先搭建zookeeper
上传zookeeper并解压

把没有用的删除

创建一个目录zkData

修改zookeeper的配置文件
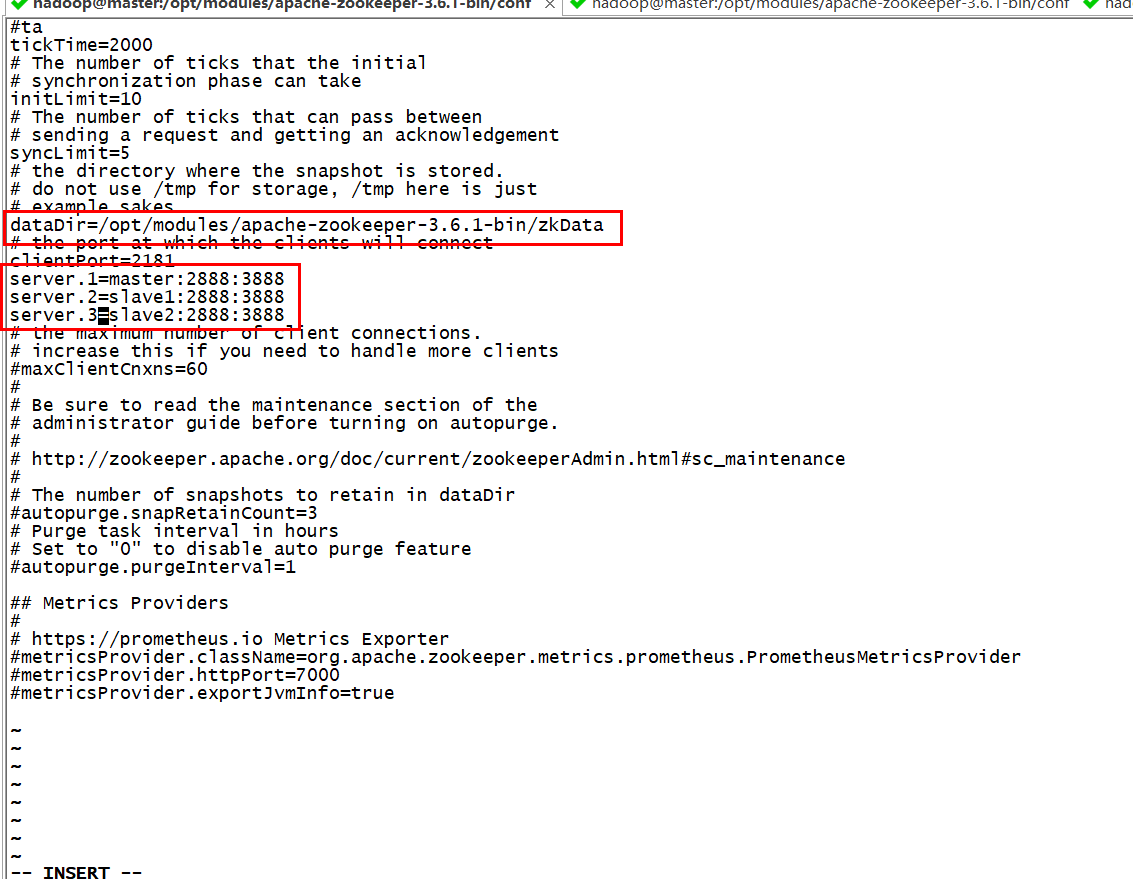
dataDir=/opt/modules/apache-zookeeper-3.6.1-bin/zkData server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888
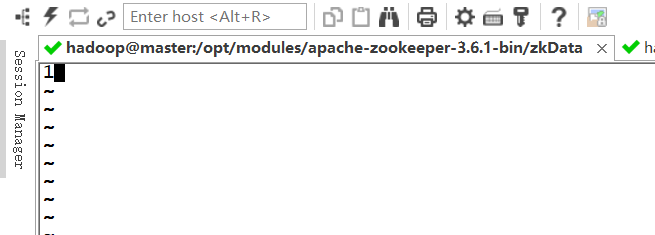
创建myid文件

在里面输入1
现在我们对zookeeper的配置就完成了,接下来就是分发给另外两台机器。
scp -r apache-zookeeper-3.6.1-bin/ hadoop@slave1:/opt/modules/ scp -r apache-zookeeper-3.6.1-bin/ hadoop@slave2:/opt/modules/
分发完之后分别把/opt/modules/apache-zookeeper-3.6.1-bin/zkData 下的myid改成2和3
接下来启动zookeeper服务,在三台机器都要启动



启动完之后我们就可以通过客户端来连接我们的服务了
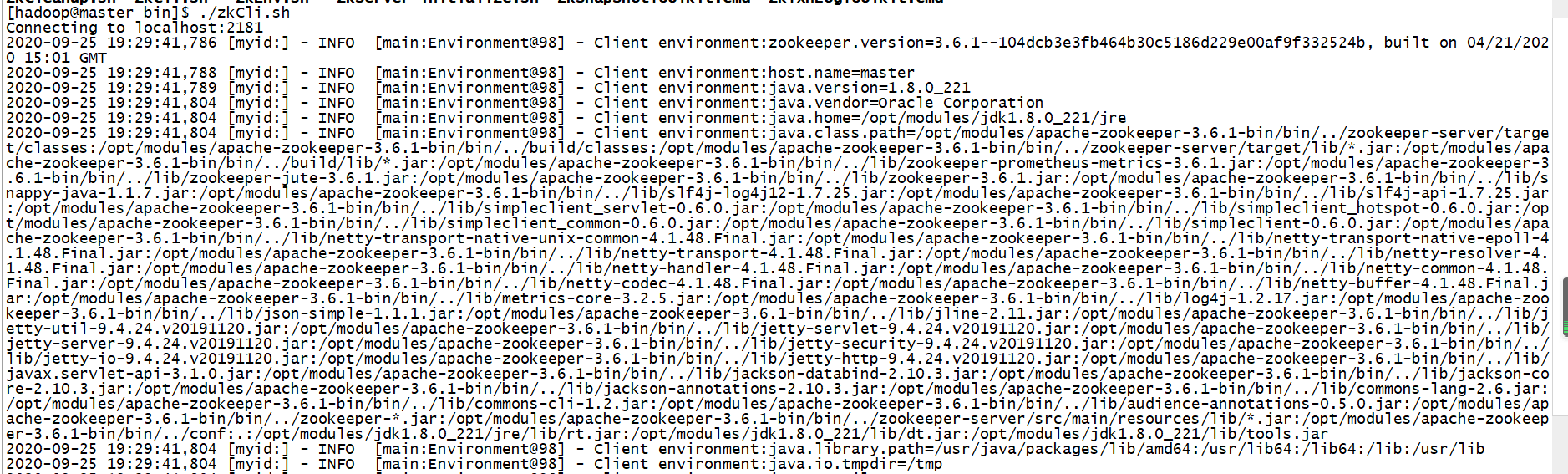
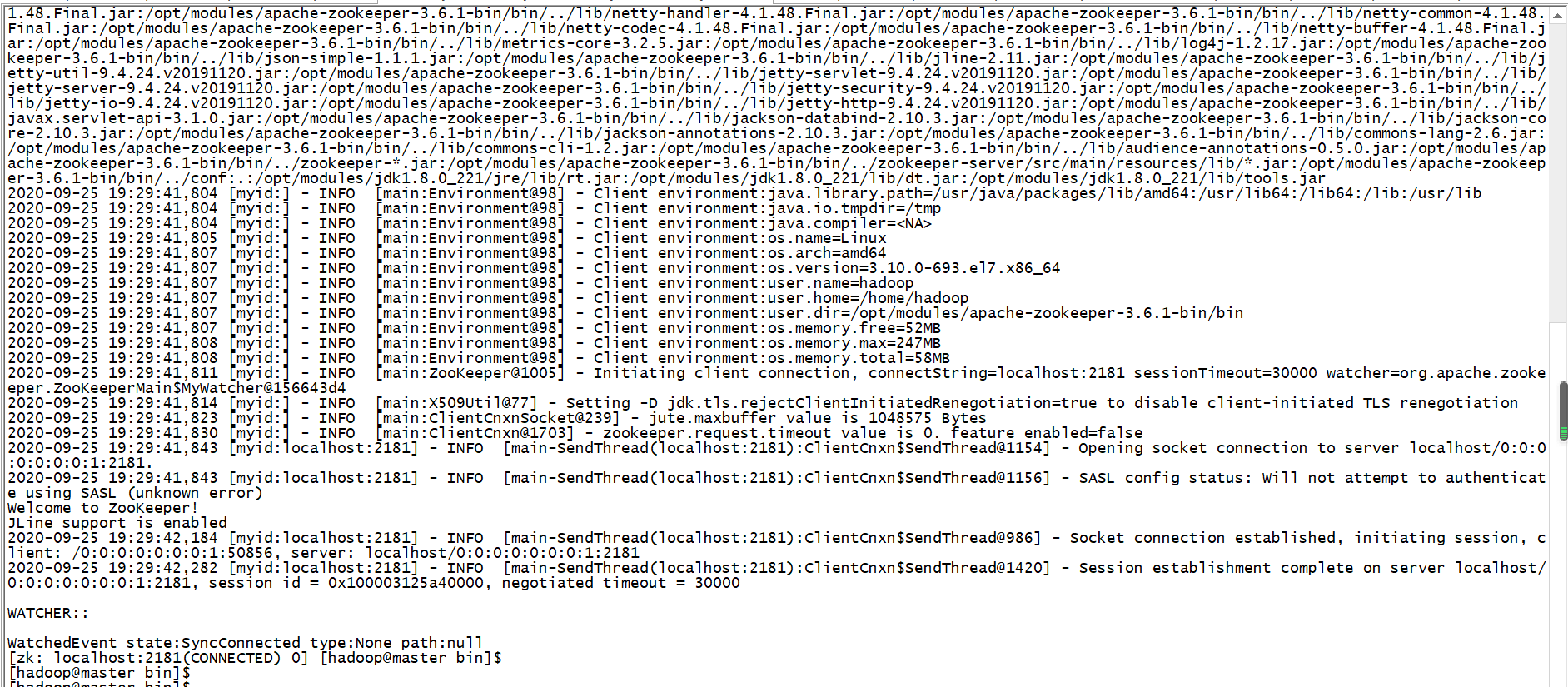
现在查看谁是“老大”



