
[kfk@bigdata-pro01 softwares]$ sudo rpm -ivh nc-1.84-22.el6.x86_64.rpm Preparing... ########################################### [100%] 1:nc ########################################### [100%] [kfk@bigdata-pro01 softwares]$

重新启用一个远程连接窗口
bin/run-example streaming.NetworkWordCount localhost 9999

回到这边输入一些信息
看到这边就有数据接收到了
我们退出,换个方式启动
我们在这边再输入一些数据

这边处理得非常快

因为打印的日志信息太多了,我修改一下配置文件(3个节点都修改吧,保守一点了)
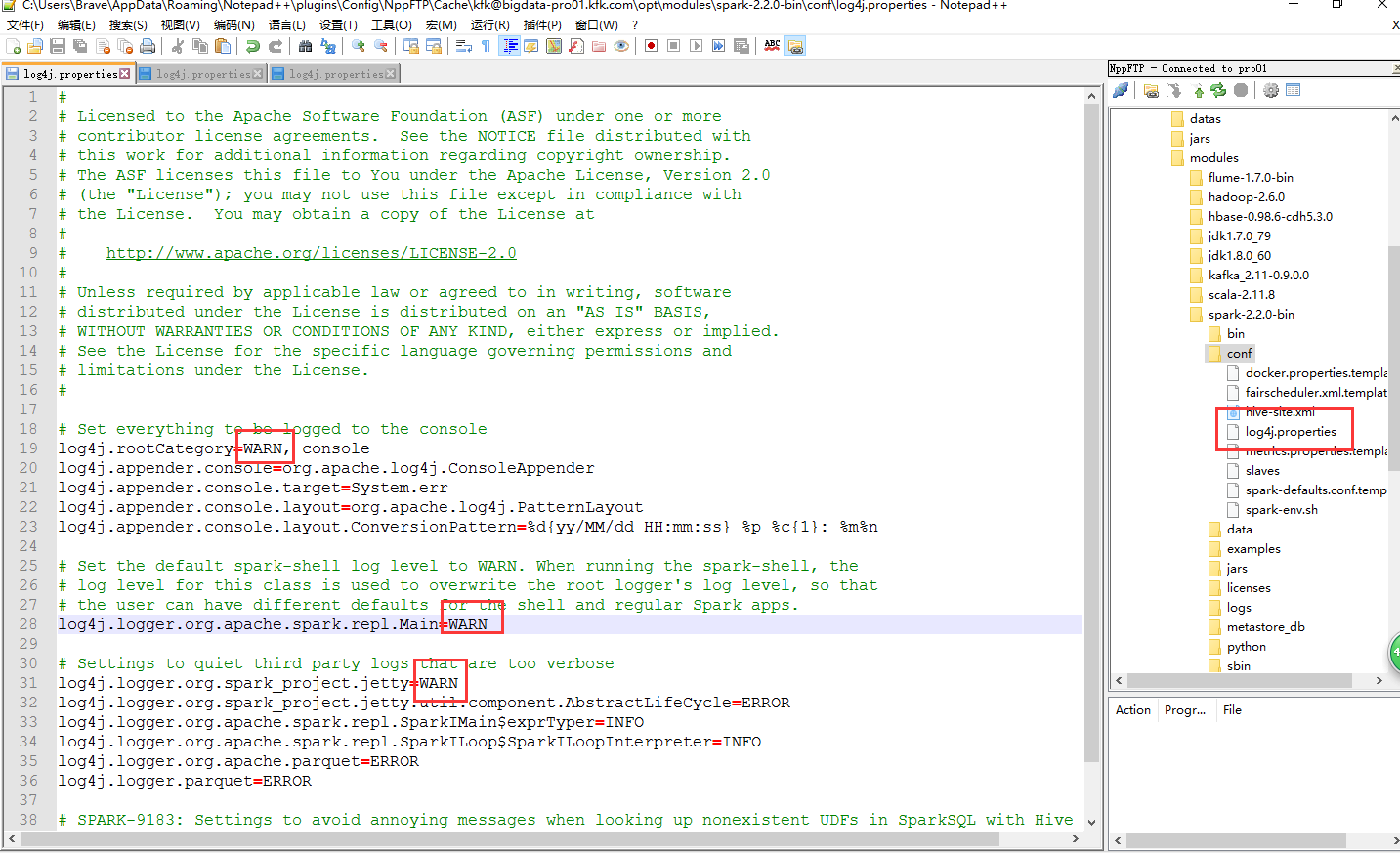
我们在来跑一下

