参考代码
TVPlayCount.java
package com.dajiangtai.hadoop.tvplay; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import com.sun.org.apache.bcel.internal.generic.NEW; public class TVPlayCount extends Configured implements Tool{ public static class TVPlayMapper extends Mapper<Text, TVPlayData, Text, TVPlayData>{ @Override protected void map(Text key, TVPlayData value,Context context) throws IOException, InterruptedException { context.write(key, value); } } public static class TVPlayReducer extends Reducer<Text, TVPlayData, Text, Text> { private Text m_key=new Text(); private Text m_value = new Text(); private MultipleOutputs<Text, Text> mos; //将多路输出打开 protected void setup(Context context) throws IOException,InterruptedException { mos = new MultipleOutputs<Text, Text>(context); } protected void reduce (Text Key,Iterable<TVPlayData> Values, Context context) throws IOException, InterruptedException{ int daynumber = 0; int collectnumber = 0; int commentnumber = 0; int againstnumber = 0; int supportnumber = 0; for (TVPlayData tv : Values){ daynumber+=tv.getDaynumber(); collectnumber+=tv.getCollectnumber(); commentnumber += tv.getCommentnumber(); againstnumber += tv.getAgainstnumber(); supportnumber += tv.getSupportnumber(); } String[] records=Key.toString().split(" "); // 1优酷 2搜狐 3 土豆 4爱奇艺 5迅雷看看 String source =records[1]; // 媒体类别 m_key.set(records[0]); m_value.set(daynumber+" "+collectnumber+" " +commentnumber+" "+againstnumber+" "+supportnumber); if(source.equals("1")){ mos.write("youku", m_key, m_value); }else if (source.equals("2")) { mos.write("souhu", m_key, m_value); } else if (source.equals("3")) { mos.write("tudou", m_key, m_value); } else if (source.equals("4")) { mos.write("aiqiyi", m_key, m_value); } else if (source.equals("5")) { mos.write("xunlei", m_key, m_value); } } //关闭 MultipleOutputs,也就是关闭 RecordWriter,并且是一堆 RecordWriter,因为这里会有很多 reduce 被调用。 protected void cleanup( Context context) throws IOException,InterruptedException { mos.close(); } } @Override public int run(String[] args) throws Exception { Configuration conf = new Configuration(); // 配置文件对象 Path mypath = new Path(args[1]); FileSystem hdfs = mypath.getFileSystem(conf);// 创建输出路径 if (hdfs.isDirectory(mypath)) { hdfs.delete(mypath, true); } Job job = new Job(conf, "tvplay");// 构造任务 job.setJarByClass(TVPlayCount.class);// 设置主类 job.setMapperClass(TVPlayMapper.class);// 设置Mapper job.setMapOutputKeyClass(Text.class);// key输出类型 job.setMapOutputValueClass(TVPlayData.class);// value输出类型 job.setInputFormatClass(TVPlayInputFormat.class);//自定义输入格式 job.setReducerClass(TVPlayReducer.class);// 设置Reducer job.setOutputKeyClass(Text.class);// reduce key类型 job.setOutputValueClass(Text.class);// reduce value类型 // 自定义文件输出格式,通过路径名(pathname)来指定输出路径 MultipleOutputs.addNamedOutput(job, "youku", TextOutputFormat.class, Text.class, Text.class); MultipleOutputs.addNamedOutput(job, "souhu", TextOutputFormat.class, Text.class, Text.class); MultipleOutputs.addNamedOutput(job, "tudou", TextOutputFormat.class, Text.class, Text.class); MultipleOutputs.addNamedOutput(job, "aiqiyi", TextOutputFormat.class, Text.class, Text.class); MultipleOutputs.addNamedOutput(job, "xunlei", TextOutputFormat.class, Text.class, Text.class); FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径 FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径 job.waitForCompletion(true); return 0; } public static void main(String[] args) throws Exception{ String[] args0={"hdfs://master:9000/tvplay/", "hdfs://master:9000/tvplay/out"}; int ec = ToolRunner.run(new Configuration(), new TVPlayCount(), args0); System.exit(ec); } }
TVPlayData.java
package com.dajiangtai.hadoop.tvplay; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; /** * * @author yangjun * @function 自定义对象 */ public class TVPlayData implements WritableComparable<Object>{ private int daynumber; private int collectnumber; private int commentnumber; private int againstnumber; private int supportnumber; public TVPlayData(){} public void set(int daynumber,int collectnumber,int commentnumber,int againstnumber,int supportnumber){ this.daynumber = daynumber; this.collectnumber = collectnumber; this.commentnumber = commentnumber; this.againstnumber = againstnumber; this.supportnumber = supportnumber; } public int getDaynumber() { return daynumber; } public void setDaynumber(int daynumber) { this.daynumber = daynumber; } public int getCollectnumber() { return collectnumber; } public void setCollectnumber(int collectnumber) { this.collectnumber = collectnumber; } public int getCommentnumber() { return commentnumber; } public void setCommentnumber(int commentnumber) { this.commentnumber = commentnumber; } public int getAgainstnumber() { return againstnumber; } public void setAgainstnumber(int againstnumber) { this.againstnumber = againstnumber; } public int getSupportnumber() { return supportnumber; } public void setSupportnumber(int supportnumber) { this.supportnumber = supportnumber; } @Override public void readFields(DataInput in) throws IOException { daynumber = in.readInt(); collectnumber = in.readInt(); commentnumber = in.readInt(); againstnumber = in.readInt(); supportnumber = in.readInt(); } @Override public void write(DataOutput out) throws IOException { out.writeInt(daynumber); out.writeInt(collectnumber); out.writeInt(commentnumber); out.writeInt(againstnumber); out.writeInt(supportnumber); } @Override public int compareTo(Object o) { return 0; }; }
TVPlayInputFormat.java
package com.dajiangtai.hadoop.tvplay; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.util.LineReader; /** * * @author yangjun * @function key vlaue 输入格式 */ public class TVPlayInputFormat extends FileInputFormat<Text,TVPlayData>{ @Override public RecordReader<Text, TVPlayData> createRecordReader(InputSplit input, TaskAttemptContext context) throws IOException, InterruptedException { return new TVPlayRecordReader(); } public class TVPlayRecordReader extends RecordReader<Text, TVPlayData>{ public LineReader in; public Text lineKey; public TVPlayData lineValue; public Text line; @Override public void close() throws IOException { if(in !=null){ in.close(); } } @Override public Text getCurrentKey() throws IOException, InterruptedException { return lineKey; } @Override public TVPlayData getCurrentValue() throws IOException, InterruptedException { return lineValue; } @Override public float getProgress() throws IOException, InterruptedException { return 0; } @Override public void initialize(InputSplit input, TaskAttemptContext context) throws IOException, InterruptedException { FileSplit split=(FileSplit)input; Configuration job=context.getConfiguration(); Path file=split.getPath(); FileSystem fs=file.getFileSystem(job); FSDataInputStream filein=fs.open(file); in=new LineReader(filein,job); line=new Text(); lineKey=new Text(); lineValue = new TVPlayData(); } @Override public boolean nextKeyValue() throws IOException, InterruptedException { int linesize=in.readLine(line); if(linesize==0) return false; String[] pieces = line.toString().split(" "); if(pieces.length != 7){ throw new IOException("Invalid record received"); } lineKey.set(pieces[0]+" "+pieces[1]); lineValue.set(Integer.parseInt(pieces[2]),Integer.parseInt(pieces[3]),Integer.parseInt(pieces[4]) ,Integer.parseInt(pieces[5]),Integer.parseInt(pieces[6])); return true; } } }
先启动3节点集群

与自己在本地搭建的3节点集群的hdfs连接上
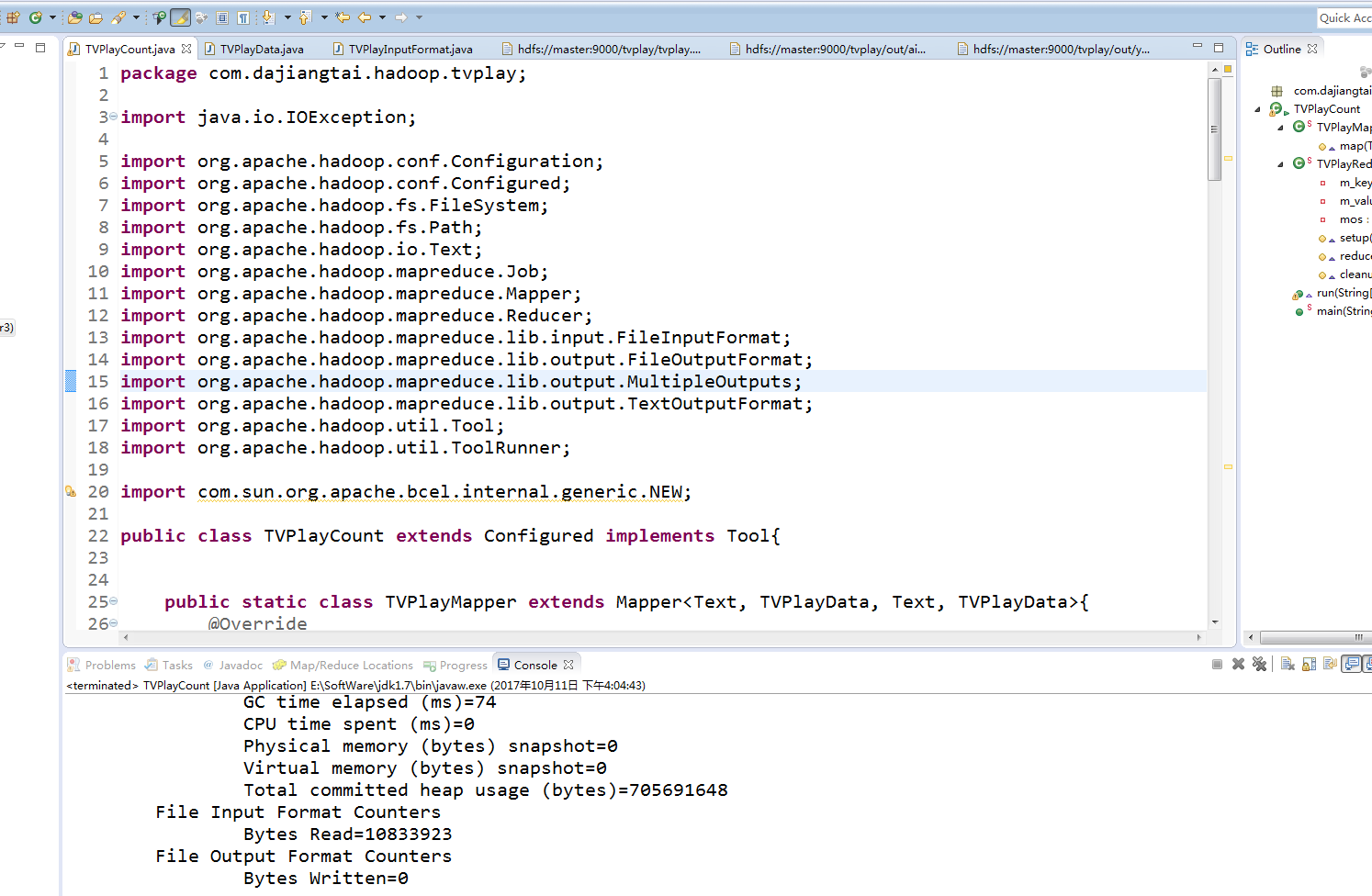
在终端显示的运行结果,程序没有错误
2017-10-11 16:04:55,893 INFO [org.apache.hadoop.conf.Configuration.deprecation] - session.id is deprecated. Instead, use dfs.metrics.session-id 2017-10-11 16:04:55,899 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId= 2017-10-11 16:04:56,987 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2017-10-11 16:04:56,993 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String). 2017-10-11 16:04:57,229 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1 2017-10-11 16:04:57,354 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:1 2017-10-11 16:04:57,426 INFO [org.apache.hadoop.conf.Configuration.deprecation] - user.name is deprecated. Instead, use mapreduce.job.user.name 2017-10-11 16:04:57,428 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class 2017-10-11 16:04:57,429 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.mapoutput.value.class is deprecated. Instead, use mapreduce.map.output.value.class 2017-10-11 16:04:57,430 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class 2017-10-11 16:04:57,430 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.job.name is deprecated. Instead, use mapreduce.job.name 2017-10-11 16:04:57,430 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class 2017-10-11 16:04:57,431 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapreduce.inputformat.class is deprecated. Instead, use mapreduce.job.inputformat.class 2017-10-11 16:04:57,431 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir 2017-10-11 16:04:57,431 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir 2017-10-11 16:04:57,432 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 2017-10-11 16:04:57,433 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class 2017-10-11 16:04:57,434 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.mapoutput.key.class is deprecated. Instead, use mapreduce.map.output.key.class 2017-10-11 16:04:57,434 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir 2017-10-11 16:04:58,164 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local300699497_0001 2017-10-11 16:04:58,336 WARN [org.apache.hadoop.conf.Configuration] - file:/tmp/hadoop-Administrator/mapred/staging/Administrator300699497/.staging/job_local300699497_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 2017-10-11 16:04:58,337 WARN [org.apache.hadoop.conf.Configuration] - file:/tmp/hadoop-Administrator/mapred/staging/Administrator300699497/.staging/job_local300699497_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 2017-10-11 16:04:58,864 WARN [org.apache.hadoop.conf.Configuration] - file:/tmp/hadoop-Administrator/mapred/local/localRunner/Administrator/job_local300699497_0001/job_local300699497_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 2017-10-11 16:04:58,865 WARN [org.apache.hadoop.conf.Configuration] - file:/tmp/hadoop-Administrator/mapred/local/localRunner/Administrator/job_local300699497_0001/job_local300699497_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 2017-10-11 16:04:58,904 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/ 2017-10-11 16:04:58,906 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local300699497_0001 2017-10-11 16:04:58,953 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null 2017-10-11 16:04:58,984 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 2017-10-11 16:04:59,233 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks 2017-10-11 16:04:59,234 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local300699497_0001_m_000000_0 2017-10-11 16:04:59,451 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux. 2017-10-11 16:04:59,900 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@1b9156ad 2017-10-11 16:04:59,908 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://master:9000/tvplay/tvplay.txt:0+10833923 2017-10-11 16:04:59,910 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local300699497_0001 running in uber mode : false 2017-10-11 16:04:59,952 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0% 2017-10-11 16:04:59,987 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 2017-10-11 16:05:00,170 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584) 2017-10-11 16:05:00,170 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100 2017-10-11 16:05:00,170 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080 2017-10-11 16:05:00,170 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600 2017-10-11 16:05:00,170 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600 2017-10-11 16:05:03,511 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 2017-10-11 16:05:03,545 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output 2017-10-11 16:05:03,545 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output 2017-10-11 16:05:03,545 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 12652147; bufvoid = 104857600 2017-10-11 16:05:03,545 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 24882940(99531760); length = 1331457/6553600 2017-10-11 16:05:04,913 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0 2017-10-11 16:05:04,924 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local300699497_0001_m_000000_0 is done. And is in the process of committing 2017-10-11 16:05:04,998 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map 2017-10-11 16:05:04,998 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local300699497_0001_m_000000_0' done. 2017-10-11 16:05:04,998 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local300699497_0001_m_000000_0 2017-10-11 16:05:04,999 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Map task executor complete. 2017-10-11 16:05:05,047 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux. 2017-10-11 16:05:05,366 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@fba110e 2017-10-11 16:05:05,417 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments 2017-10-11 16:05:05,484 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 13317874 bytes 2017-10-11 16:05:05,485 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 2017-10-11 16:05:05,578 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 2017-10-11 16:05:05,978 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0% 2017-10-11 16:05:07,669 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local300699497_0001_r_000000_0 is done. And is in the process of committing 2017-10-11 16:05:07,675 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 2017-10-11 16:05:07,675 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local300699497_0001_r_000000_0 is allowed to commit now 2017-10-11 16:05:07,716 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local300699497_0001_r_000000_0' to hdfs://master:9000/tvplay/out/_temporary/0/task_local300699497_0001_r_000000 2017-10-11 16:05:07,717 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce 2017-10-11 16:05:07,717 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local300699497_0001_r_000000_0' done. 2017-10-11 16:05:07,978 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100% 2017-10-11 16:05:07,979 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local300699497_0001 completed successfully 2017-10-11 16:05:08,015 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 32 File System Counters FILE: Number of bytes read=13318207 FILE: Number of bytes written=27040248 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=21667846 HDFS: Number of bytes written=195234 HDFS: Number of read operations=17 HDFS: Number of large read operations=0 HDFS: Number of write operations=11 Map-Reduce Framework Map input records=332865 Map output records=332865 Map output bytes=12652147 Map output materialized bytes=13317883 Input split bytes=101 Combine input records=0 Combine output records=0 Reduce input groups=5741 Reduce shuffle bytes=0 Reduce input records=332865 Reduce output records=0 Spilled Records=665730 Shuffled Maps =0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=74 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=705691648 File Input Format Counters Bytes Read=10833923 File Output Format Counters Bytes Written=0
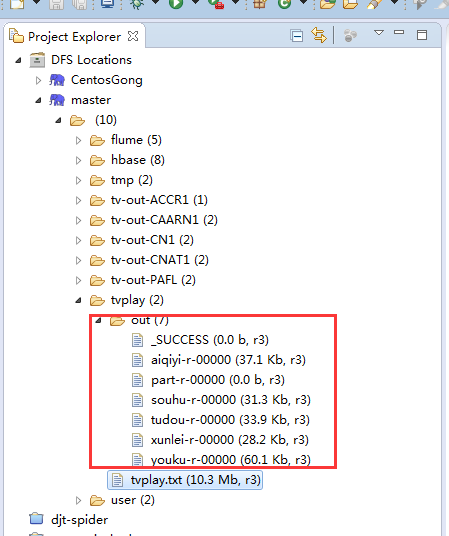
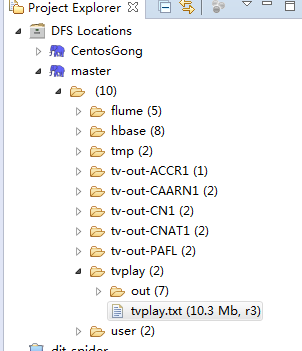
查看hdfs上的输出结果