zookeeper部署完成!!
显然这里需要先部署hadoop的高可用
先上传hadoop包,解压

修改配置文件

修改 hadoop-env.sh
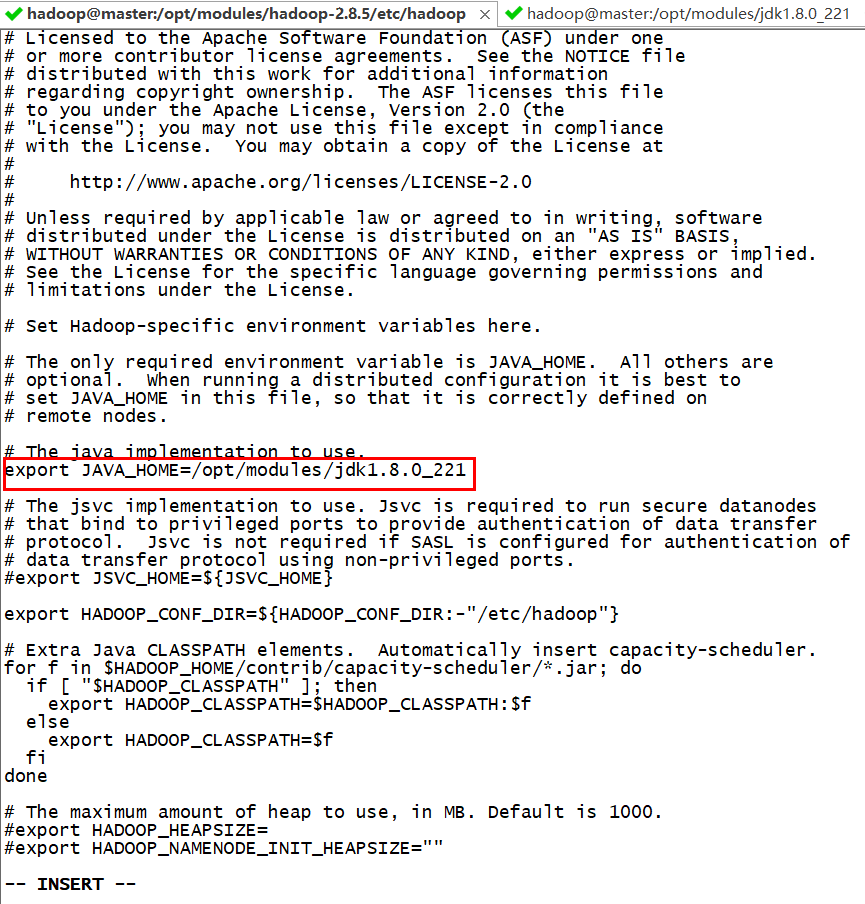
export JAVA_HOME=/opt/modules/jdk1.8.0_221
修改 yarn-env.sh
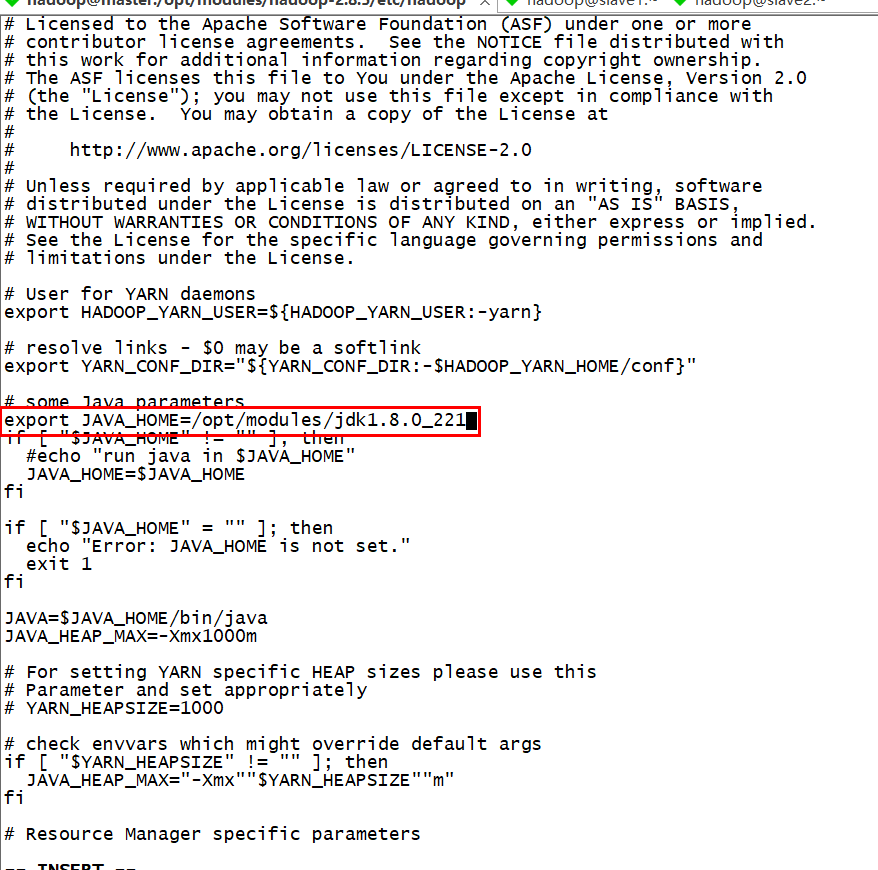
export JAVA_HOME=/opt/modules/jdk1.8.0_221
vim mapred-env.sh
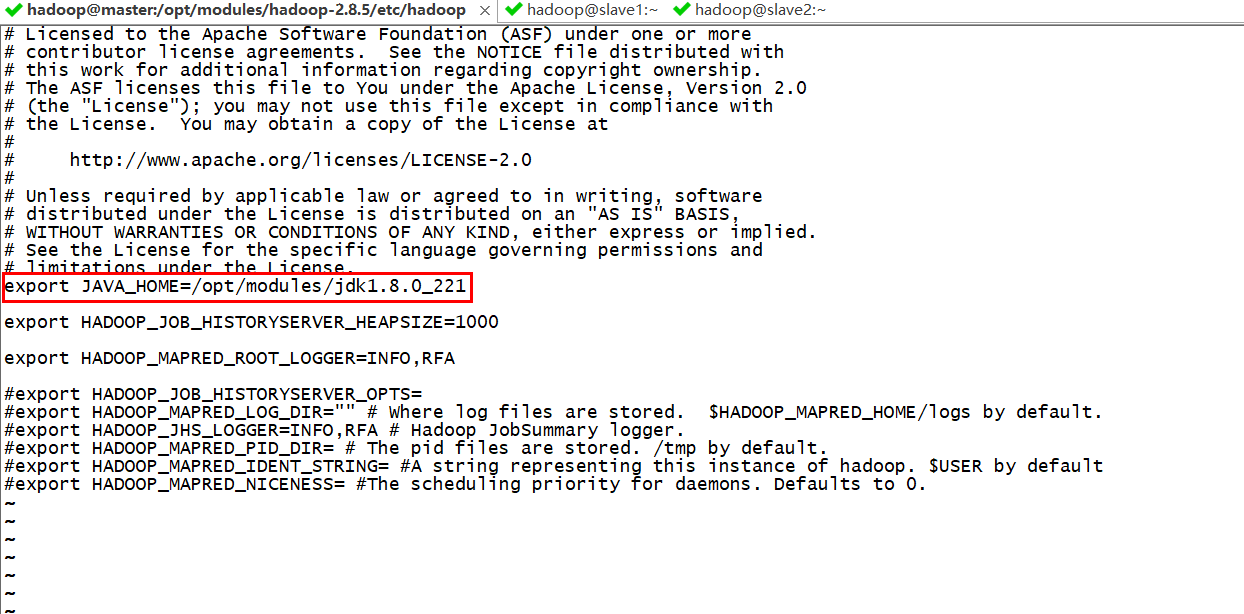
export JAVA_HOME=/opt/modules/jdk1.8.0_221
修改hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/hadoop-2.8.5/data/jn</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
修改core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.8.5/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
修改mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
vim yarn-site.xml
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rs</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改slaves
master
slave1
slave2
将配置好的hadoop分发给其他节点
scp -r hadoop-2.8.5/ hadoop@slave1:/opt/modules/ scp -r hadoop-2.8.5/ hadoop@slave2:/opt/modules/
启动journalnode(在所有机器都启动)
./hadoop-daemon.sh start journalnode