再回到这边我们敲几个字母进去

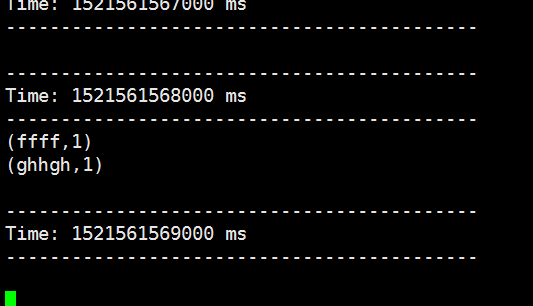
把同样的单词多次输入我们看看是什么结果
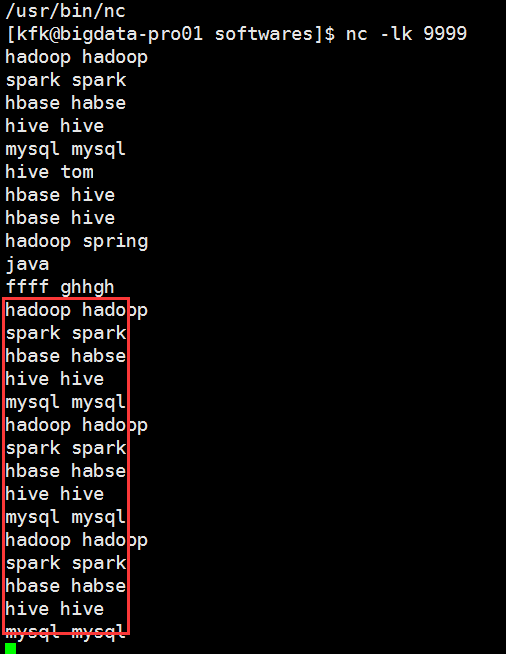
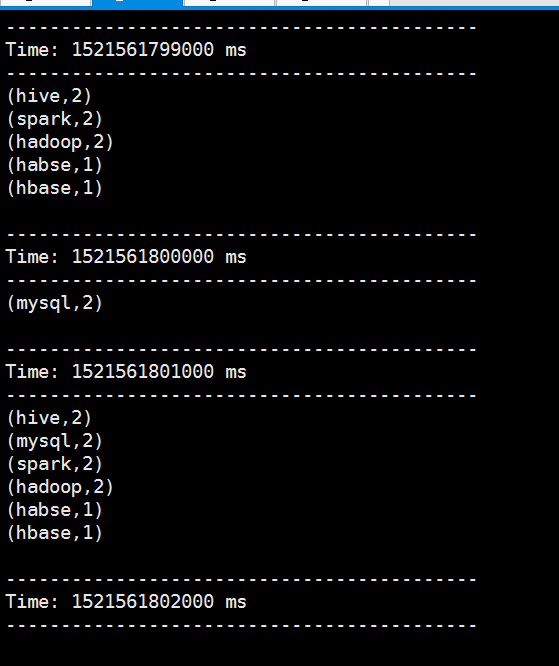
可以看到他会统计
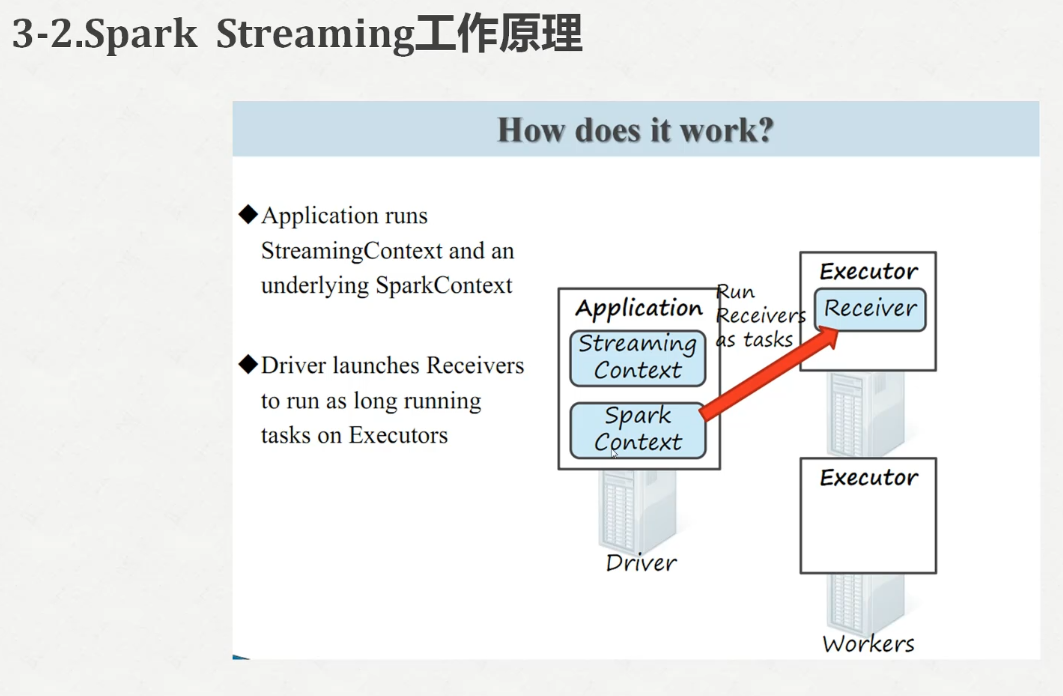





