

1.数据在存储和传输过程中出现数据的不完整性,数据传输量越大出错的概论就越高。
2.通过校验的方法可以知道数据是不完整的。
3.检测的思路是通过校验和,在传输之前计算一个校验和传输之后再计算一个校验和,两个校验和进行比较,如果不同的话就说明数据错误。
4.常见的检测手段:CRC(循环冗余校验):常见的CRC32————他会根据32位(4个字节)来计算校验和。还有一中方式就是数据库检测程序
5.HDFS在数据读 写 存储的时候会出现数据的不完整,在数据在客户端写入的时候计算一个校验和,在往第一个datanode传输的时候在存数据的过程中也会把校验和一快存在节点上,然后再往第二个第三datanode传输,在第三个datanode的时候再计算一个校验和,如果这个校验和和之前的对比一样的话就说明数据是完整的。
6.校验和损坏的几率很小,因为校验和占整个数据的比重非常小,一般用比较好的硬件来存储。
7.数据损坏了一般通过副本来恢复。
8.因为开启了校验和功能的时候,当发现数据损坏的时候会把数据干掉,如果说数据是非常重要的数据,损坏的只是其中一部分,可以从里边恢复一些数据,在这种情况我们可以考虑禁用校验和功能。
9.校验和一般放在你的文件同目录下的一个隐藏文件 .filename.crc












RPC 远程过程调用






Hadoop源码编译并配置Snappy压缩
在root用户下在线下载:
yum -y install gcc-c++
安装maven

上传解压

环境变量

查看是否安装成功
mvn –v
tar -zxvf protobuf-2.5.0.tar.gz mv protobuf-2.5.0 protobuf cd protobuf ./configure --prefix=/usr/local/protobuf make make check make install
配置环境变量

查看是否安装成功
protoc --version
安装cmake
yum -y install cmake
zlib安装
yum -y install zlib
openssl devel
yum -y install openssl-devel
下载并解压snappy-1.1.3.tar.gz
tar -zxvf snappy-1.1.3.tar.gz
mv snappy-1.1.3 snappy
cd snappy
./configure
make
make install
下载并解压hadoop-2.6.0-src.tar.gz,然后进入hadoop-2.6.0-src目录编码Hadoop源码和Snappy压缩。
///usr/local/lib是Snappy默认安装目录
1、执行mvn package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
然后一直等待,直到hadoop源码编译成功,

2.进入到这个目录下解压hadoop-2.6.0.tar.gz
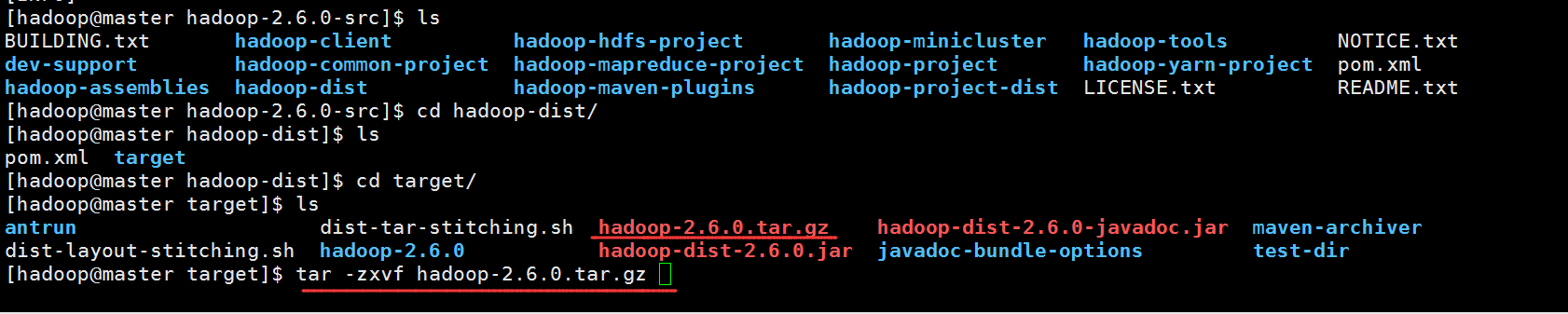
3.进入目录会发现多了一些和snappy有关的文件。
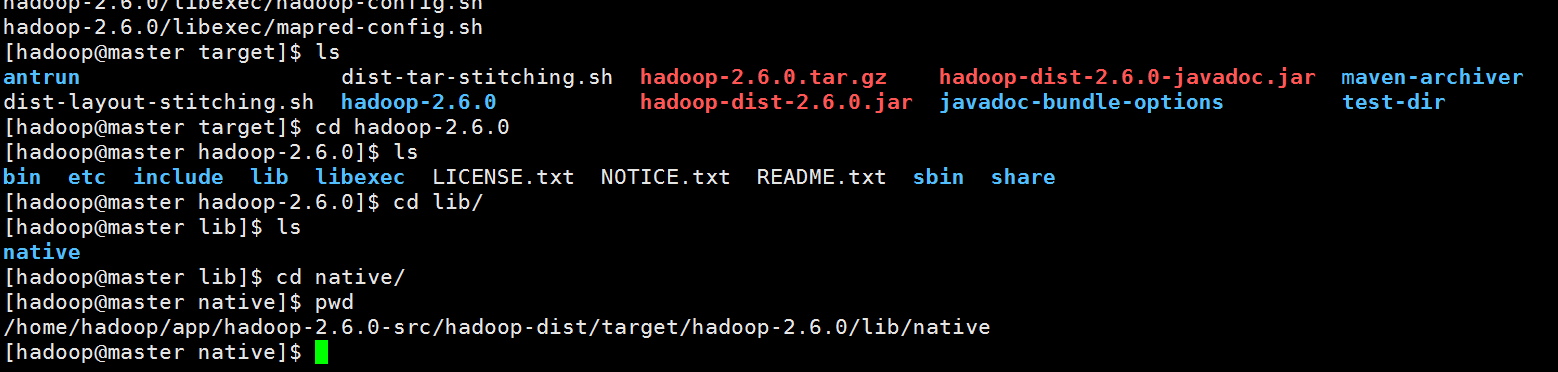

4.输入命令cp ./native/* /home/hadoop/app/hadoop-2.6.0/lib/native/ 把该native目录下的文件copy到原hadoop安装目录下的native目录里,简单的说就是替换原来的native。

对比替换前后

5、最后输入命令hadoop checknative -a检查本地库是否安装成功

Hadoop 配置Snappy压缩

添加以下


添加以下


添加以下
