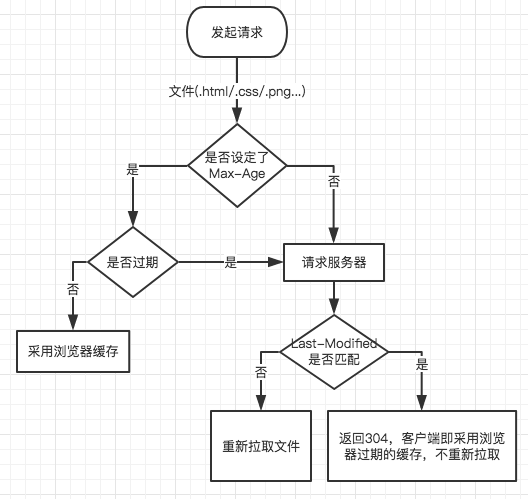
可以看到浏览器的缓存机制分为两个部分。
- 当前缓存是否过期?
- 服务器中的文件是否有改动?
第一步:判断当前缓存是否过期
这是判断是否启用缓存的第一步。如果浏览器通过某些条件(条件之后再说)判断出来,ok现在这个缓存没有过期可以用,那么连请求都不会发的,直接是启用之前浏览器缓存下来的那份文件:

图中看到这个css文件缓存没有过期,被浏览器直接通过缓存读取了出来,注意这个时候是不会向浏览器请求的! 如果过期了就会向服务器重新发起请求,但是不一定就会重新拉取文件!
第二步:判断服务器中的文件是否有改动
缓存过期,文件有改动
如果服务器发现这个文件改变了那么你肯定不能再用以前浏览器的缓存了,那就返回个200并且带上新的文件:
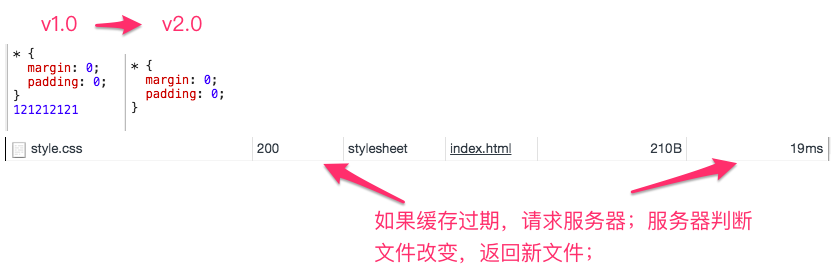
缓存过期,文件无改动
如果发现虽然那个缓存虽然过期了,可你在服务器端的文件没有变过,那么服务器只会给你返回一个头信息(304),让你继续用你那过期的缓存,这样就节省了很多传输文件的时间带宽啥的。看下图:

过期了的缓存需要请求一次服务器,若服务器判断说这个文件没有改变还能用,那就返回304。浏览器认识304,它就会去读取过期缓存。否则就真的传一份新文件到浏览器。
经过上面的流程梳理,我们基本了解整个缓存处理过程,不过对于前端来说,我们需求无非就是使用缓存或者不使用缓存,在了解下面内容之后我们再根据原理去慢慢实现我们的需求。
http头部缓存相关key:
首先我们要先根据http请求头以及响应头 先看一些跟缓存相关的报文头cache-control, if-none-match, if-modified-since, Etag,expires, last-modified等。
request header缓存相关:
cache-control:其缓存指令对于前段常用的有如下no-cache、no-store、max-age这几个值;
no-cache:
表面意为“数据内容不被缓存”,而实际数据是被缓存到本地的,只是每次请求时候直接绕过缓存这一环节直接向服务器请求最新资源,由于浏览器解释不一样,例如ie中我们设置了no-cache之后,请求虽然不会直接使用缓存,但是还会用缓存数据与服务器数据进行一致性检测(也就是说还是有几率会用到缓存的),firefox中则完全无视no-cache存在。
no-store:
指示缓存不存储此次请求的响应部分。与no-cache比较来说,一个是不用缓存,一个是不存储缓存;按理来说这个设置更加粗暴直接禁用缓存,但是具体实现起来 浏览器之间差异却特别大,一般不会直接用该字段进行设置,不过no-store是为了防止缓存被恶意修改存储路径导致信息被泄露而设置的。毕竟有它的用处,在firefox中实现缓存是通过文件另存为将缓存副本保存到本地,直接利用no-cache对其是无效的,如果加上no-store设置的话 则可以起到与no-cache一样的效果;即:cache-control:no-cache,no-store;可以确保在支持http1.1版本中各大浏览器回车后退刷新无缓存;再加上Pragma: no-cache设置兼容版本1.0即可(不过为了防止一致性检测时候的万一我们还是最好加上一致性检测的内容,如下所示几种方式);
max-age:
例如Cache-control: max-age=3;表示此次请求成功后3秒之内发送同样请求不会去服务器重新请求,而是使用本地缓存;同样我们如果设置max-age=0表示立即抛弃缓存直接发送请求到服务器。
一致性检测分为两种方式:1.检测日期是否过期,2.检测资源是否更新。
if-none-match:
该字段与响应中的eTag一起使用,表示检查实体是否有更新改变;客户端第一次发送请求时候响应报文会包含字段Etag,表示资源状态,当资源改变后该值也会改变(客户端不必关心该值怎么生成)