我们启动一下spark-shell,发现报错了

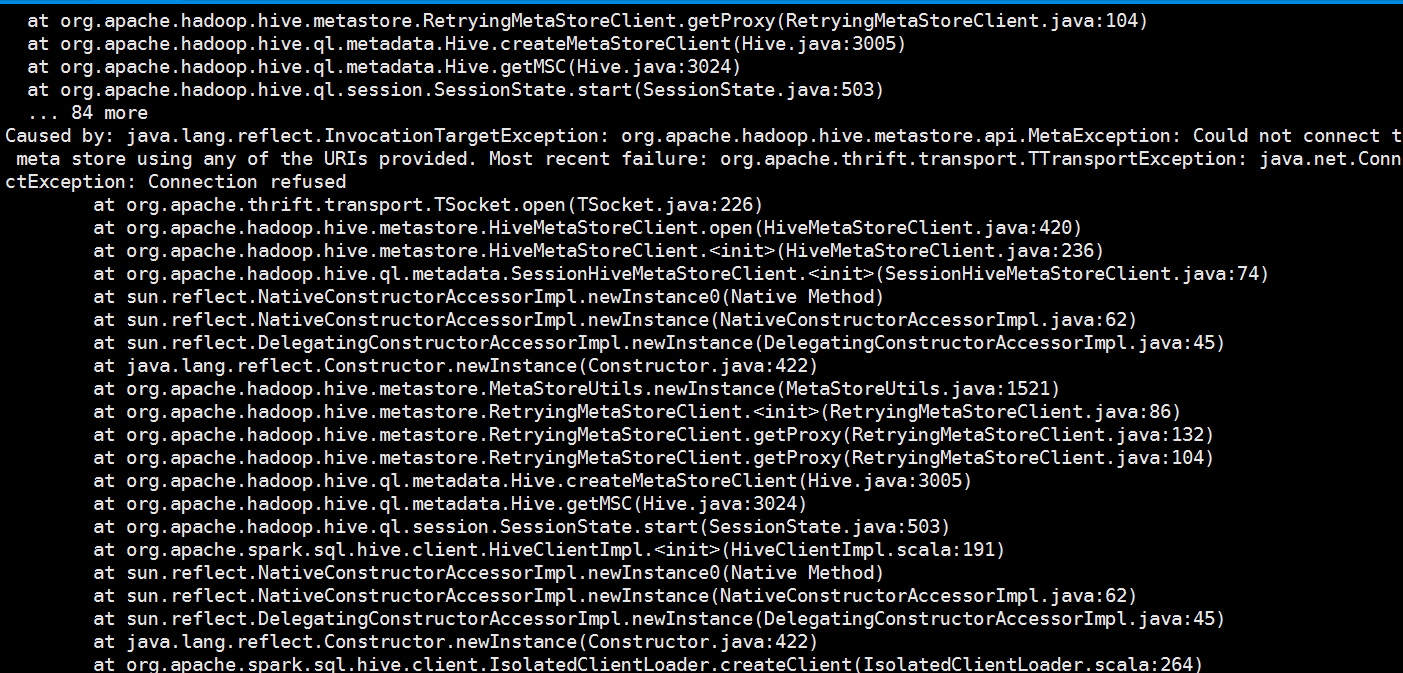
是因为我们前面配置了hive到spark sql 里面,我们先配回来(3个节点都修改)