格式化namenode
bin/hdfs namenode -format
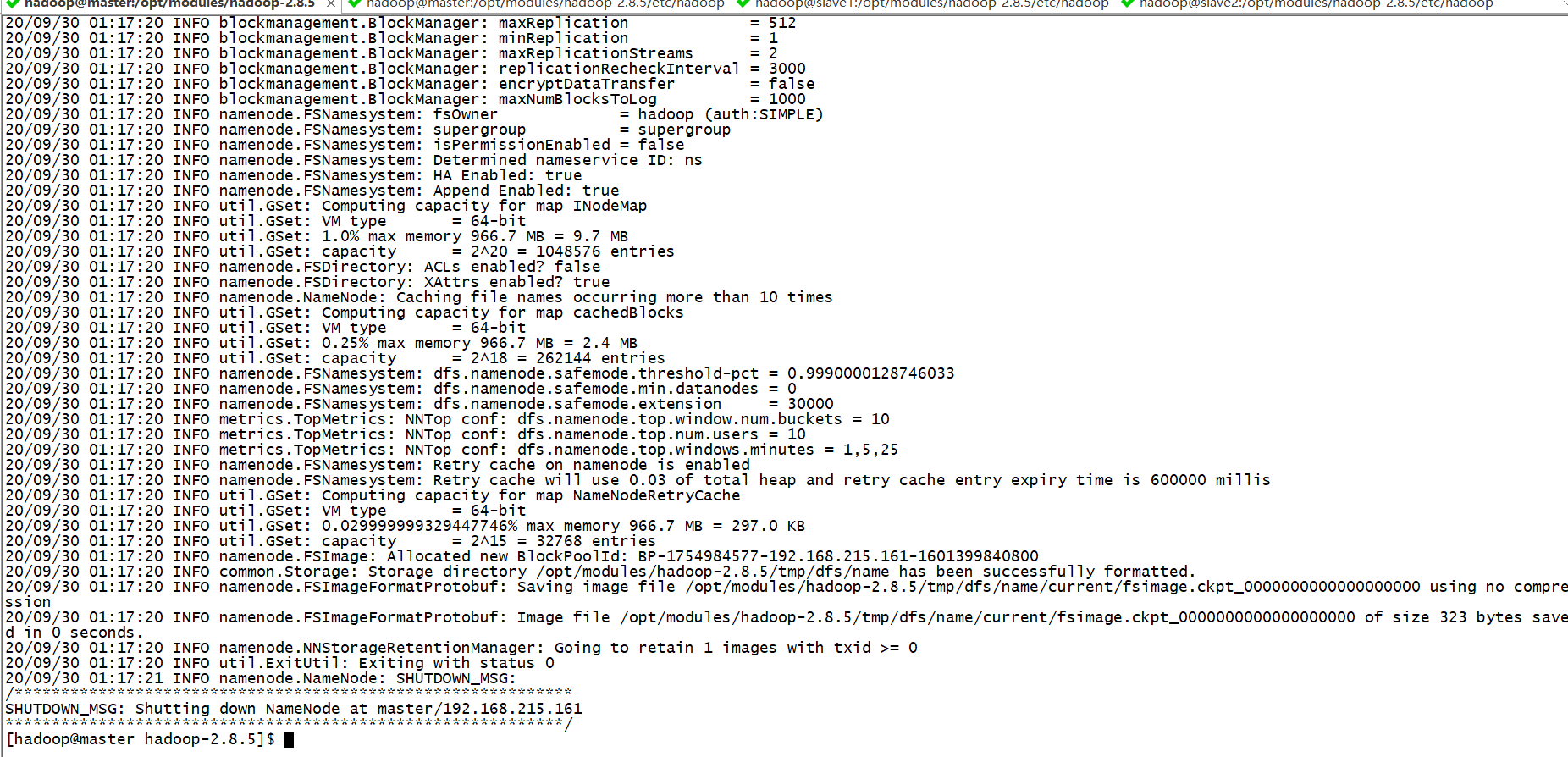
如果出现这样的问题
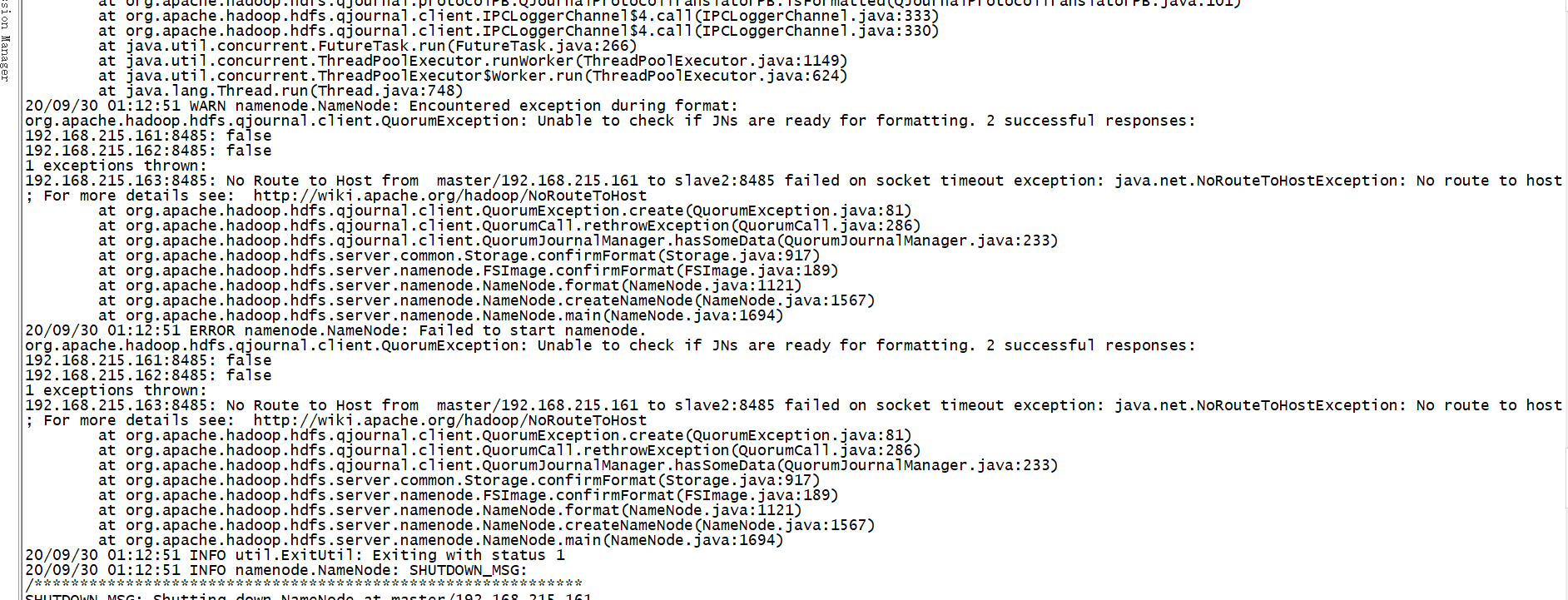
检查对应的机器的防火墙是否关闭
启动namenode
./hadoop-daemon.sh start namenode

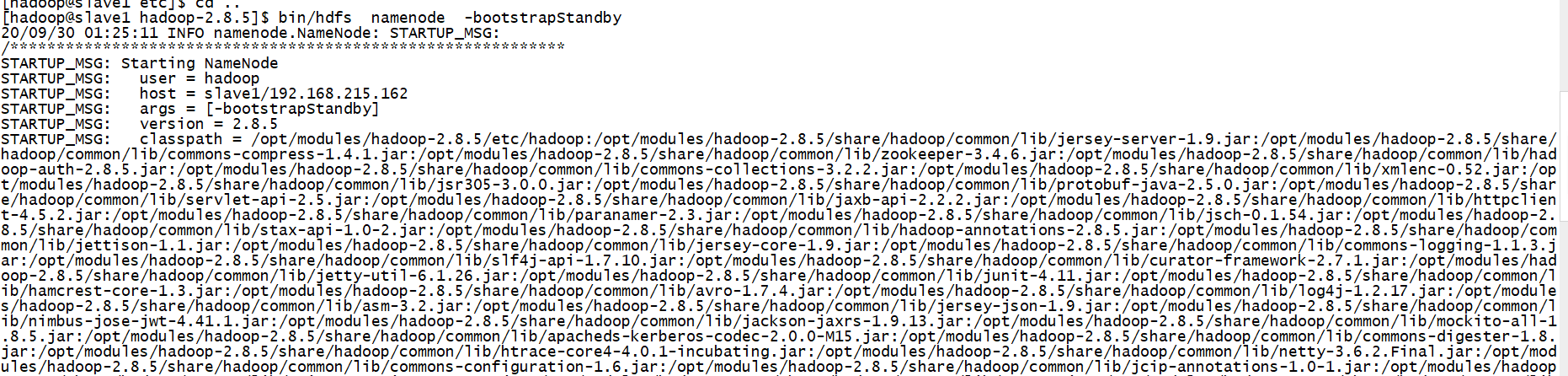
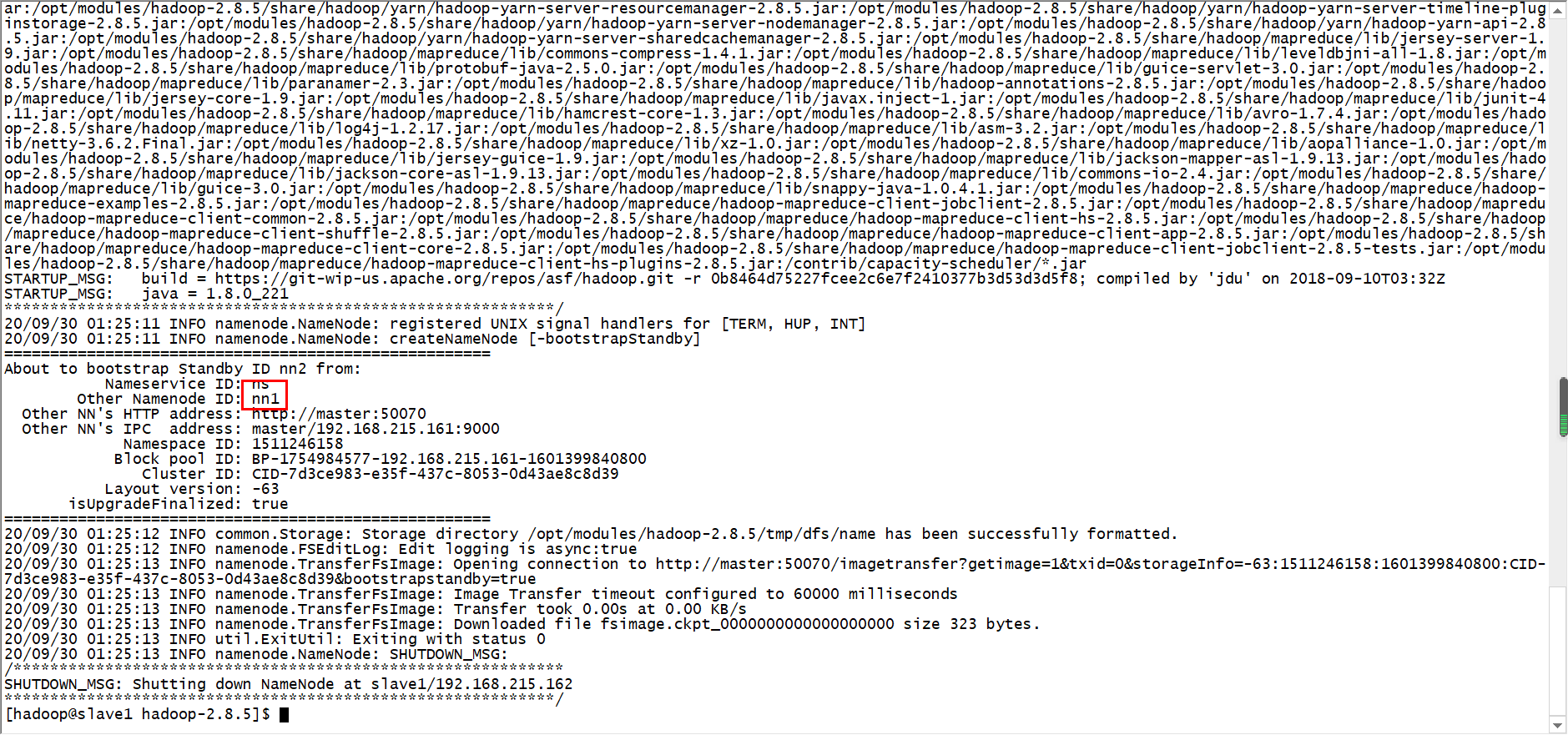
在nn2上同步nn1的元数据信息
bin/hdfs namenode -bootstrapStandby
格式化ZKFC