然后缓存保存下该字段,第二次已经有该缓存时候在浏览本地缓存时候会将该值赋给if-none-match字段发送给服务器,服务器将发送的值与当前的状态进行对比,如果值一样的话则答复304去使用缓存数据,如果值改变了则发送最新数据给客户端替代现有缓存数据,并且返回状态200。
if-modified-since:
该字段与last-modified配合使用,跟上述原理差不多,都是响应端先返回一个last-modified时间字段,再次请求时候 request头部会将缓存中的last-modified字段拿出来赋给if-modified-since,发送给服务器,服务器去判断时间是否过期,如未过期则返回304,告诉客户使用缓存数据,如果过期则重新返回一个last-modified并且返回200。
repsonse header缓存相关:
Etag:
刚才也说过 是跟if-none-match配合去使用,它根据实体内容生成的一段hash字符串(类似于MD5或者SHA1之后的结果),可以标识资源的状态。 当资源发送改变时,ETag也随之发生变化。使用Etag主要是为了解决根据时间无法解决的问题:比如文件修改频繁(秒之内修改),导致根据时间无法判断是否更新;以及修改时间变了,但是内容没变(我们应该认为该文件是没变的)
expires:
表示缓存过期时间例如:expires:Mon Dec 30 2011 11:01:19 GMT,跟cache-control中的max-age作用一样,不过在碰见max-age之后,该值会被覆盖从而被max-age替代;
last-modified:
表示文件最后修改时间;
实现有关前端对于缓存的操作:
使用缓存:
认情况下,浏览器都会使用缓存数据,在f5刷新情况下 浏览器会发送一致性验证去服务器验证是否使用缓存,而浏览器直接回车则表示直接应用缓存不需要去服务器验证;所以我们就按照f5刷新去解释实现使用缓存:
一般来说前端默认是使用缓存的,默认情况下服务器端以及前端都会使用缓存数据,或者是根据etag或者是根据max-age或者是根据expires根据服务器不同去不同实现;
实际中大部分不需要我们手动去实现,而有些我们不确定是否使用缓存的情况下我们可以手动加以干涉强制使用缓存数据:例如某个静态文件包括html或者图片我们需要使用缓存来提高处理速度,
方法一:
在服务器进行配置其max-age或者expires使其设置一个过期值为当前一年之后。这样每次进行检验时候都会使用缓存中文件.例如在.htaccess中
<IfModule mod_headers.c>
<FilesMatch ".(gif|jpg|jpeg|png|ico)$">
Header set Cache-Control "max-age=604800"
</FilesMatch>
方法二:
前端设置if-modified-since去设置一个上次修改时间大于当前日期。
方法三:
服务器端根据etag去判断是否匹配来根据实际业务来使用缓存;
后面两个方法属于弱缓存数据头,需要浪费http连接,所以建议使用第一种方式;
禁用缓存:
方法一:
可以在meta标签标明
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
方法二:
也可以动态去setRequestHeader,强制不用缓存设置组合如下:
cache-control='no-cache,no-store'
pragma='no-cache'
if-modified-since=0;
方法三:
请求端设置if-modified-since为已经过期的某个时间,可以是几年前或者几十年前。
方法四:
url后面加随机数或者时间戳url += “&random=” + Math.random():原理就是每个请求的url都不一样这样一来缓存中找不到对应数据,就自动去服务器寻找最新资源;
缓存机制流程
本次使用了Cache-Control&Last-Modified来做为缓存机制的判断条件。当然还有多种方式可以使用: