| 一、函数对象 |
函数对象:函数是第一类对象,即函数可以当作数据传递
1 可以被引用
2 可以当作参数传递
3 返回值可以是函数
3 可以当作容器类型的元素
1、函数可以被引用,即函数可以赋值给一个变量


1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 def foo(): 4 print('from foo') 5 6 foo() 7 func=foo #引用,赋值 8 print(foo) 9 print(func) 10 func()
2、可以当作参数传递
1 def foo(): 2 print('from foo') 3 4 def bar(func): 5 print(func) 6 func() 7 8 bar(foo) 9 10 代码运行结果: 11 <function foo at 0x1047eff28> 12 from foo
3、返回值可以是函数
1 def foo(): 2 print('from foo') 3 4 def bar(func): 5 return func 6 7 f=bar(foo) 8 9 print(f) 10 11 f() 12 13 运行结果: 14 <function foo at 0x0000024AD6E48AE8> 15 from foo
4、可以当作容器类型的元素
1 def foo(): 2 print('from foo') 3 dic={'func':foo} 4 5 print(dic['func']) 6 7 dic['func']() 8 9 运行结果: 10 <function foo at 0x0000020849BE8AE8> 11 from foo
5、函数可以嵌套
1 def f1(): 2 3 def f2(): 4 print('from f2') 5 def f3(): 6 print('from f3') 7 f3() 8 f2() 9 10 11 f1() 12 13 14 运行结果: 15 from f2 16 from f3
| 二、函数的命名空间和作用域 |
函数有三种命名空间
1、内置命名空间,随着python解释器的启动而产生
print(sum) print(max) print(min) print(max([1,2,3])) import builtins for i in dir(builtins): print(i)
2、全局名称空间:文件的执行会产生全局名称空间,指的是文件级别定义的名字都会放入该空间
1 x=1 2 3 4 def func(): 5 money=2000 6 x=2 7 print('func') 8 print(x) 9 print(func) 10 func() 11 print(money) 12 13 func() 14 print(x)
3、局部名称空间:调用函数时会产生局部名称空间,只在函数调用时临时绑定,调用结束解绑定
1 x=10000 2 def func(): 3 x=1 4 def f1(): 5 pass
作用域
1. 全局作用域:内置名称空间,全局名层空间
2. 局部作用:局部名称空间
名字的查找顺序:局部名称空间---》全局名层空间---》内置名称空间
1 # x=1 2 def func(): 3 # x=2 4 # print(x) 5 # sum=123123 6 print(sum) 7 func()
查看全局作用域内的名字:gloabls()
查看局局作用域内的名字:locals()
1 x=1000 2 def func(): 3 x=2 4 5 print(globals()) 6 7 print(locals()) 8 print(globals() is locals())
全局作用域:全局有效,在任何位置都能被访问到,除非del删掉,否则会一直存活到文件执行完毕
局部作用域的名字:局部有效,只能在局部范围调用,只在函数调用时才有效,调用结束就失效
1 x=1 2 3 def f1(): 4 print(x) 5 6 def foo(): 7 print(x) 8 9 def f(x): 10 # x=4 11 def f2(): 12 # x=3 13 def f3(): 14 # x=2 15 print(x) 16 17 f3() 18 f2() 19 20 f(4)
| 闭包函数 |
闭包函数是指延伸了作用域的函数,其中包含函数定义体中引用,但是不在定义体中定义的非全局变量,它能够访问定义体之外定义的非全局变量
简单来说,一个闭包就是你调用了一个函数A,这个函数A返回了一个函数B给你。这个返回的函数B就叫做闭包。
闭包函数须满足以下条件:
1. 定义在内部函数;
2. 包含对外部作用域而非全局作用域的引用;
例子:
1 def f1(): 2 x = 1 3 def f2(): 4 print(x) 5 return f2 6 7 f=f1() 8 print(f) 9 10 x=100 11 f() 12 print(x)
结果:
1 <function f1.<locals>.f2 at 0x000001F1B70B89D8> 2 1 3 100
闭包的应用:惰性计算
from urllib.request import urlopen def index(url): def get(): return urlopen(url).read() return get oldboy=index('http://crm.oldboyedu.com') print(oldboy().decode('utf-8')) print(oldboy.__closure__[0].cell_contents)
| 装饰器 |
实现并发效果
1、定义:
装饰器:修饰别人的工具,修饰添加功能,工具指的是函数
装饰器本身可以是任何可调用对象,被装饰的对象也可以是任意可调用对象
2、为什么要用装饰器:
开放封闭原则:对修改是封闭的,对扩展是开放的3、装饰器的基本框架
