



前面讲到的海量数据存储分析:

为什么需要hive:

思考一下用什么来封装!

传统的数据仓库是通过sql语言存储在传统的关系型数据库里面的,hive的数据仓库是通过hql语言存储在HDFS上的,也就是说hive通过hql语言转换成mapreduce来对hdfs数据进行分析。
hive就是通过hql语言对maprduce进行封装。



在使用hive前,先把集群启动,mysql数据库启动,再来启动hive。

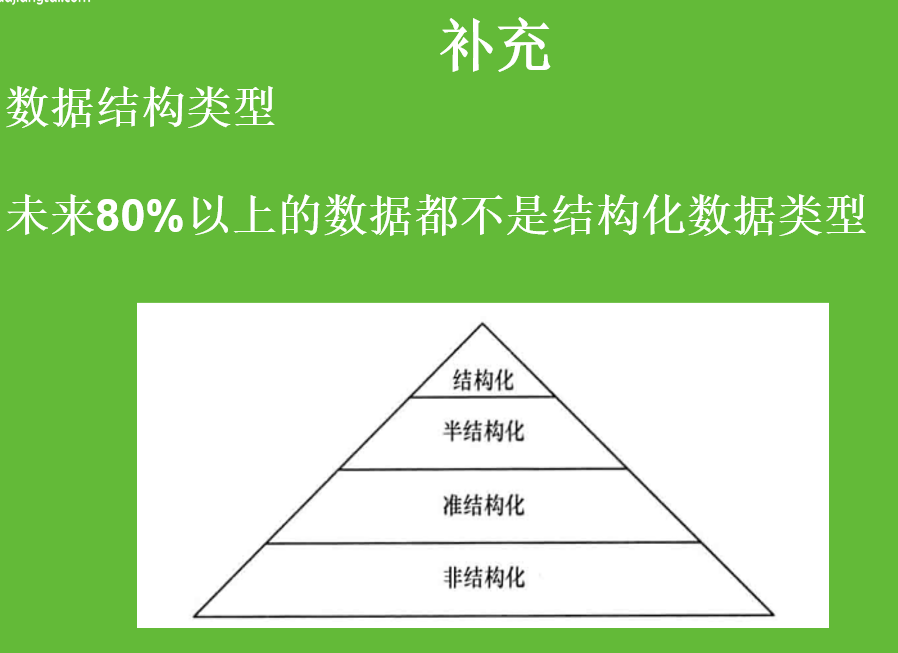





业务数据库都是为了读写性能优化的,比如说平时我们网购下订单,或者去银行取钱转账等等,这个就需要读写的速度够快。但是业务数据库的缺点就是读写快速是针对比较小量的数据。
当对大量数据的读写就达不到速度的要求了,这个时候就需要单独部署数据仓库来解决这个问题了,数据仓库就是为了分析性能儿设置的,对读的优化更好。


hive的安装

以下是某个民间高手在安装hive的时候的总结:


