知乎: 阿里巴巴公司根据截图查到泄露信息的具体员工的技术是什么?
阿里巴巴公司通过截图,根据肉眼无法识别的标识码追踪到泄露信息的具体员工……
阿里月饼事件中的新闻中提到“泄露内部信息丢了工作,因为截图上「看不见的水印」”。那么该技术(简称“阿里水印”)的原理是什么?又能否利用Python实现呢。
1. 原理
传统的水印,是将水印直接叠加在图像上。但由于水印可见,那么通过PS等方式去除水印就很容易做到。
而阿里水印的关键,在于水印的隐藏。实际上,是把水印添加到了频域中。
频域添加数字水印的方法,是指通过某种变换手段(傅里叶变换,离散余弦变换,小波变换等)将图像变换到频域(小波域),在频域对图像添加水印,再通过逆变换,将图像转换为空间域。相对于空域手段,频域手段隐匿性更强,抗攻击性更高。
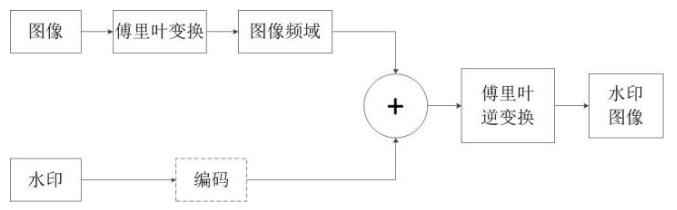
上图为叠加数字盲水印的基本流程。编码的目的有二:
- 一是对水印加密
- 二控制水印能量的分布
2. 鲁棒性: 对抗水印攻击
所谓对水印的攻击,是指破坏水印,包括涂抹,剪切,放缩,旋转,压缩,加噪,滤波等。数字盲水印不仅仅要敏捷性高(不被人抓到),也要防御性强(抗打)。
注意:数字盲水印的隐匿性和鲁棒性是互斥的。
3. Python实现
3.1. 原始图像读取
这里以Doc为例:
# %%
im = mvlib.io.imread("test/doc.png")
uu.imshow(im)
# %%
im_gray = mvlib.color.rgb2gray(im)
uu.imshow(im_gray)

3.2. 傅立叶变换
im_fft = np.fft.fft2(im_gray)
变换后,你会得到一个复数的array。
如果想审视,请调用以下代码:
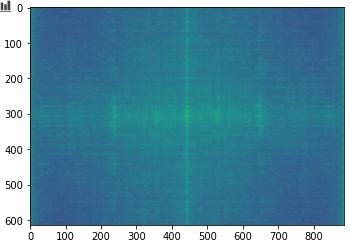
# %% 显示频域图像
fshift = np.fft.fftshift(im_fft) # 平移频谱到图像中央
# 将频谱转换成db
magnitude_spectrum = 20 * np.log(np.abs(fshift))
uu.imshow(magnitude_spectrum) # 频谱
3.3. 准备文字信息的内容
# %% 创建文字图片
im_msg = np.zeros(im_gray.shape)
# %%
from PIL import ImageFont
font = ImageFont.truetype(
"/usr/share/fonts/truetype/freefont/FreeMono.ttf",
400)
im_txt = mvlib.draw.pil_drawing(im_msg, "text", (100,100),
color="white", text="ABC", font=font)
uu.imshow(im_txt)
# %% 颜色取反
im_txt = (False == im_txt) * 255
uu.imshow(im_txt)

所谓编码,其实简单点,就是按照随机数组,打散文字信息。那么,按照这个随机数组进行逆操作,就能恢复图像的原始状态(解码)。
seq_column = list(range(im_txt.shape[0]))
seq_raw = list(range(im_txt.shape[1]))
import random
random.shuffle(seq_column)
random.shuffle(seq_raw)
im_random = im_txt.copy()
im_tmp = im_txt.copy()
for idx, i in enumerate(seq_column):
im_tmp[idx, ...] = im_txt[i, ...]
for idx, i in enumerate(seq_raw):
im_random[..., idx] = im_tmp[..., i]
uu.imshow(im_random)
第一阶段,被打散的raws:

第二阶段,打散的columns:

实际上,这个问题整复杂了,直接使用 random.seed() 添加种子,即可获取到固定的随机列表,而无需把随机序列存储起来。
不过,目前这个版本看起来更容易理解,就暂时不做修改了。
3.4. 在频域合并图像
合并后,使用逆傅立叶函数,恢复时域图像
im_txt_fft = np.fft.fft2(im_random)
im_merge = im_fft + im_txt_fft * 0.1
im_ifft = np.fft.ifft2(im_merge).real
uu.imshow(im_ifft)
图像看起来会多了一些噪点,如果控制的好,可以做到肉眼无差别。这里为了体现噪点,放大了系数,效果如下图:
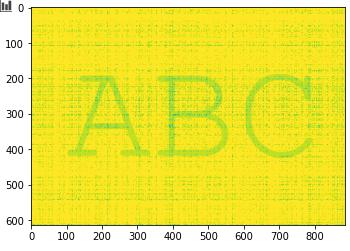
3.5. 解码
接下来就是解码的过程,提取info信息。
通过傅立叶变换到频域,然后过滤掉原图的fft频域值,即获得了文字图像的频域图。这个图再恢复到时域,及打乱了状态的那个“散点图”。
按照之前random的编码规则逆向运行,即可恢复原文字图像。
im_fft2 = np.fft.fft2(im_ifft)
im_txt_random = (im_fft2 - im_fft) * 10
im_random2 = np.fft.ifft2(im_fft2).real
# %% 编码的恢复
im_recover = im_random2.copy()
for idx, i in enumerate(seq_raw):
im_tmp[..., i] = im_random2[..., idx]
for idx, i in enumerate(seq_column):
im_recover[i, ...] = im_tmp[idx, ...]
uu.imshow(im_recover)
4. 后续思考
其实,添加的文字没必要这么大。或者更准确的说,没必要这么粗。点可以是那种有点镂空的虚点。
不过,个人一直无法理解,转换到频域叠加图像后在反变换,与直接在时域相加,有什么区别?或者说,有一个关键点,我还没有实现:高频嵌入或低频嵌入的选择。
5. 项目应用
推荐一个封装较为完善的实现:github链接
5.1. PDF或图像添加水印
5.2. Web页面添加水印
对于web,可以添加一个背景图片,来追踪截图者。