再启动一下

我们输入代码

scala> import org.apache.spark.streaming._ import org.apache.spark.streaming._ scala> import org.apache.spark.streaming.StreamingContext._ import org.apache.spark.streaming.StreamingContext._ scala> val ssc = new StreamingContext(sc, Seconds(5)) ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@431f8830 scala> val lines = ssc.socketTextStream("localhost", 9999) lines: org.apache.spark.streaming.dstream.ReceiverInputDStream[String] = org.apache.spark.streaming.dstream.SocketInputDStream@23f27434 scala> val words = lines.flatMap(_.split(" ")) words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@2c3df478 scala> val pairs = words.map(word => (word, 1)) pairs: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.MappedDStream@6d3dc0c5 scala> val wordCounts = pairs.reduceByKey(_ + _) wordCounts: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@8fa4647 scala> wordCounts.print() scala>
最后启动一下服务发现报错了
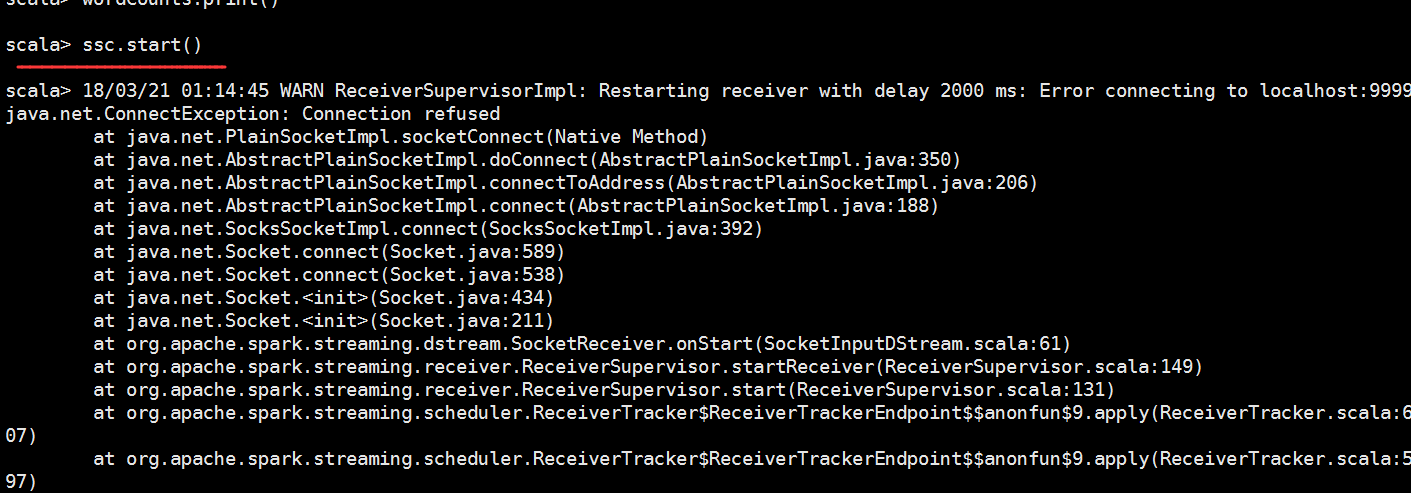
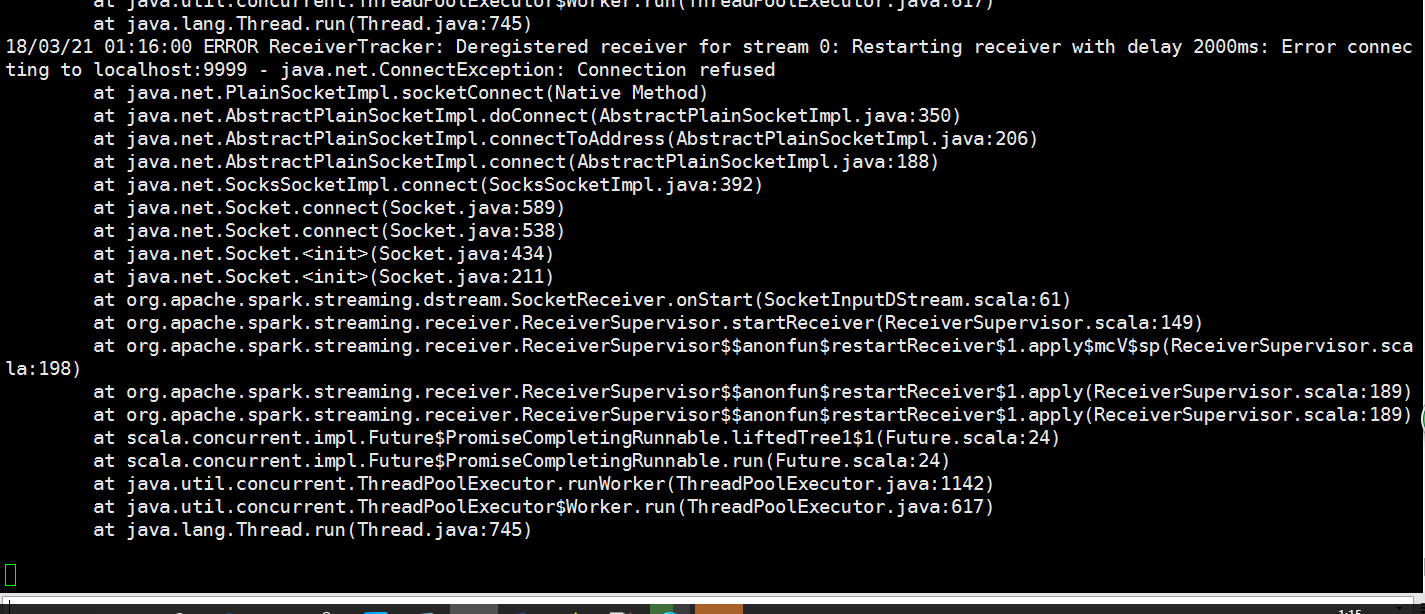
是因为没有启动nc
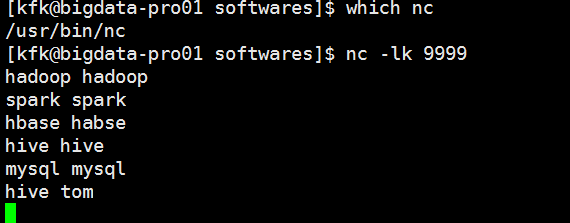
现在把他启动

我们敲进去一些数据


退出再启动一次

再次把代码放进来


我们在nc那边输入数据

回到这边看看结果

打开我们的idea



package com.spark.test import org.apache.spark.sql.SparkSession import org.apache.spark.streaming._ import org.apache.spark.streaming.StreamingContext._ import org.apache.spark.{SparkConf, SparkContext} object Test { def main(args: Array[String]): Unit = { val spark= SparkSession .builder .master("local[2]") .appName("HdfsTest") .getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds(5)); val lines = ssc.socketTextStream("localhost", 9999) val words = lines.flatMap(_.split(" ")) } }






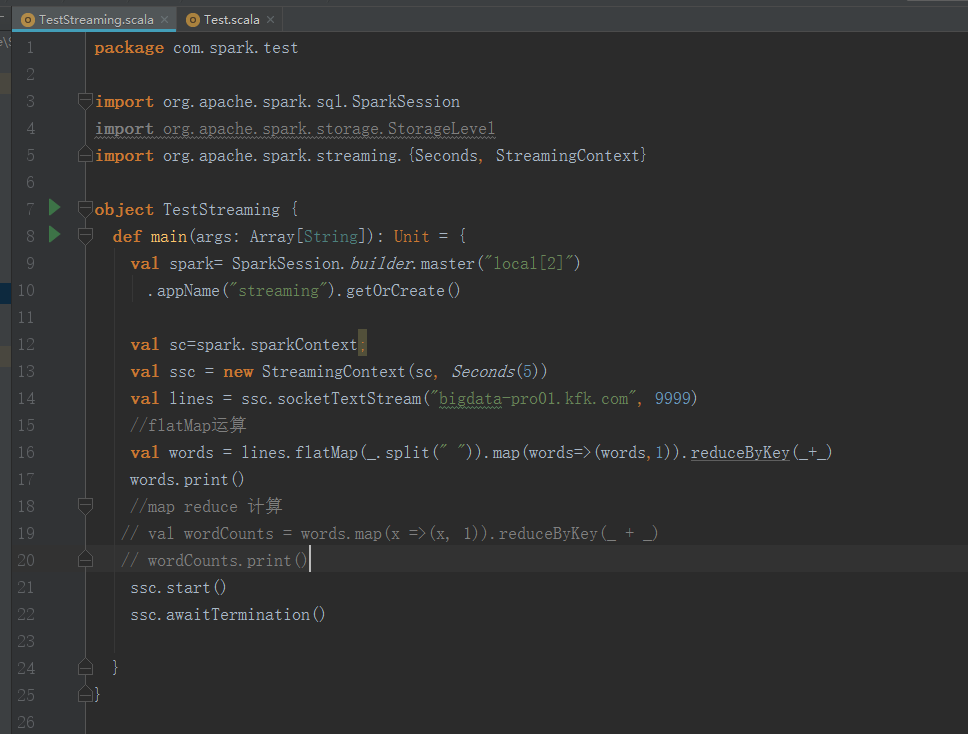
package com.spark.test import org.apache.spark.sql.SparkSession import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.{Seconds, StreamingContext} object TestStreaming { def main(args: Array[String]): Unit = { val spark= SparkSession.builder.master("local[2]") .appName("streaming").getOrCreate() val sc=spark.sparkContext; val ssc = new StreamingContext(sc, Seconds(5)) val lines = ssc.socketTextStream("bigdata-pro01.kfk.com", 9999) //flatMap运算 val words = lines.flatMap(_.split(" ")).map(words=>(words,1)).reduceByKey(_+_) words.print() //map reduce 计算 // val wordCounts = words.map(x =>(x, 1)).reduceByKey(_ + _) // wordCounts.print() ssc.start() ssc.awaitTermination() } }



这个过程呢要这样操作,先把程序运行,再启动nc,再到nc界面输入单词

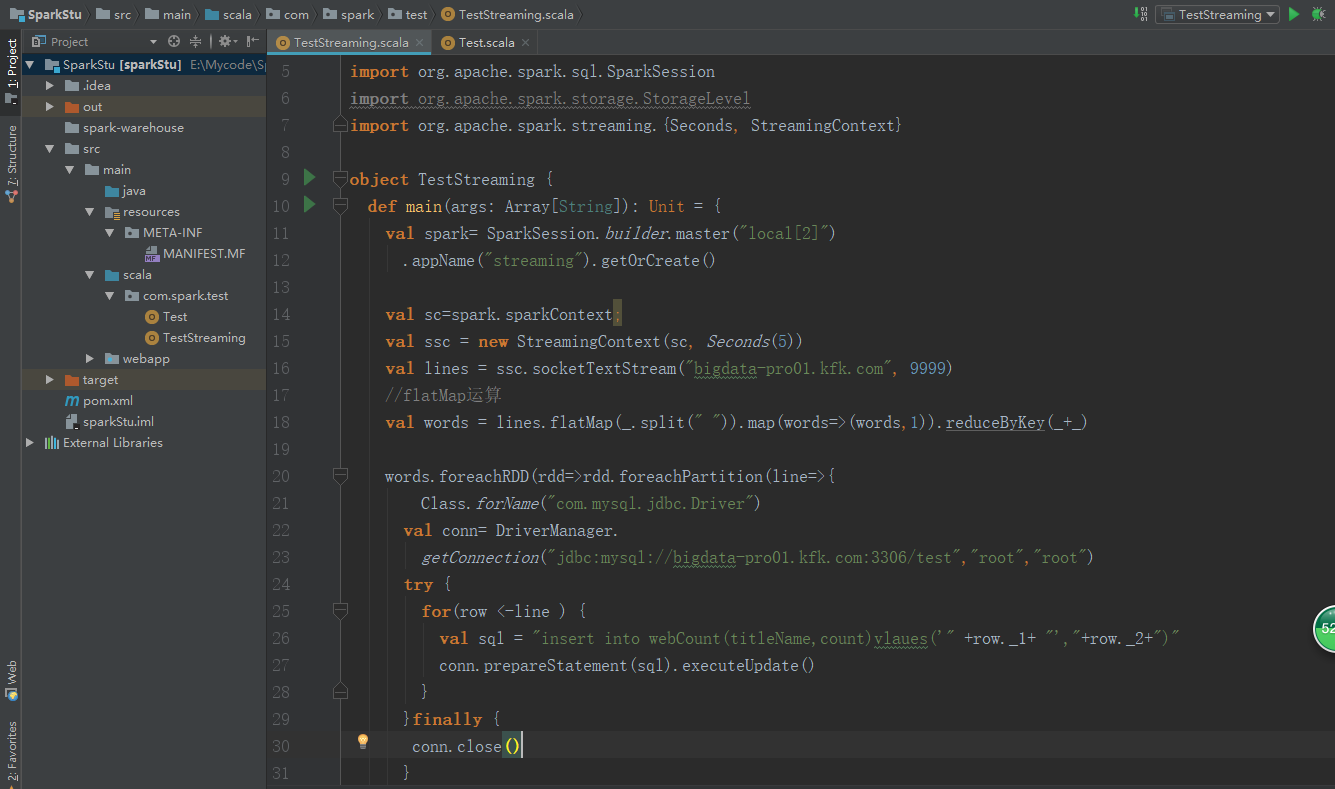
package com.spark.test import java.sql.DriverManager import org.apache.spark.sql.SparkSession import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.{Seconds, StreamingContext} object TestStreaming { def main(args: Array[String]): Unit = { val spark= SparkSession.builder.master("local[2]") .appName("streaming").getOrCreate() val sc=spark.sparkContext; val ssc = new StreamingContext(sc, Seconds(5)) val lines = ssc.socketTextStream("bigdata-pro01.kfk.com", 9999) //flatMap运算 val words = lines.flatMap(_.split(" ")).map(words=>(words,1)).reduceByKey(_+_) words.foreachRDD(rdd=>rdd.foreachPartition(line=>{ Class.forName("com.mysql.jdbc.Driver") val conn= DriverManager. getConnection("jdbc:mysql://bigdata-pro01.kfk.com:3306/test","root","root") try { for(row <-line ) { val sql = "insert into webCount(titleName,count)values('" +row._1+ "',"+row._2+")" conn.prepareStatement(sql).executeUpdate() } }finally { conn.close() } })) words.print() //map reduce 计算 // val wordCounts = words.map(x =>(x, 1)).reduceByKey(_ + _) // wordCounts.print() ssc.start() ssc.awaitTermination() } }

我们把代码拷进来

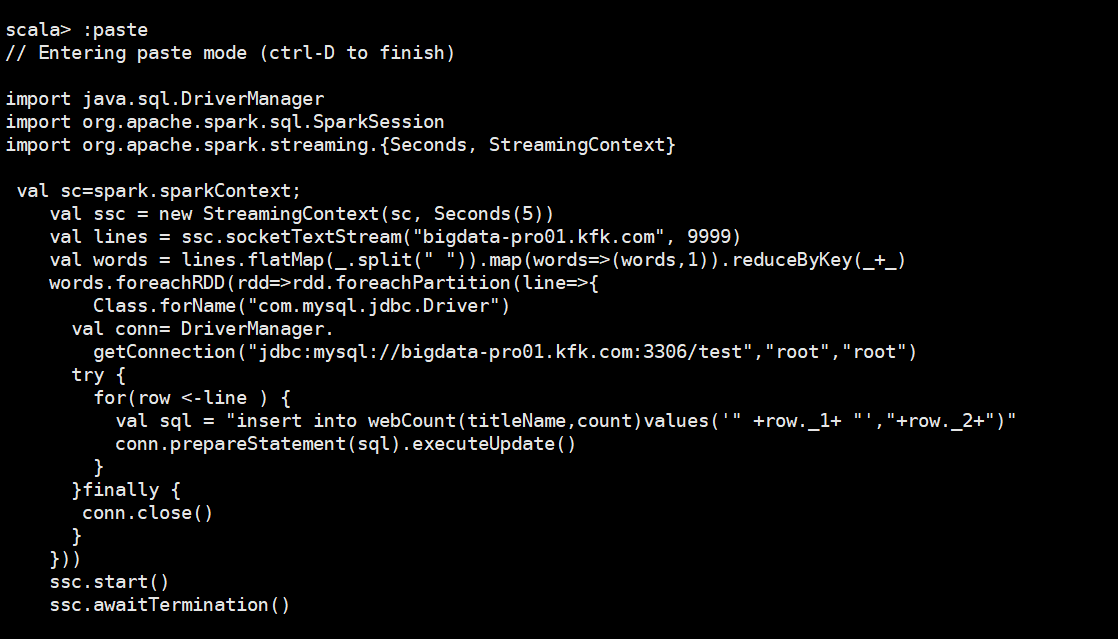
import java.sql.DriverManager import org.apache.spark.sql.SparkSession import org.apache.spark.streaming.{Seconds, StreamingContext} val sc=spark.sparkContext; val ssc = new StreamingContext(sc, Seconds(5)) val lines = ssc.socketTextStream("bigdata-pro01.kfk.com", 9999) val words = lines.flatMap(_.split(" ")).map(words=>(words,1)).reduceByKey(_+_) words.foreachRDD(rdd=>rdd.foreachPartition(line=>{ Class.forName("com.mysql.jdbc.Driver") val conn= DriverManager. getConnection("jdbc:mysql://bigdata-pro01.kfk.com:3306/test","root","root") try { for(row <-line ) { val sql = "insert into webCount(titleName,count)values('" +row._1+ "',"+row._2+")" conn.prepareStatement(sql).executeUpdate() } }finally { conn.close() } })) ssc.start() ssc.awaitTermination()
我们输入数据

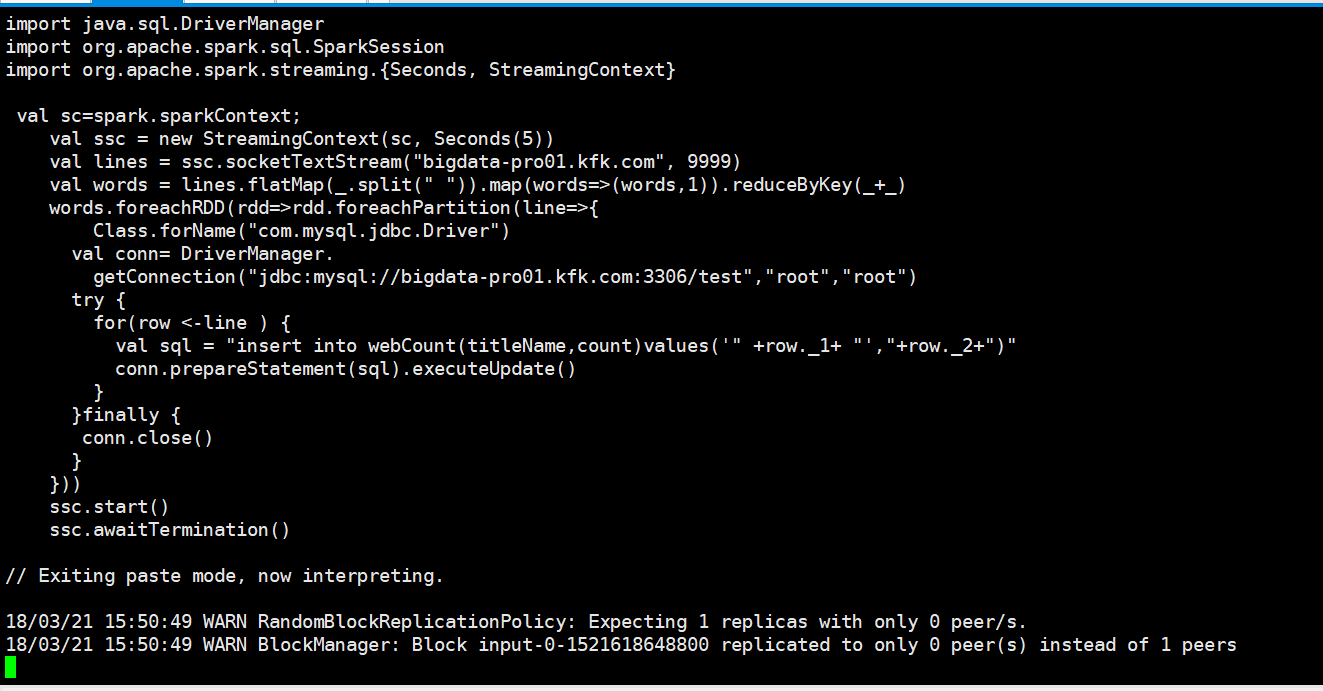
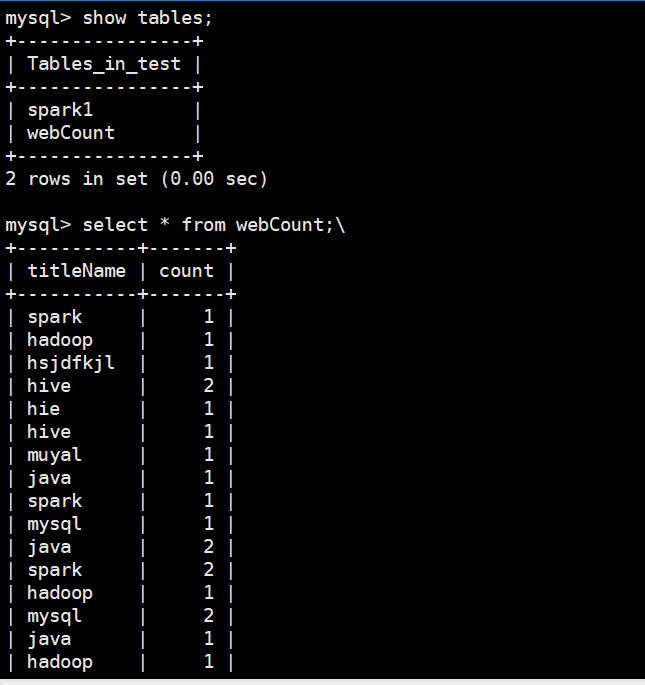
我们通过mysql查看一下表里面的数据