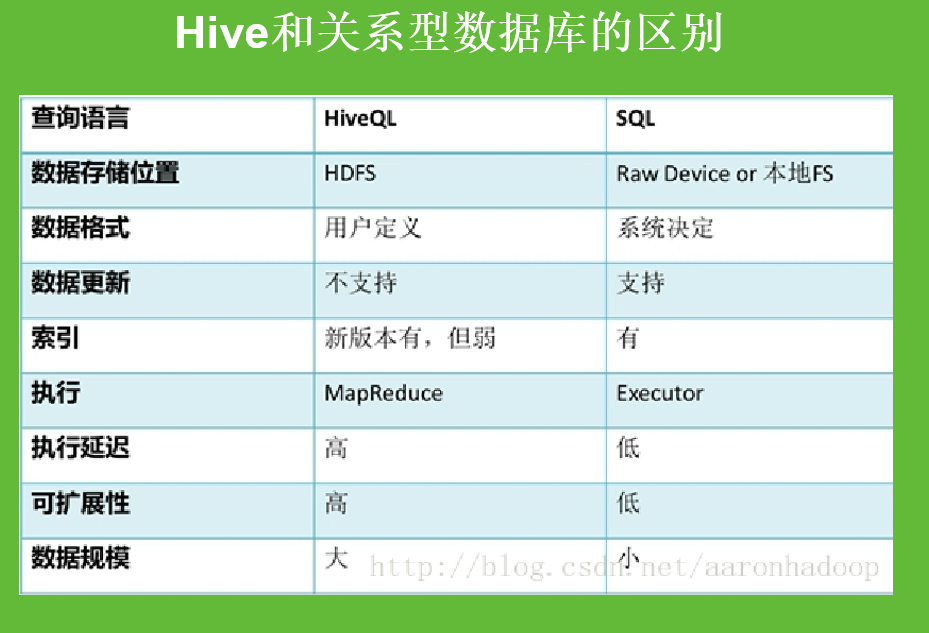
这里重点说下数据格式问题:SQL的是写时模式,当用户往里面写数据时,系统会对照数据的格式是不是一致的,如果是的话就会加载进来,否则就拒绝加载进来。
读时模式就是数据加载进来的时候不管你的格式,当需要读取数据的时候就对格式进行检查了,看看数据格式是不是跟我表里面的格式一样的,如果不一样就会查询不出来或者报一些错误。
写时模式的特点就是写的时候数据需要检查就会耗费的时间比较多相对较慢,读的时候就很快。
读时模式在写人数据的时候是不管数据格式的所以比较快,而在读数据的时候需要核对数据格式所以读取速度较慢。
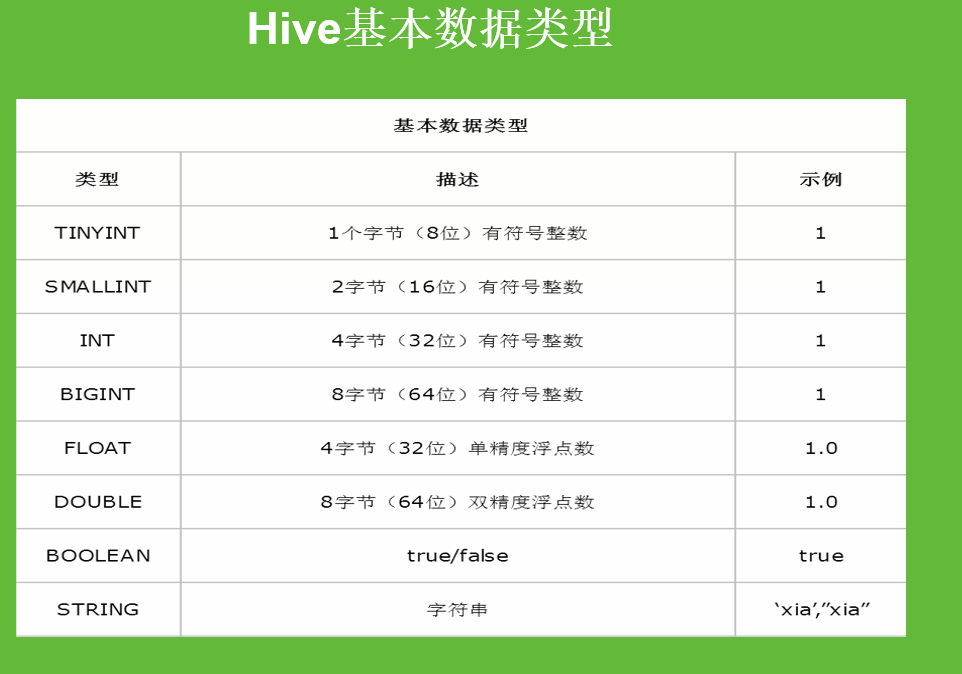