装饰器就是为了在不修改被装饰对象的源代码以及调用方式的前提下,为期添加新功能
1 def timer(func): 2 def wrapper(): 3 func() 4 return wrapper 5 6 @timer 7 def index(): 8 print(welcome) 9 10 index() 11 12 13 # 带参数的 14 def timer(func): 15 def wrapper(*args,**kwargs): 16 func(*args,**kwargs) 17 return wrapper 18 19 @timer # index=timer(index) 20 def index(name): # index =wrapper 21 print(name) 22 23 index('hehe')
4、装饰器的实现
装饰器的功能是将被装饰的函数当作参数传递给与装饰器对应的函数(名称相同的函数),并返回包装后的被装饰的函数”
1 def a(name): #与装饰器对应的函数 2 return name() 3 4 @a #装饰器的作用是 b = a(b) 5 def b(): #被装饰函数 6 print('welcome')
实现二:
1 import time 2 3 def timmer(func): 4 def wrapper(*args,**kwargs): 5 start_time=time.time() 6 res=func(*args,**kwargs) 7 stop_time=time.time() 8 print('run time is %s' %(stop_time-start_time)) 9 return wrapper 10 11 @timmer #index=timmer(index)==>index=wrapper==> 12 def index(): # index=wrapper 13 14 time.sleep(3) 15 print('welcome to index') 16 17 index()
代码终极实现讲解
1 # import time 2 # 3 # def timmer(func): 4 # def wrapper(*args,**kwargs): 5 # start_time=time.time() 6 # res=func(*args,**kwargs) 7 # stop_time=time.time() 8 # print('run time is %s' %(stop_time-start_time)) 9 # return wrapper 10 # 11 # @timmer 12 # def index(): 13 # 14 # time.sleep(3) 15 # print('welcome to index') 16 # 17 # index() 18 19 20 21 # import time 22 # 23 # def timmer(func): 24 # def wrapper(): 25 # start_time=time.time() 26 # func() #index() 27 # stop_time=time.time() 28 # print('run time is %s' %(stop_time-start_time)) 29 # return wrapper 30 # 31 # 32 # @timmer #index=timmer(index) 33 # def index(): 34 # time.sleep(3) 35 # print('welcome to index') 36 # 37 # 38 # # f=timmer(index) 39 # # # print(f) 40 # # f() #wrapper()---->index() 41 # 42 # # index=timmer(index) #index==wrapper 43 # 44 # index() #wrapper()-----> 45 46 47 48 #流程分析 49 # import time 50 # def timmer(func): 51 # def wrapper(): 52 # start_time=time.time() 53 # func() 54 # stop_time=time.time() 55 # print('run time is %s' %(stop_time-start_time)) 56 # return wrapper 57 # 58 # @timmer #index=timmer(index) 59 # def index(): 60 # time.sleep(3) 61 # print('welcome to index') 62 # 63 # 64 # index() #wrapper() 65 66 67 68 69 70 71 72 73 # import time 74 # def timmer(func): 75 # def wrapper(*args,**kwargs): 76 # start_time=time.time() 77 # res=func(*args,**kwargs) 78 # stop_time=time.time() 79 # print('run time is %s' %(stop_time-start_time)) 80 # return res 81 # return wrapper 82 # 83 # @timmer #index=timmer(index) 84 # def index(): 85 # time.sleep(3) 86 # print('welcome to index') 87 # return 1 88 # 89 # @timmer 90 # def foo(name): 91 # time.sleep(1) 92 # print('from foo') 93 # 94 # 95 # res=index() #wrapper() 96 # print(res) 97 # 98 # res1=foo('egon') #res1=wrapper('egon') 99 # print(res1) 100 # 101 # 102 103 # def auth(func): 104 # def wrapper(*args,**kwargs): 105 # name=input('>>: ') 106 # password=input('>>: ') 107 # if name == 'egon' and password == '123': 108 # print('�33[45mlogin successful�33[0m') 109 # res=func(*args,**kwargs) 110 # return res 111 # else: 112 # print('�33[45mlogin err�33[0m') 113 # return wrapper 114 # 115 # 116 # 117 # @auth 118 # def index(): 119 # print('welcome to index page') 120 # @auth 121 # def home(name): 122 # print('%s welcome to home page' %name) 123 # 124 # index() 125 # home('egon') 126 # 127 128 129 # login_user={'user':None,'status':False} 130 # def auth(func): 131 # def wrapper(*args,**kwargs): 132 # if login_user['user'] and login_user['status']: 133 # res=func(*args,**kwargs) 134 # return res 135 # else: 136 # name=input('>>: ') 137 # password=input('>>: ') 138 # if name == 'egon' and password == '123': 139 # login_user['user']='egon' 140 # login_user['status']=True 141 # print('�33[45mlogin successful�33[0m') 142 # res=func(*args,**kwargs) 143 # return res 144 # else: 145 # print('�33[45mlogin err�33[0m') 146 # return wrapper 147 # 148 # @auth 149 # def index(): 150 # print('welcome to index page') 151 # @auth 152 # def home(name): 153 # print('%s welcome to home page' %name) 154 # index() 155 # home('egon')
| 迭代器 |
可以被next()函数调用并
1、迭代的概念:
重复+上一次迭代的结果为下一次迭代的初始值
重复的过程称为迭代,每次重复即一次迭代,
并且每次迭代的结果是下一次迭代的初始值
不断返回下一个值的对象称为迭代器:Iterator。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable
生成器都是迭代器,因为生成器有next方法,迭代器不一定是生成器。
2、为什么要有迭代器
#为什么要有迭代器?对于没有索引的数据类型,必须提供一种不依赖索引的迭代方式
#可迭代的对象:内置__iter__方法的,都是可迭代的对象
3、迭代器的优缺点:
优点:
1.提供了一种不依赖下标的迭代方式
2.就跌迭代器本身来说,更节省内存
缺点:
1. 无法获取迭代器对象的长度
2. 不如序列类型取值灵活,是一次性的,只能往后取值,不能往前退
4、迭代器的实现
1 l = [1, 2, 3] 2 count = 0 3 while count < len(l): # 只满足重复,因而不是迭代 4 print('====>', l[count]) 5 count += 1 6 7 l = (1, 2, 3) 8 count = 0 9 while count < len(l): # 只满足重复,因而不是迭代 10 print('====>', l[count]) 11 count += 1 12 13 s='hello' 14 count = 0 15 while count < len(s): 16 print('====>', s[count]) 17 count += 1
1 #为什么要有迭代器?对于没有索引的数据类型,必须提供一种不依赖索引的迭代方式 2 3 #可迭代的对象:内置__iter__方法的,都是可迭代的对象 4 5 [1,2].__iter__() 6 'hello'.__iter__() 7 (1,2).__iter__() 8 9 {'a':1,'b':2}.__iter__() 10 {1,2,3}.__iter__() 11 12 #迭代器:执行__iter__方法,得到的结果就是迭代器,迭代器对象有__next__方法 13 i=[1,2,3].__iter__() 14 15 print(i) 16 17 print(i.__next__()) 18 print(i.__next__()) 19 print(i.__next__()) 20 print(i.__next__()) #抛出异常:StopIteration 21 22 23 i={'a':1,'b':2,'c':3}.__iter__() 24 25 print(i.__next__()) 26 print(i.__next__()) 27 print(i.