bin/hdfs zkfc -formatZK
直接一键启动吧
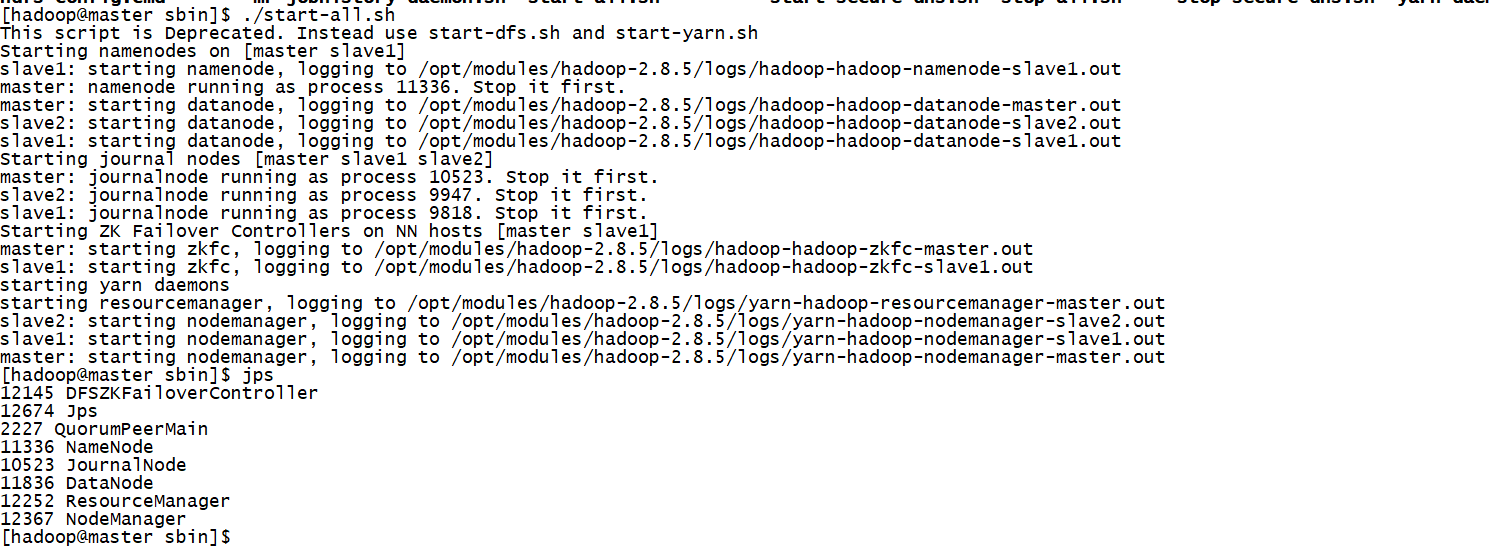
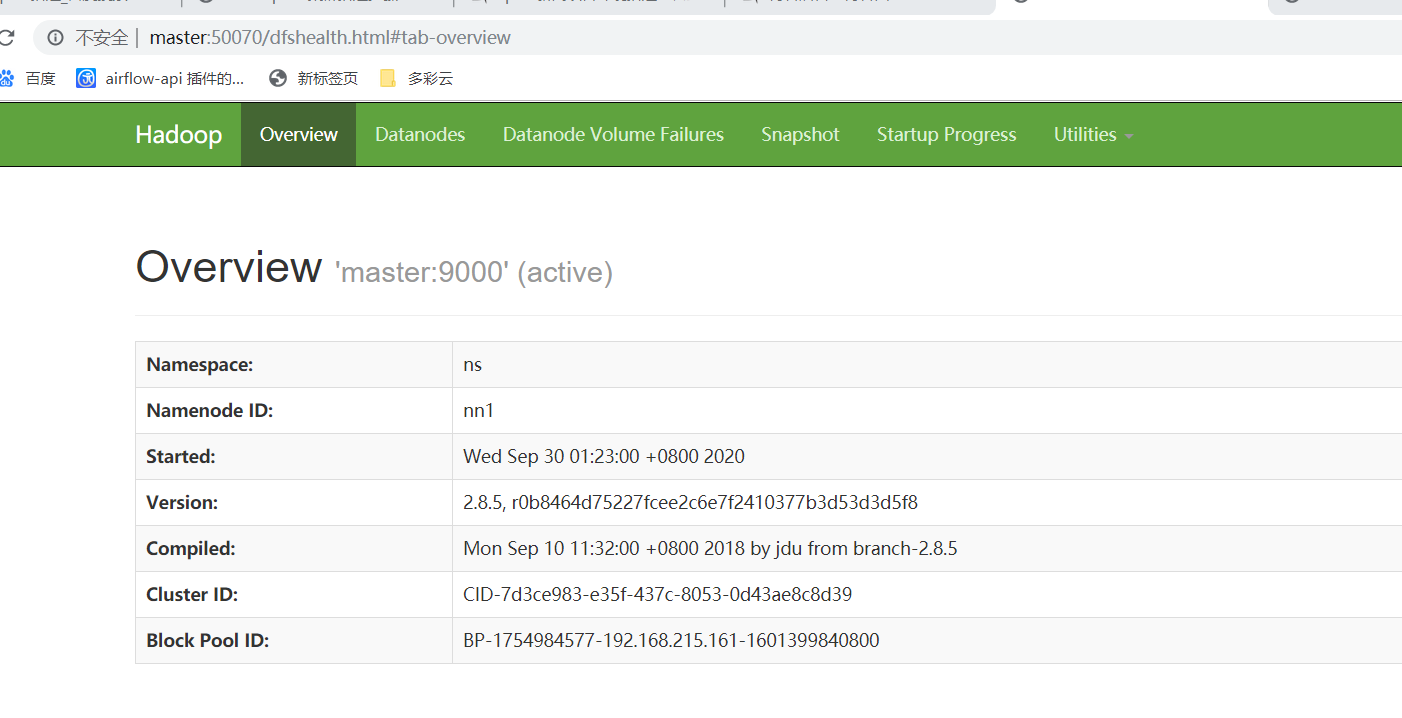
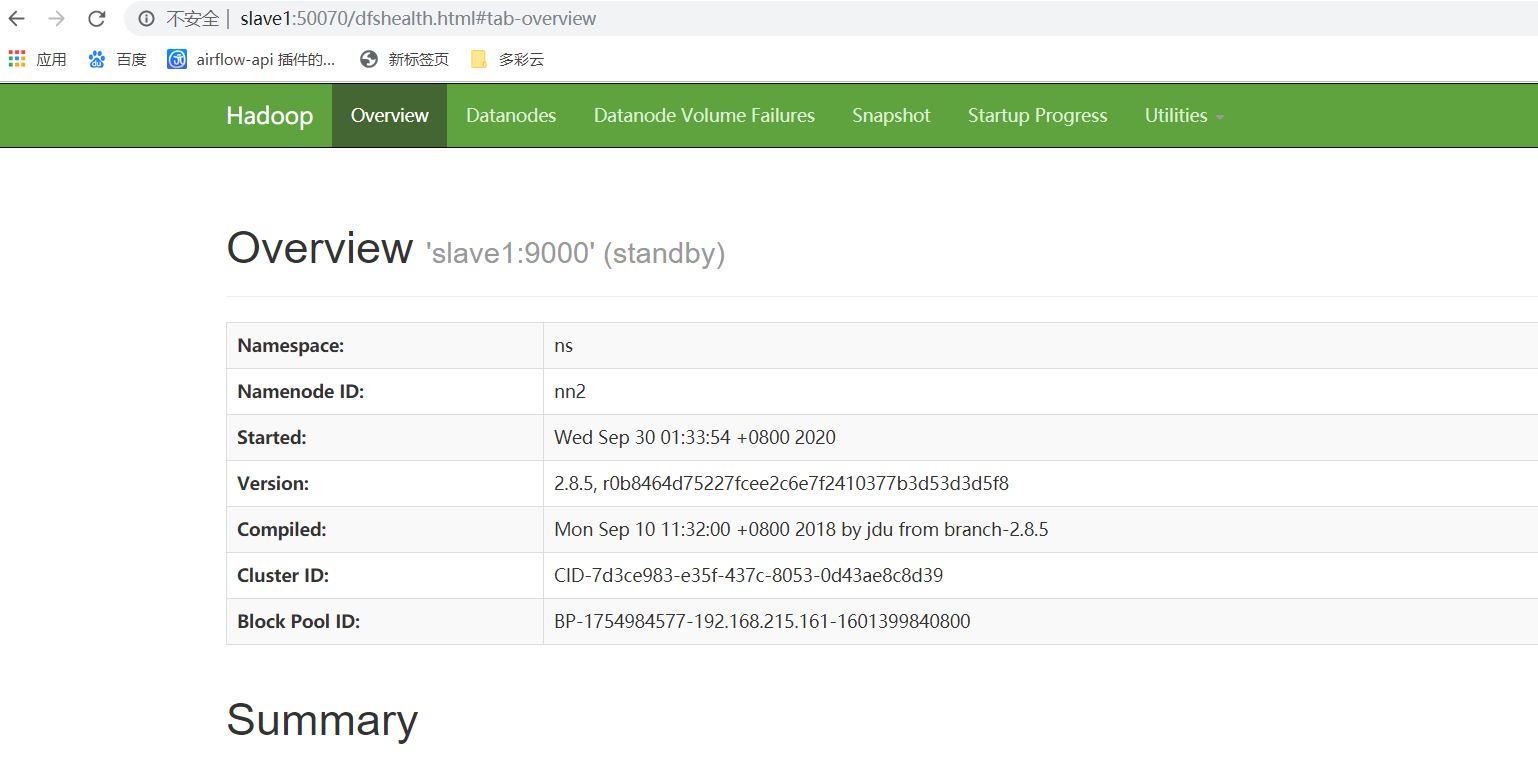