显式转换举一个经典例子,比如说字符类型串“hello”不能转换成int类型。转换也要符合常理。
这里需要注意的是,因为我们要处理的数据是大数据,所以尽量不要用隐式转换,如果大量数据都用了隐社转换那么消耗的资源将非常大,所以需要转换时就用显式转换。
在集群里启动一下
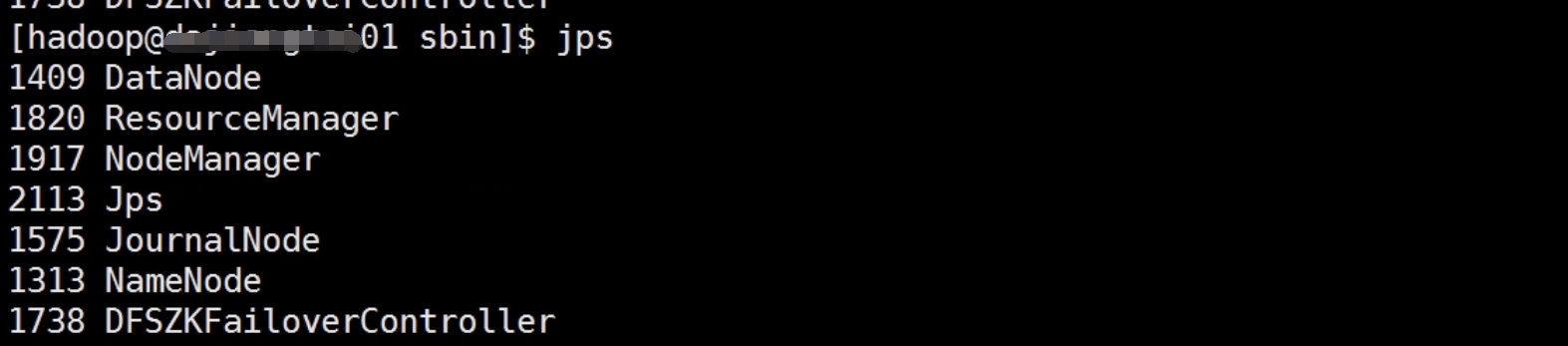
查看进程发现少个zookeeper进程!

