Lua 脚本和 GETRANGE 命令实现二分查找。
- SETRANGE 用于覆盖或修改已存在的的时间序列。
HASH篇:
1.插入或取值:hset【key】【filed】【value】,hget ,hmset,hmget //key指的是hash的名字,field指的是string的名字,value指的是string的值
2.删除:hdel 【key】【field...】
3.增加某key对应的数值类型的值:hincrby 【key】【field】【increment】
4.遍历某个hash的所有key:hkeys 【key】
5.遍历某个hash的所有value:hvals 【key】
6.遍历某个hash的所有field+value:hgetall 【key】,前一行是key,后一行是value,依次类推

7.添加field,如果该hash有同名field,则添加失败,返回0,否则返回1,先取再插,但是是一个原子操作;hsetnx 【key】【field】【value】
8.查看某hash的长度:hlen 【key】返回int数值
9.某hash,根据某key进行模糊查询:hscan 【key】【cursor】match【*xxx*】count【xx】
SCAN相关命令补充:
SCAN 命令是一个基于游标的迭代器: SCAN 命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
以 0 作为游标开始一次新的迭代, 一直调用 SCAN 命令, 直到命令返回游标 0 , 我们称这个过程为一次完整遍历
count参数的缺点:
并不保证每次执行都返回某个给定数量的元素。 COUNT 选项的作用就是让用户告知迭代命令, 在每次迭代中应该(不固定)从数据集里返回多少元素。
COUNT参数的默认值为10。- 在迭代一个足够大的键集合时, 该命令返回的元素数量通常和
COUNT选项指定的一样, 或者比COUNT选项指定的数量稍多一些(count只能作为redis参考此次scan的依据)。 - 在迭代一个较小的键集合时, 增量式迭代命令通常会无视
COUNT选项指定的值, 在第一次迭代就将所有数据都返回给用户。 -
只有两种游标是合法的:
- 在开始一个新的迭代时, 游标必须为
0。 - 执行之后返回的, 用于下一次迭代过程的游标。
- 在开始一个新的迭代时, 游标必须为
*scan命令:
- SCAN 命令用于迭代当前数据库中的数据库键(包含string,hash之类的所有键)。
这些命令可以用于生产环境, 而不会出现像 KEYS 命令、 SMEMBERS 命令带来的问题 —— 当 KEYS 命令被用于处理一个大的数据库时, 又或者 SMEMBERS 命令被用于处理一个大的集合键时, 它们可能会阻塞(block)服务器达数秒之久。
增量式迭代命令(就像是分页查询一样count->pageSize)缺点:在对键进行增量式迭代的过程中, 键可能会被修改, 所以增量式迭代命令只能对被返回的元素提供有限的保证
并且同一个元素可能会被返回多次;一个元素是在迭代过程中被添加到数据集的, 又或者是在迭代过程中从数据集中被删除的, 那么这个元素可能会被返回, 也可能不会, 这是未定义的(undefined)

第一行是游标数
第二行是结果集
Transaction篇:
1.watch【key...】:监视keys,当事务执行之前,这些key被其他命令更改,那么事务将会被打断,tip; WATCH 监视了一个带过期时间的键, 那么即使这个键过期了, 事务仍然可以正常执行
2.unwatch:取消 WATCH 命令对所有 key 的监视。tip:如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。
3.multi:开启一个事务块(存储事件的队列):事件按照先后顺序被放进一个队列当中 ,返回 queued(排队的意思)
4.exec:执行一个事务块,当watch在监视某些key的时候,如果执行事务的时候,这些key被更改,那么事务会执行失败,返回nil,如果成功,那么结束watch,
eg:
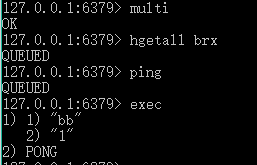