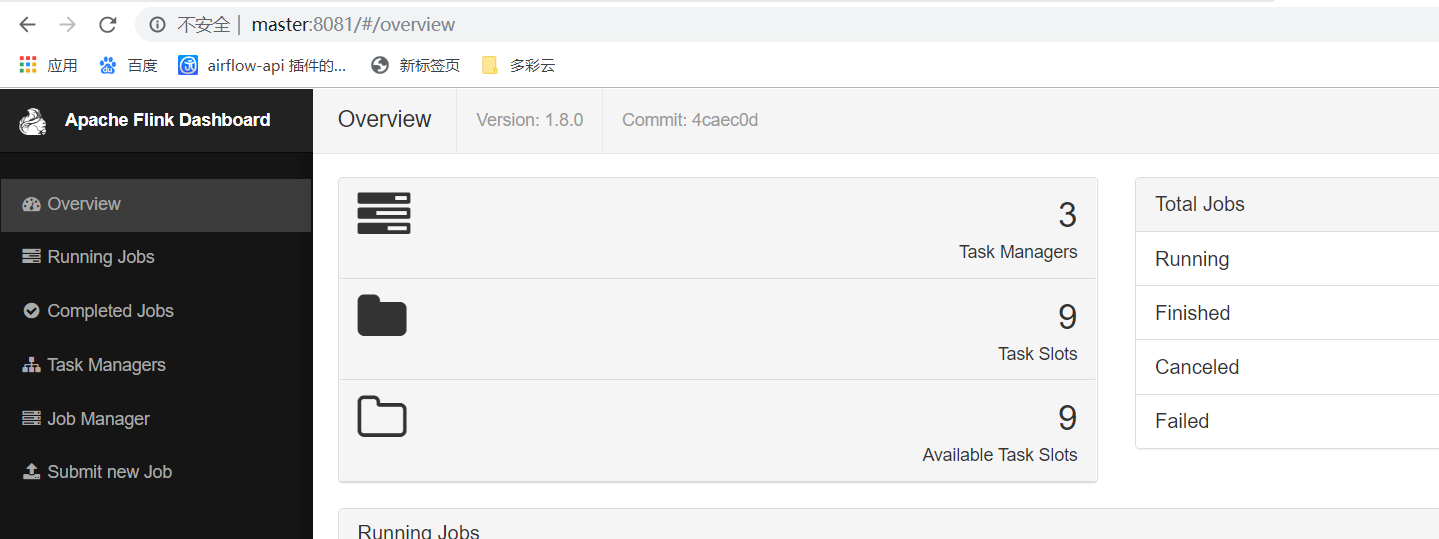
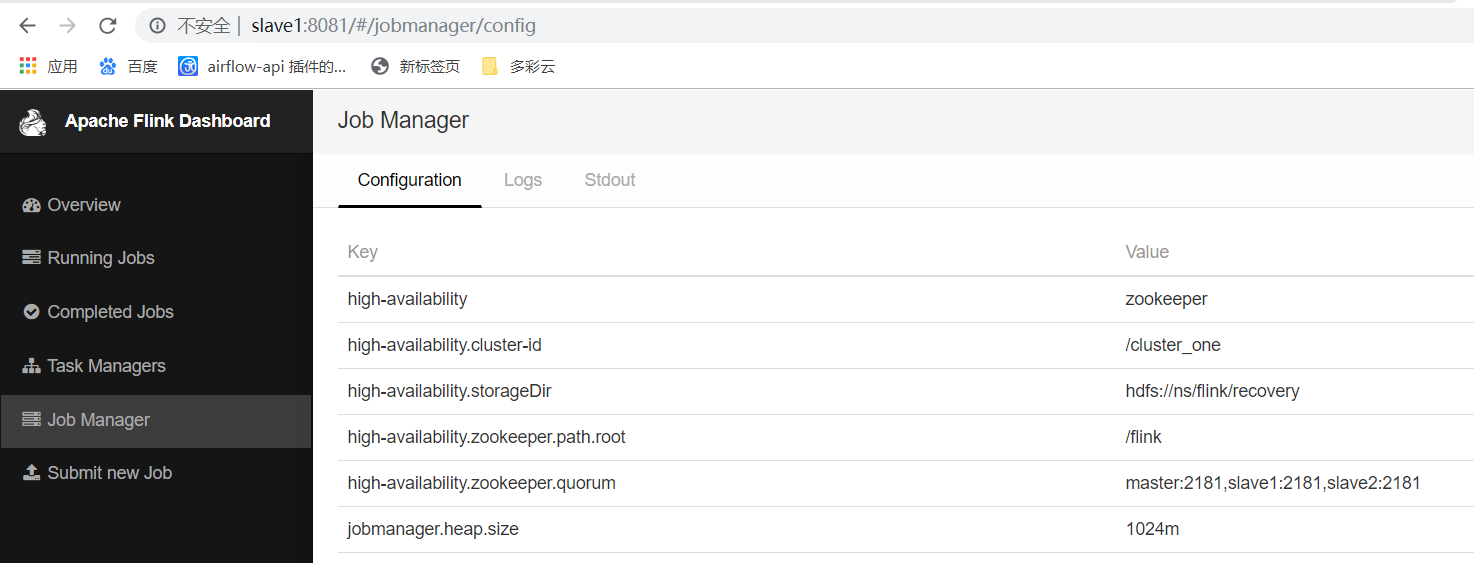
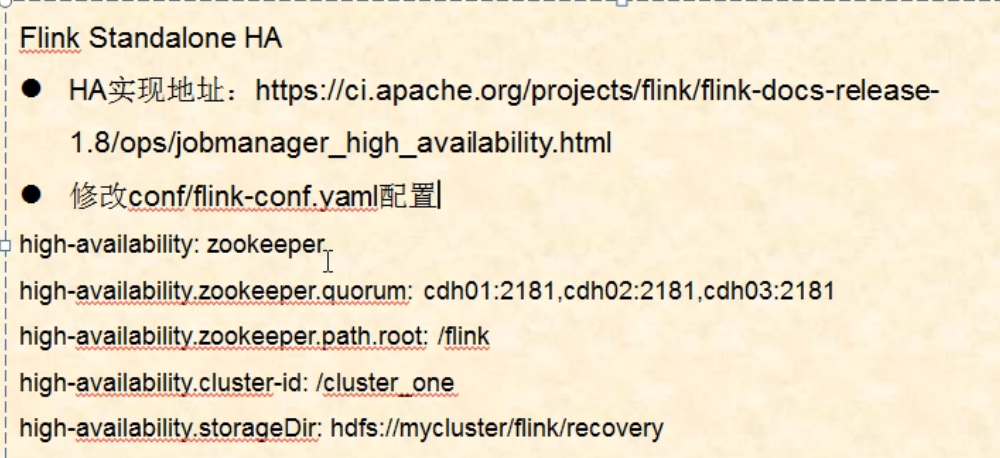
配置flink的高可用

vim flink-conf.yaml
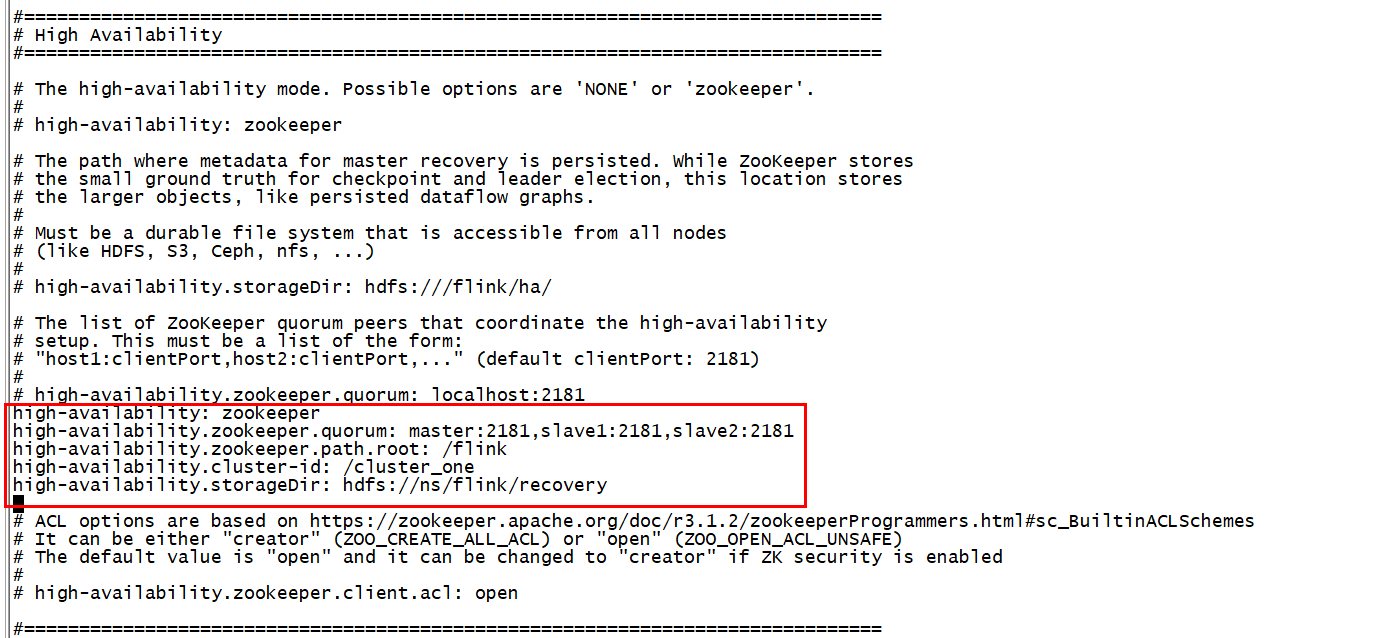
high-availability: zookeeper high-availability.zookeeper.quorum: master:2181,slave1:2181,slave2:2181, high-availability.zookeeper.path.root: /flink high-availability.cluster-id: /cluster_one high-availability.storageDir: hdfs://ns/flink/recovery
同时把修改后的配置文件同步到另外两个节点
修改master文件