查看日志
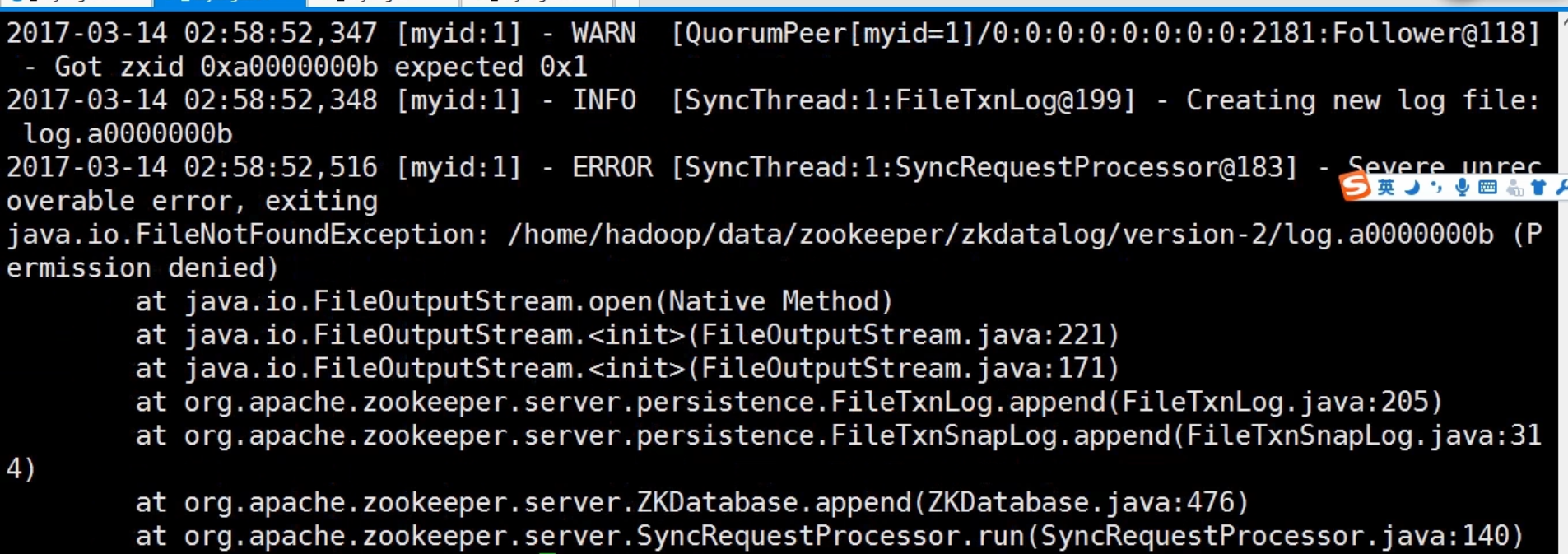

可以看到是权限的问题!下面我们修改一下权限
查看这个文件的权限是root权限,因为我们使用的是hadoop用户,所以要修改成hadoop权限

修改权限

重新启动一下集群zookeeper的进程启动了,具体怎么启动和关闭进程这里就不多说了

现在启动一下hive

可以看到报错了!!!!
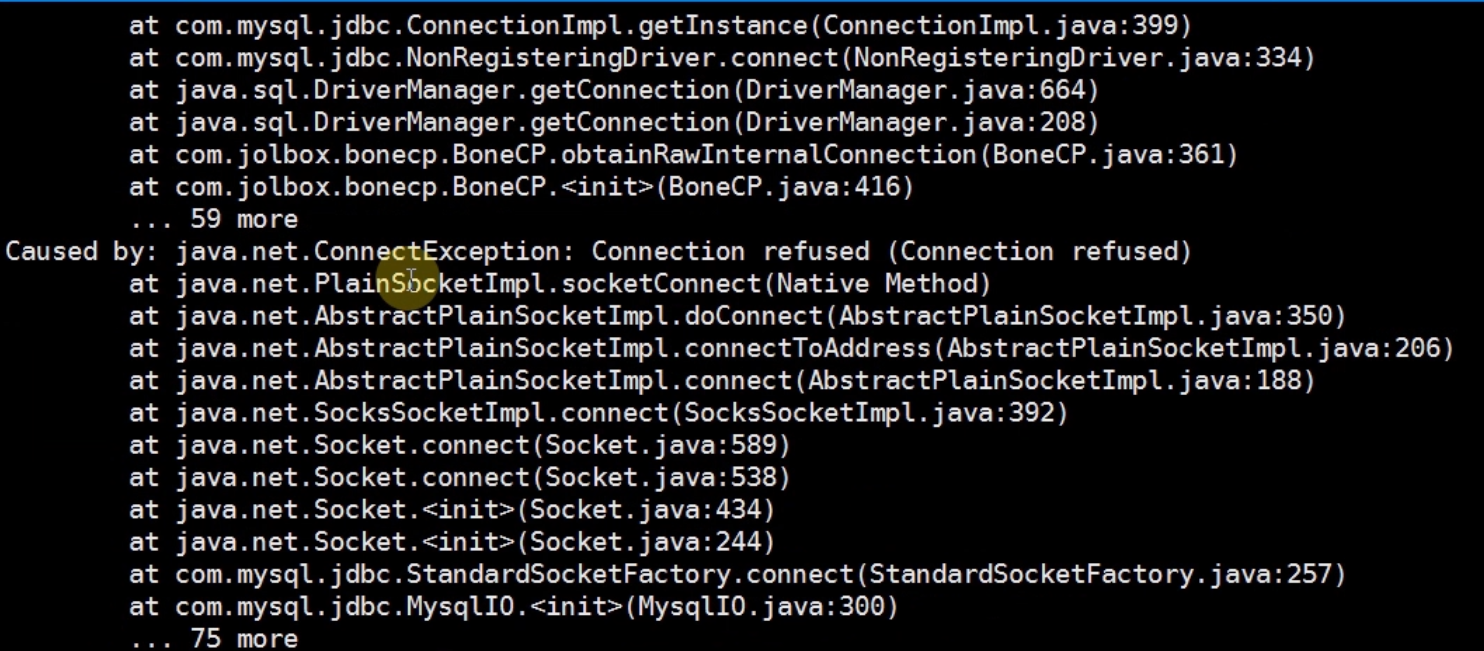
是因为mysql服务没有启动的原因,这也是很多人容易犯的毛病。
启动一下mysql服务

