【RESP-协议内容】
Redis序列化协议的简写(Redis Serialization Protocol),是一种直观的文本协议,虽然浪费了一些流量,但是实现简单,解析性能极好。
协议规定了5种最小单元类型的传输数据结构,单元结束时统一加上回车换行符\r\n。
单行字符串----以'+'开头
多行字符串----以'$'开头,后面跟一个数字,表示字符串长度
整数值----以':'符号开头,后面跟整数的字符串形式
错误提示----以'-'开头
数组----以'*'开头,后面跟一个数字,表示数组长度
【客户端->服务器】
客户端向服务器发送的指令只有多行字符串数组。比如set author codehole
会以以下形式发送给服务器:
【服务器->客户端】
服务器向客户端的回复包含了RESP中规定的5种类型,这里举一个嵌套的例子,如图
返回值应如下所示(中间太多省略):
【小结】
可以看到,Redis协议里有大量冗余的回车换行符,但这不影响它成为一个受欢迎的文本协议,简单、易懂、易实现。
--拓展内容:实现一个RESP编码与解码器需要考虑的问题和思路--
【client to server:半包问题与重复反序列化】
所谓半包问题是指一次Read调用从套件字读到的字节数组可能只是一个完整消息的一部分。而另外一部分则需要发起另外一次Read调用才可能读到,甚至要发起多个Read调用才可以读到完整的一条消息。
如果我们拿部分消息去反序列化成输入消息对象肯定是要失败的,或者说生成的消息对象是不完整填充的。这个时候我们需要等待下一次Read调用,然后将这两次Read调用的字节数组拼起来,尝试再一次反序列化。
问题来了,如果一个输入消息对象很大,就可能需要多个Read调用和多次反序列化操作才能完整的解包出一个输入对象。那这个反序列化的过程就会重复了多次。比如第一次完成了30%,然后第二次从头开始又完成了60%,第三次又从头开始完成了90%,第四次又从头开始总算完成了100%,这下终于可以放心交给业务处理器处理了。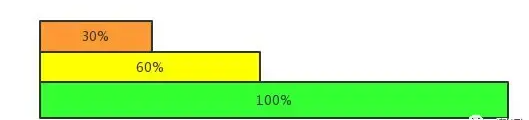
Netty使用ReplayingDecoder引入检查点机制[Checkpoint]解决了这个重复反序列化的问题。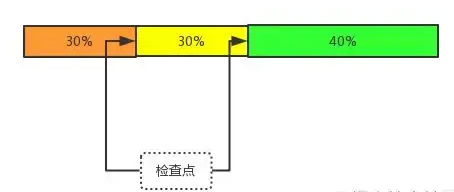
【server to client:支持多种结构】
输出消息的结构要复杂很多,要支持多种数据类型,包括状态、整数、错误、字符串和数组,要支持数据结构嵌套,数组里还有数组。相比解码器而言它简单的地方在于不用考虑半包问题,编码器只负责将消息序列化成字节流,剩下的事由Netty偷偷帮你搞定。
【参考】
《Redis深度历险 核心原理与应用实践》
https://juejin.cn/post/6844903577459113998