__next__()) 28 print(i.__next__()) 29 30 dic={'a':1,'b':2,'c':3} 31 i=dic.__iter__() 32 while True: 33 try: 34 key=i.__next__() 35 print(dic[key]) 36 except StopIteration: 37 break 38 39 40 41 s='hello' 42 print(s.__len__()) 43 44 print(len(s)) 45 46 len(s)====== s.__len__() 47 48 49 s={'a',3,2,4} 50 51 s.__iter__() #iter(s) 52 53 i=iter(s) 54 print(next(i)) 55 print(next(i)) 56 print(next(i)) 57 print(next(i)) 58 print(next(i)) 59 60 61 #如何判断一个对象是可迭代的对象,还是迭代器对象 62 from collections import Iterable,Iterator 63 64 'abc'.__iter__() 65 ().__iter__() 66 [].__iter__() 67 {'a':1}.__iter__() 68 {1,2}.__iter__() 69 70 f=open('a.txt','w') 71 f.__iter__() 72 73 74 #下列数据类型都是可迭代的对象 75 print(isinstance('abc',Iterable)) 76 print(isinstance([],Iterable)) 77 print(isinstance((),Iterable)) 78 print(isinstance({'a':1},Iterable)) 79 print(isinstance({1,2},Iterable)) 80 print(isinstance(f,Iterable)) 81 82 83 84 #只有文件是迭代器对象 85 print(isinstance('abc',Iterator)) 86 print(isinstance([],Iterator)) 87 print(isinstance((),Iterator)) 88 print(isinstance({'a':1},Iterator)) 89 print(isinstance({1,2},Iterator)) 90 print(isinstance(f,Iterator)) 91 92 93 ''' 94 可迭代对象:只有__iter__方法,执行该方法得到的迭代器对象 95 96 迭代协议: 97 对象有__next__ 98 对象有__iter__,对于迭代器对象来说,执行__iter__方法,得到的结果仍然是它本身 99 100 101 ''' 102 f1=f.__iter__() 103 104 print(f) 105 print(f1) 106 print(f is f1) 107 108 109 l=[] 110 i=l.__iter__() 111 112 print(i.__iter__()) 113 print(i) 114 print(l) 115 116 117 dic={'name':'egon','age':18,'height':'180'} 118 print(dic.items()) 119 120 for k,v in dic.items(): 121 print(k,v) 122 123 i=iter(dic) 124 while True: 125 try: 126 k=next(i) 127 print(k) 128 except StopIteration: 129 break 130 for k in dic: #i=iter(dic) k=next(i) 131 print(k) 132 print(dic[k]) 133 134 135 136 137 l=['a','b',3,9,10] 138 for i in l: 139 print(i) 140 141 142 143 with open('a.txt','r',encoding='utf-8') as f: 144 for line in f: 145 print(line) 146 print(next(f)) 147 print(next(f)) 148 print(next(f)) 149 print(next(f)) 150 print(next(f)) 151 print(next(f)) 152 print(next(f)) 153 print(next(f))
| 内置函数 |
all print (all([1,-5,3]))
any print (any([1,-5,3]))

bin(255) ——>十进制转二进制
4、bool 判断真假
5、byte array 可修改的二进制格式 字符串不能修改、元祖不能修改
6、call
7、chr chr(97) 把数字对应的ascii码返回
8、ord ord(‘a’) 把字母对应的ascii码数字返回
9、compile 用于把代码进行编译
10、dived divmod(5,3)
11、eval
12、exec
| 匿名函数 |
filter 过滤后合格的打印
map 传参数,并赋值打印结果
reduce
import functools
functors.reduce

如上图:lambda x:x[1]是按照value排序的。
x 是所以的元素x[1]取value的值

| Json |
序列化 json.dumps()
反序列号 json.loads()
jason只能处理简单的。如果需要在函数中使用处理序列化,需要picle。picle只能在python本语言使用。
| 目录结构 |
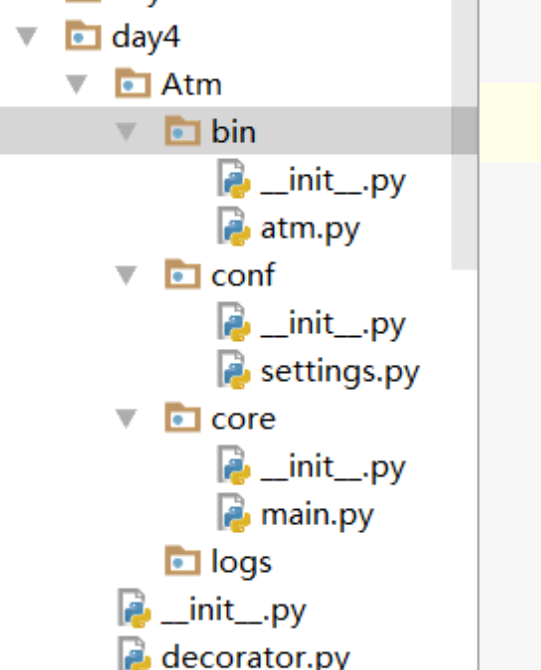
同级目录导入