再次启动hive,成功了!
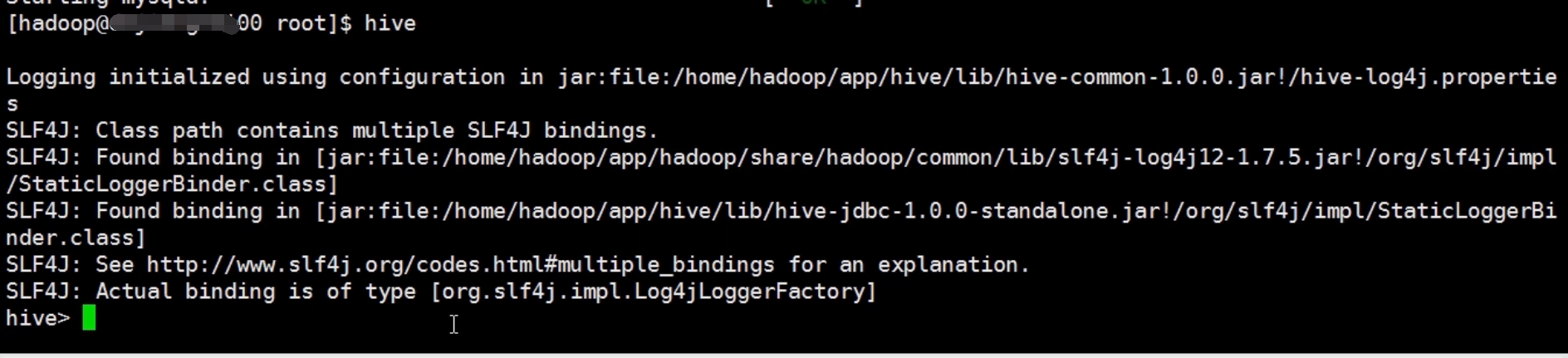
在hive里创建表
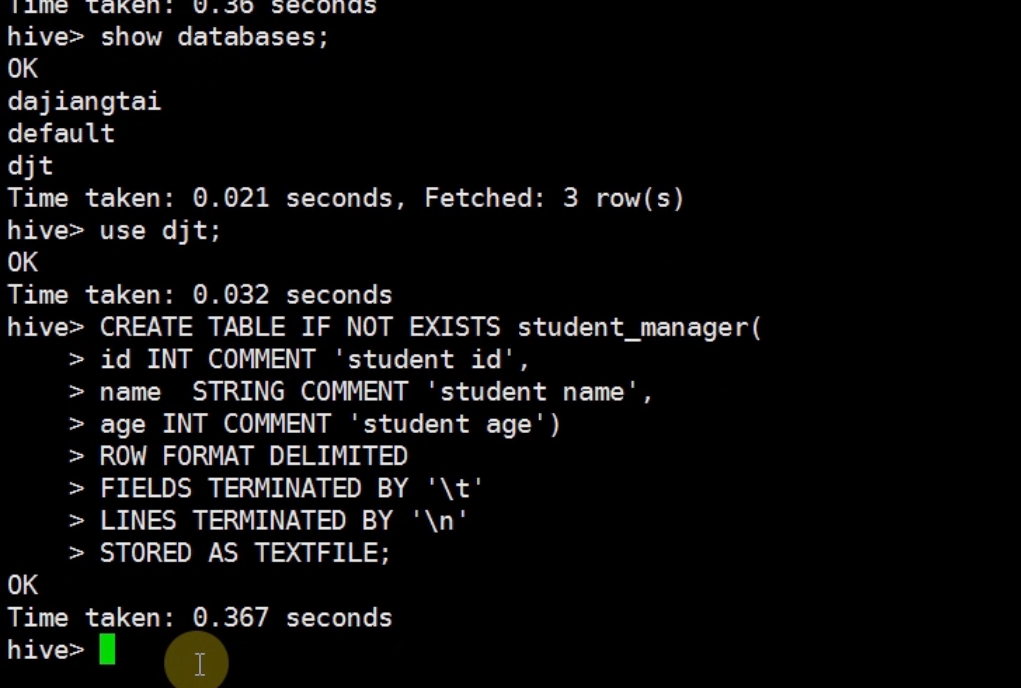
在HDFS下查看表是否创建成功