5.discard:
取消事务,放弃执行事务块内的所有命令。
如果正在使用 WATCH 命令监视某个(或某些) key,那么取消所有监视,等同于执行命令 UNWATCH 。
先得multi,然后才能discard,discard后,watch失效。
补充:
watch用途:
1.WATCH 可以用于创建 Redis 没有内置的原子操作(比如实现zpop的功能,弹出(取时删)一个元素)。 2.watch监视key(这个key共享数据),对key设置新值时,这段操作加入一个multi-exec中,完成乐观锁
举个例子, 以下代码实现了原创的 ZPOP 命令, 它可以原子地弹出有序集合中分值(score)最小的元素:
WATCH zset
element = ZRANGE zset 0 0 //查看第一个元素(score最小)
MULTI
ZREM zset element //删除
EXEC
持久化篇:
Redis 提供了多种不同级别(4种)的持久化方式:
- RDB 持久化:在指定的时间间隔内生成数据集快照(=snapshot)。
- AOF 持久化:记录服务器执行的所有写操作命令,并在服务器重新启动时,通过执行这些命令来还原数据集。之后新命令会被追加到文件的末尾。 Redis 还可以自动在后台对 AOF 文件进行重写(rewrite),目的:减小AOF 文件的体积 重写:Redis 将生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令
- 同时使用 AOF 持久化和 RDB 持久化。 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
- 关闭持久化功能,让数据只在服务器运行时存在。
RDB 的优点:
- RDB 是一个非常紧凑的文件,保存的是 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,可以随时将数据集还原到不同的版本(不同的时间点山)。
- RDB 非常适用于灾难恢复(地域容灾):内容非常紧凑,(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。
- RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时 fork 出一个子进程,所有保存工作由子进程来完成,父进程无须执行任何磁盘 I/O 操作。注意:是子进程
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点
- 如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。RDB 只能设置不同的保存点来控制保存 RDB 文件的频率, 它需要保存整个数据集的状态(耗时较长)。可能会至少 5 分钟(保存频率)才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。
- 每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某毫秒内停止处理客户端(相当于整理垃圾,不能产生新垃圾的感觉,阻塞用户操作); 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失(感觉像是跟用户线程并发)。
AOF 的优点
使用 AOF 持久化会让 Redis 变得非常耐久(数据完整):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程继续努处理命令)。
- AOF 文件是一个只进行追加操作的日志文件;因为某些原因而写入了不完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了所有的写入操作, 这些写入操作以 Redis 协议的格式保存; 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件(紧凑)的体积。
- 根据所使用的 fsync 策略,AOF(默认每秒) 的速度可能会慢于 RDB(紧凑,时间点) 。
- AOF 可能会出现 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。)RDB 几乎是不可能出现这种 bug 的。
RDB 和 AOF 的选择:
1.关注数据安全性, 同时使用两种持久化功能。
2.只使用 RDB 持久化。但得承受数分钟以内的数据丢失(有时可以容忍)
3.只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
RDB 快照
在默认情况下, Redis 将数据库快照保存在名字为 dump.rdb 的二进制文件中。
你也可以通过调用 SAVE 或者 BGSAVE , 手动让 Redis 进行数据集保存操作。
对redis进行设置, 以下设置会让 Redis 在满足“ 60 秒内有至少有 1000 个键被改动”这一条件时, 自动保存一次数据集:
save 60 1000
只进行追加操作的文件(AOF)
快照功能并不是非常耐久: 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入但仍未保存的那些数据。
你可以通过修改配置文件来打开 AOF 功能:
appendonly yes
每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。
这样的话, 当 Redis 重新启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
AOF 重写
因为 AOF 的运作方式是不断地将命令追加到文件的末尾, 随着写入命令的不断增加, AOF 文件的体积也会变得越来越大。
举个例子, 如果你对一个计数器调用了 100 次 INCR , 那么仅仅是为了保存这个计数器的当前值, AOF 文件就需要使用 100 条记录(entry)。
然而在实际上, 只使用一条 SET 命令已经足以保存计数器的当前值了, 其余 99 条记录实际上都是多余的。
为了处理这种情况, Redis 支持一种有趣的特性: 可以在不打断服务客户端的情况下, 对 AOF 文件进行重建(rebuild)。
执行 BGREWRITEAOF 命令, Redis 将生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令。2.4版本以上自动触发
你可以配置 Redis 多久才将数据 fsync (内存缓存区到磁盘的函数)一次。
fsync有三个选项:
- 每次有新命令追加到 AOF 文件时就执行一次 fsync :非常慢,也非常安全。
- 每秒 fsync 一次:足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。
- 从不 fsync :将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
如果 AOF 文件出错了,怎么办?
如果AOF 文件出错, 那么 Redis 在重启时会拒绝载入这个 AOF 文件, 从而确保数据的一致性不会被破坏。
解决方法:
- 为现有的 AOF 文件创建一个备份。
- 使用 Redis 附带的 redis-check-aof 程序,对原来的 AOF 文件进行修复。
$ redis-check-aof --fix
- (可选)使用 diff -u 对比修复后的 AOF 文件和原始 AOF 文件的备份,查看两个文件之间的不同之处。
- 重启 Redis 服务器,载入修复后的 AOF 文件,并进行数据恢复。
当 Redis 启动时, 如果 RDB 持久化和 AOF 持久化都被打开了, 那么程序会优先使用 AOF 文件来恢复数据集, 因为 AOF 文件所保存的数据通常是最完整的。
备份 Redis 数据
无论何时, 复制 RDB 文件都是绝对安全(cow机制+rename文件原子操作:将零时rdb名字替换成现有rdb)的。
建议:
- 创建一个定期任务(cron job), 每小时,每天后将 RDB 文件备份到不同文件夹。
- 确保快照的备份都带有相应的时间信息:用来删除过期的快照或者恢复某时间点上的数据
- 至少每天一次, 将 RDB 备份到你的数据中心之外,其他物理机之外(容灾)。
容灾:将这些备份传送到多个不同的外部数据中心(可以加密传输到第三方云存储:亚马逊,阿里云,或者通过ssh传出到其他服务器)。注意:接收方要检测数据完整性+报警系统(用于提示备份失败)
服务器篇:
1.查看key的数量:dbsize
2.bgsave:后台异步保存当前数据库的数据到磁盘(RDB形式)。
3.save: 一个同步保存操作,将当前 Redis 实例的所有数据以 RDB 文件的形式保存到硬盘。
tip:通常由 BGSAVE 命令异步地执行。当后台子进程不幸出现问题时, SAVE 可以作为保存数据的最后手段来使用。
4.fulshall:清空整个 Redis 服务器的数据
5.flushdb:清空当前数据库的所有key
6.info:查看当前redis的各种数据配置
7.config set xxx:在不关闭redis的时候,动态去更改redis属性!!!!
eg:
redis-cli> CONFIG SET appendonly yes redis-cli> CONFIG SET save "" //关闭RDB功能!!!
第一条命令开启了 AOF 功能: Redis 会阻塞直到初始 AOF 文件创建完成为止, 之后 Redis 会继续处理命令请求, 并开始将写入命令追加到 AOF 文件末尾。
第二条命令用于关闭 RDB 功能。 这一步是可选的, 如果你愿意的话, 也可以同时使用 RDB 和 AOF 这两种持久化功能