
Flume是什么

1.flume可以将采集到的数据存储到HDFS上,也可以放在Hbase上。
2.flume就是一个中间插件,他的作用就是屏蔽数据源和数据存储系统的差异。可以在不同的数据源采集数据,因为数据源是多样化的。
数据源的多样化和数据存储系统的多样化,flume作为一个中间插件把数据源和存储系统实现多对多的关系。
Flume的优点

Flume OG与NG区别

Flume NG基本架构
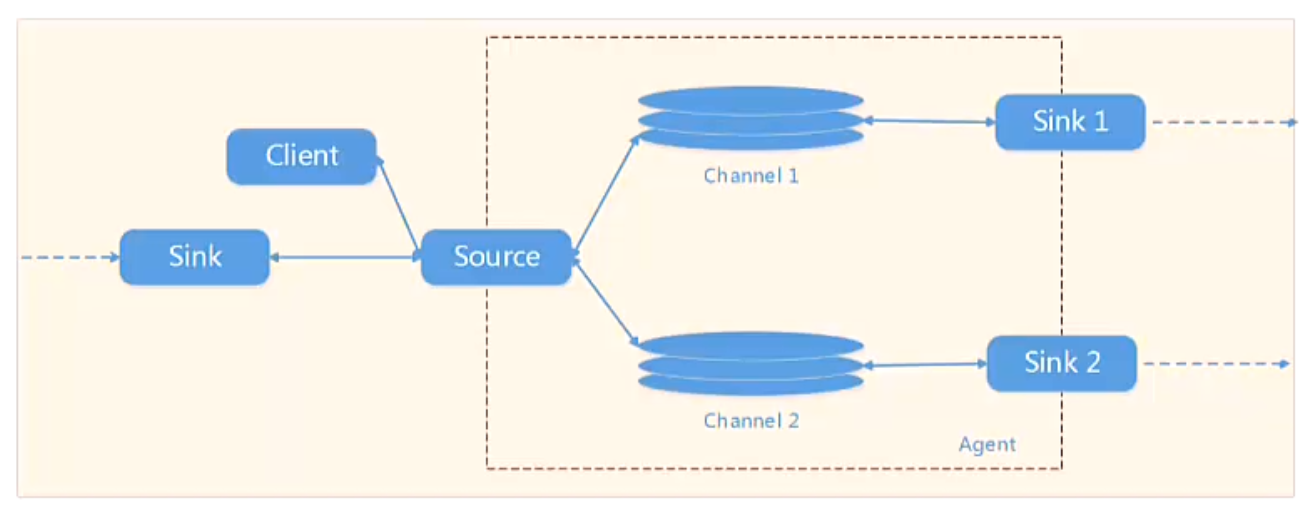
1.Agent由Source 、 channel sink组成。
2.Source是用来获取数据,可以从文本文件中和系统日志中和HTTP中获取数据。Source 获取数据传给后面的Agent
3.channel 在source sink之间作为数据的缓存,sink的数据不能及时传输出去,可以讲数据缓存的内存或者磁盘上面,数据缓存在内存和磁盘中是不同的,在内存中断电了数据就丢失,磁盘的就不会。
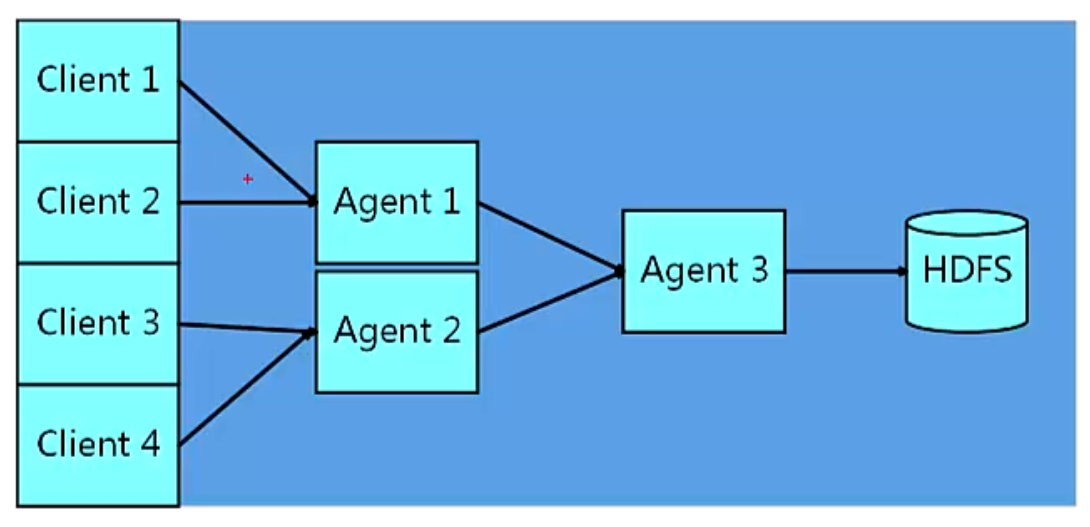
1.Agent3也是可以去掉的,不过在这里起到缓冲的过程。比如说Agent3前面的agent个数非常多,没有经过Agent3的汇总,将会有大量的小文件直接写到HDFS上,非常不利于存储,
因为我们知道HDFS适合存储大文件而不适合大量的小文件。
2.当然如果数据量不大的话就不需要Agent3这样的多级Agent了,根据实际情况来选择适合的方式。
Flume NG核心概念

Flume NG核心概念--Event

Flume NG核心概念--Client

Flume NG核心概念--Agent

Flume NG核心概念--Source
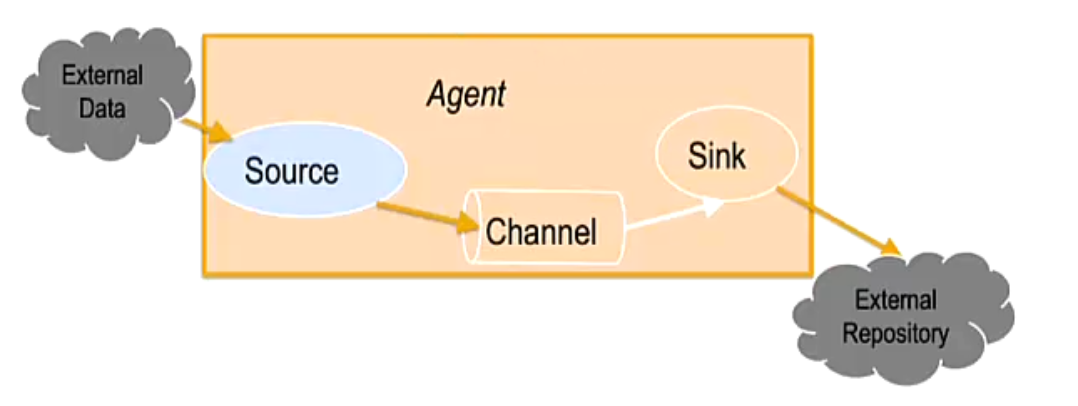

Flume NG核心概念--channel和 sink
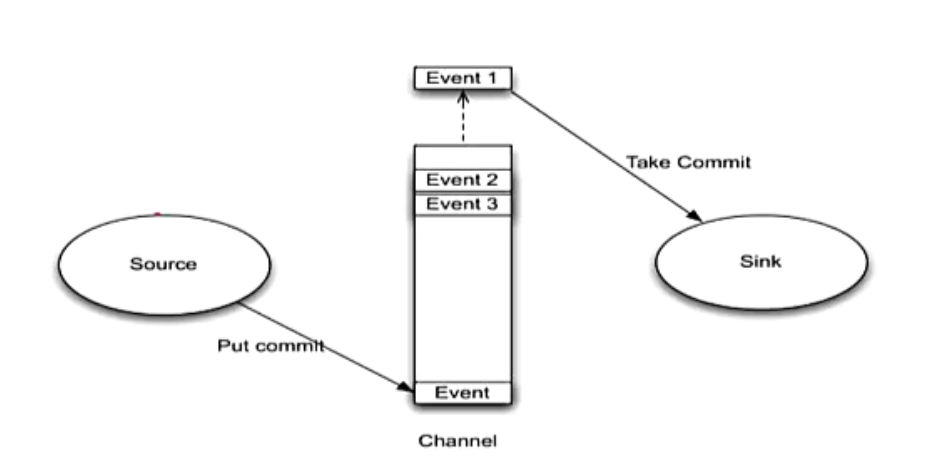
Flume NG核心概念--channel

磁盘channel 是通过预写日志的方式来实现,就是在数据写成功之前先写log,日志写成后我们就任务数据写成功了,如果日志写成功了,数据没写成功,重启之后我们可以通过这个日志来恢复数据
Flume NG核心概念--sink