这里补充一个知识点,就是内部表和外部表,内部表就是在你删除表的时候会把表和数据一起删除掉,而外部表呢当你把他删除的时候只是删除表的结构,源数据没有被删除掉。
源数据:源数据就是存放在mysql数据库里面的。
先登录mysql数据库
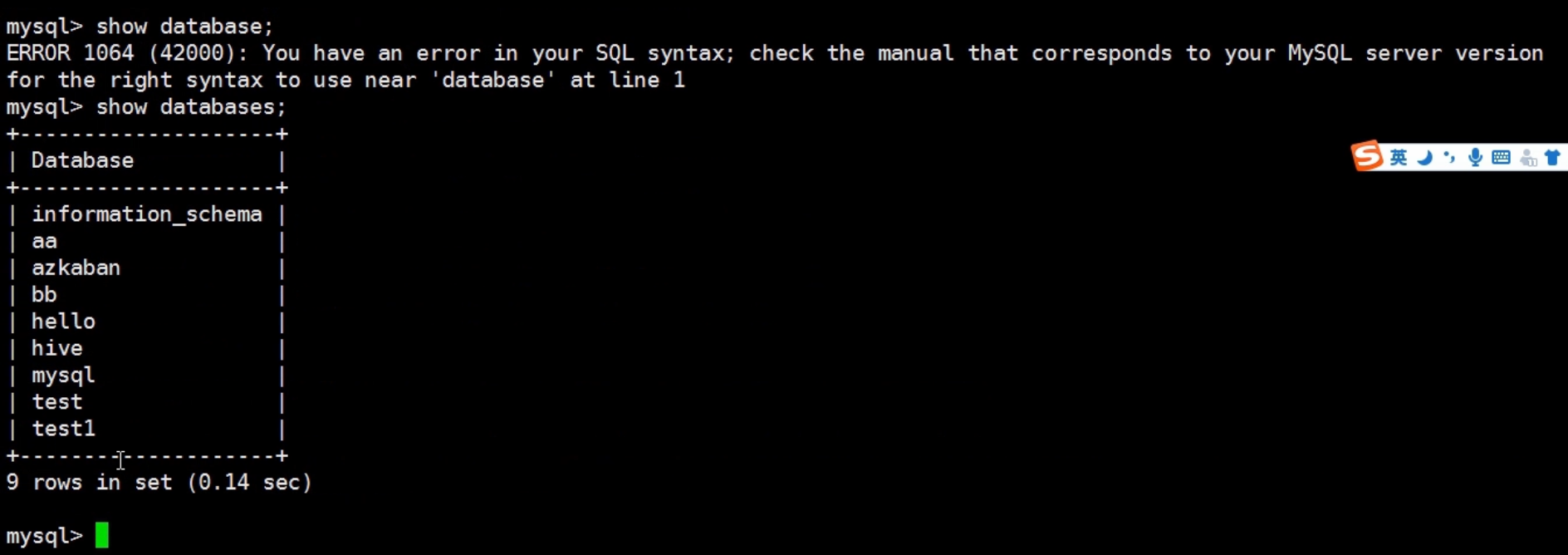
查看mysql里面创建的数据库有哪些
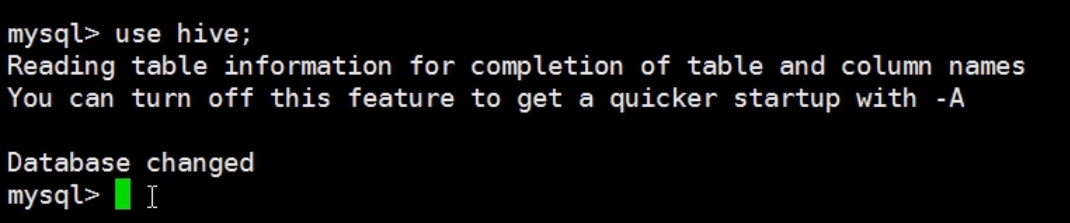
因为我们的源数据都放在hive数据库里面,所以我们先切换到hive数据库里面
查看hive数据库里面的表
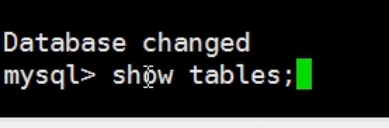
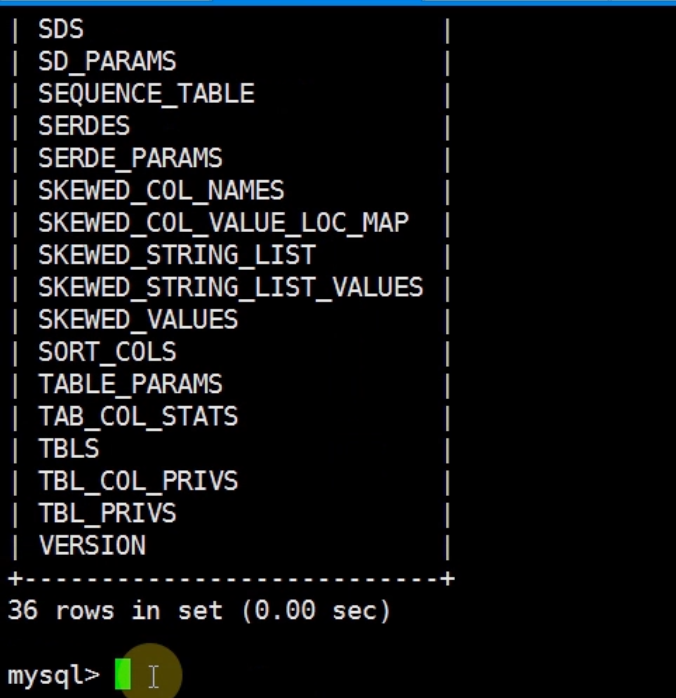
查看表的一些信息

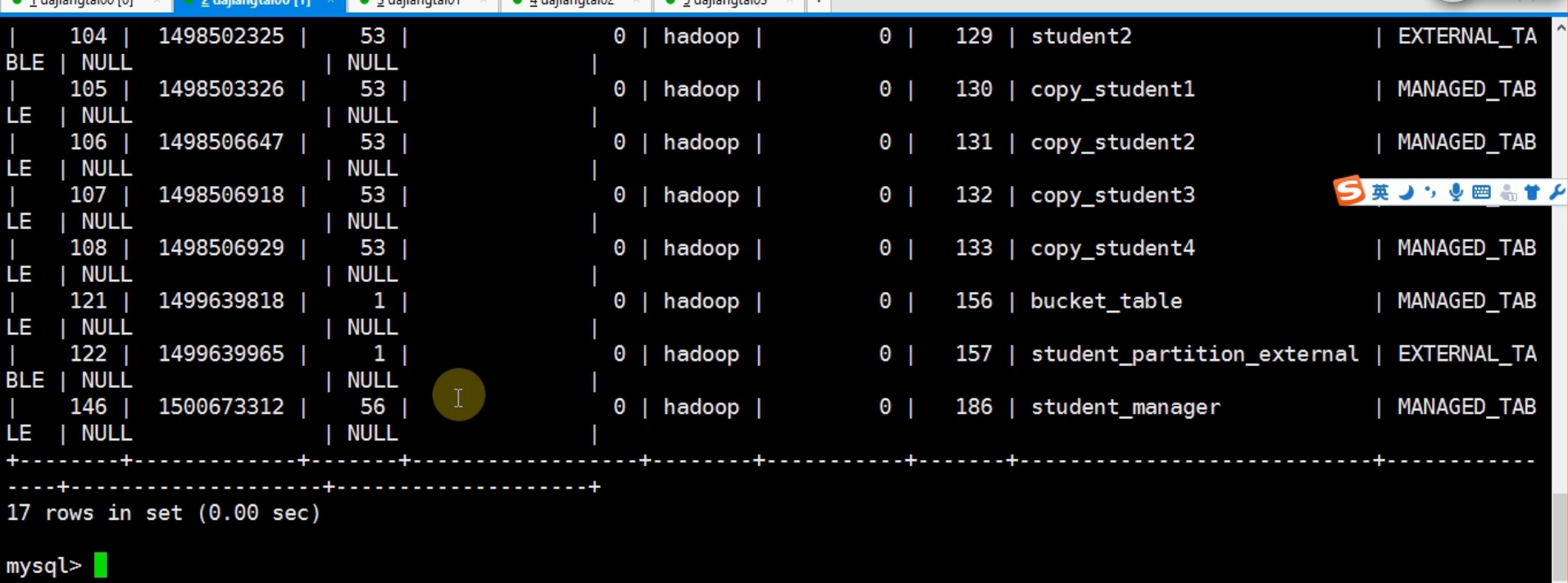
student_manager表是内部表
回到hive下把这个表删除了

删除之后到mysql界面下查看一下,可以看到不见了