把master文件同步到另外两个节点去

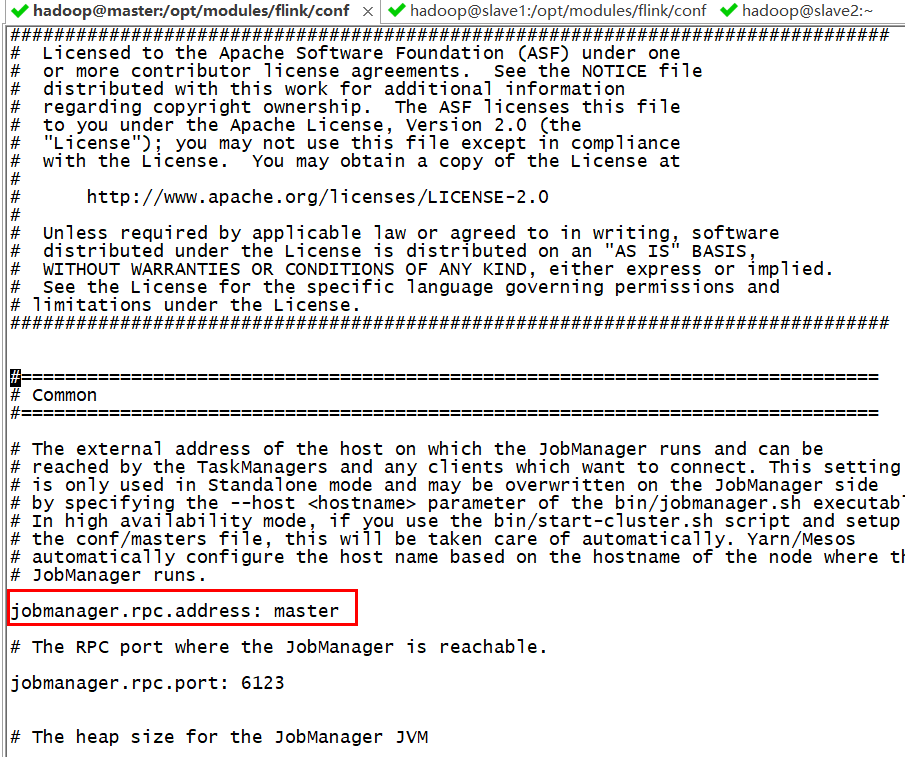
在master节点
vim flink-conf.yaml
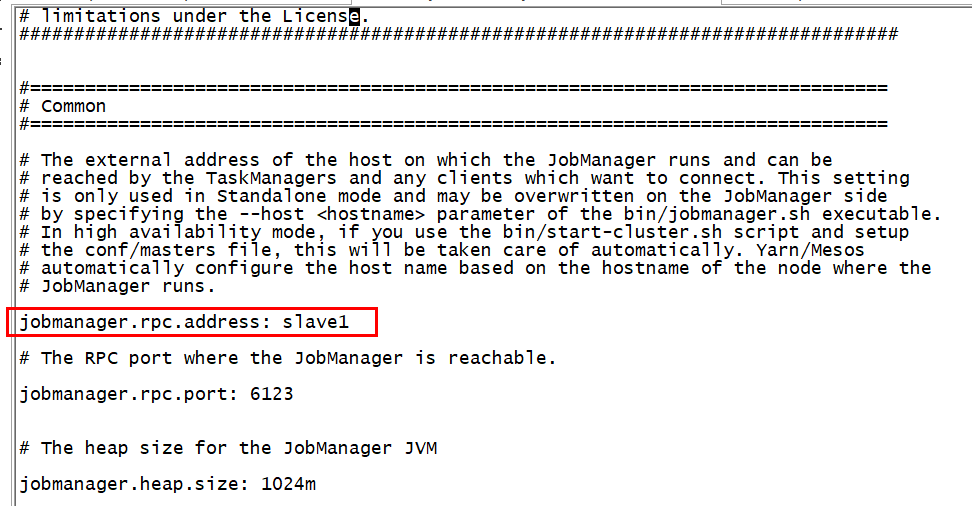
在slave1节点
vim flink-conf.yaml
配置hadoop环境变量,三个节点都配置
#hadoop export HADOOP_HOME=/opt/modules/hadoop-2.8.5 export PATH=$HADOOP_HOME/bin:$PATH
启动flink集群

我们查看进程,发现并没有flink的进程

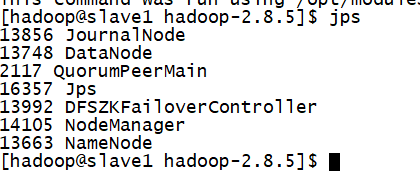

查看日志


这样解决
进入flink的官网https://flink.apache.org/downloads.html#all-stable-releases
根据自己的hadoop版本下载对应的架包
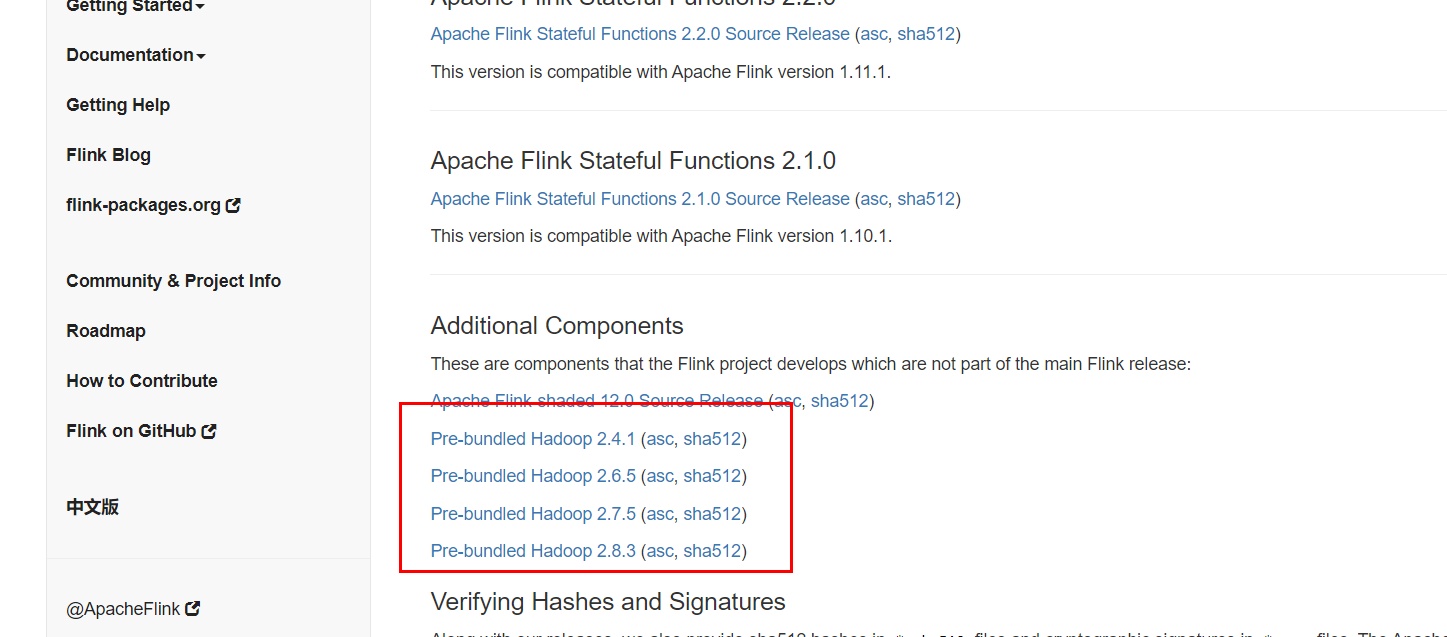
把架包上传到三个节点的flink/lib目录下

重新启动一下flink集群

分别查三个节点的进程

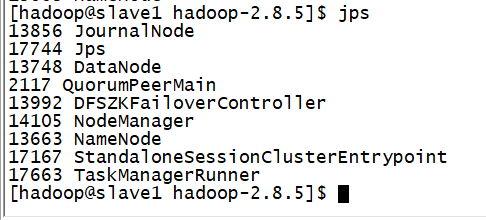
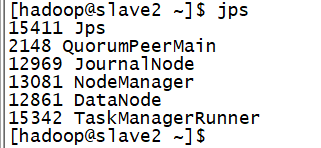
打开浏览器访问flink的主页