大数据面试题总结
Hadoop
1、由来
Hadoop是apache lucene的创始人doug cutting开发的广泛使用的文本搜索库
雏形于2002年的apache nutch,nutch是java编写的开源的搜索引擎
2003年Google发布了GFS,提供了海量的文件存储系统
2004年nutch的创始人doug cutting根据GFS编写了分布式文件存储系统NDFS
2004年Google发布了MapReduce
2005年doug cutting根据MapReduce,在nutch搜索引擎上实现了该功能
2006年,Yahoo雇佣doug cutting,他将nutch和MapReduce升级命名为hadoop
2、Hadoop1.X和Hadoop2.X的区别
Hadoop1.x中MR即提供了运算,也提供了资源调度,耦合性较大, 而Hadoop2.x以后推出了YARN的概念,MR只负责运算,Yarn负责资源调度,Hadoop1.x中单点故障并没有解决,而Hadoop2.x之后提出了高可用机制,避免了namenode的单点故障问 题,并且Hadoop1.x的默认块大小是64M,Hadoop2.x的默认块大小是128M
3、概念
Hadoop是一个文件系统架构
他的核心是HDFS、MapReduce和yarn
HDFS:分布式文件存储
namenode:主要职责就是存储数据的元数据,也会用来接收datanode的心跳
datanode:数据节点,存储数据块(128Mblock)
SecondaryNameNode:定期的合并fsimage和edits帮助,NN完成工作,减少NN的启动时间
MapReduce:分布式计算框架
map+reduce
map:映射,将文本映射为对象进行操作,一行一map
reduce:计算,一key一reduce
Yarn:资源调度
ResourceManger:负责任务调度
NodeManger:执行任务
4、特点
优点
(1)HDFS可以存储大量的数据,只要不超过整个集群的总容量即可
(2)Yarn资源管理 任务调度
(3)数据容错性
缺点
(1)不适合低延迟的数据访问
(2)不适合高效的存储大量的小文件
(3)不支持多用户写入和任意修改数据
5、常用的调度器
(1)先进先出调度器(FIFO)
是hadoop默认的一种批处理调度器,按照作业的优先级高低,在按照到达时间的先后选择被调度的作业
(2)公平调度器(Fair Scheduler)
是一种赋予作业的资源的方法,目的是随着时间的推移,让每一个作业都能够获得相同的共享资源,当有一个作业时,他会启动整个集群,当有作业提交空闲时,系统将会自动把空闲的task给新的作业
(3)容量调度器(Capacity Scheduler)
支持多个队,对每个队列可配置一定的资源配置,每个队列采用FIFO调度策略,为了防止同一用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定
调度时,首先计算出每个队列中正在运行的任务与所需计算资源之间的比值,选择一个该比值最小的队列,其次按照作业优先级和提交时间顺序选择,同时考虑用户资源量限制和内存限制
6、hadoop节点的动态上线下线的大概操作
--节点上线
1.关闭新增节点的防火墙
2.在 NameNode节点的hosts文件中加入新增数据节点的hostname
3.在每个新增数据节点的hosts文件中加入NameNode的hostname
4.在NameNode节点上增加新增节点的SSH免密码登录的操作
5.在NameNode节点上的dfs.hosts中追加上新增节点的hostname,
6.在其他节点上执行刷新操作:hdfs dfsadmin -refreshNodes
7.在 NameNode 节点上,更改slaves文件,将要上线的数据节点hostname追加到slaves文件中
8.启动DataNode节点
9.查看NameNode的监控页面看是否有新增加的节点
--节点下线
1.修改/conf/hdfs-site.xml文件
2.确定需要下线的机器,dfs.osts.exclude文件中配置好需要下架的机器,这个是阻止下架的机器去连接NameNode
3.配置完成之后进行配置的刷新操作./bin/hadoop dfsadmin -refreshNodes,这个操作的作用是在后台进行block块的移动
4.当执行三的命令完成之后,需要下架的机器就可以关闭了,可以查看现在集群上连接的节点,正在执行 Decommission,会显示:Decommission Status : Decommission in progress 执行完毕后,会显示:Decommission Status : Decommissioned
5.机器下线完毕,将他们从 excludes 文件中移除
7、核心组成(Common、HDFS、MapReduce、Yarn)
Common:为其他模块提供基础设施
Hdfs:分布式文件系统
MapReduce:程序运行计算框架
Yarn:资源调度,任务管理
8、Hdfs上传机制(副本机制)
(1)client有想要上传的数据,交给NN
(2)NN和DN进行通信,查看DN是否忙碌,不忙碌,NN制定计划,client开始上传数据
(3)Client开始切割数据(128M就切割)
(4)Client根据NN给的计划,找到第一个DN,上传这个副本,client等待
(5)DN1拿着数据去找下一个DN,依次类推,直到上传到最后一个DN
(6)最后一个DN对内存ack确认
(7)NN对ack,client消失
9、Hdfs下载机制
(1)client携带者文件请求
(2)NN根据client在的linux位置,根据就近原则,NN制定计划
(3)Client根据NN给的计划给DN,要DN把这个细碎的block合并,最后下载保存到本地目录
10、心跳机制
namenode和datanode之间是有心跳机制的,datanode每三秒会发送一次心跳给namenode,如果三秒内datanode没有向namenode发送心跳,那么namenode会认为该datanode是待死亡状态,会启动一个新的datanode,让其它datanode将数据备份给这个新的datanode,如果五分钟(600秒)内待死亡的datanode向namenode重新发送心跳,则恢复其工作,下线一个最忙的datanode,维持集群的正常工作
11、机架策略(能够保证数据不丢失)
(1)第一个副本,根据client所在的数据节点,就近原则
(2)第二个副本,和第一个副本所在的机架的不同机架的不同节点
(3)第三个副本,和第二个副本所在的机架的相同机架的不同节点
12、日志合并(fsimage、edits)
Fsimage:更新文件 edits:初始化日志
(1)当客户端向NN发出更新原数据请求时,NN会根据更新的数据内容存放的位置从而来更新好原数据
(2)Fsimage保存了自更新的元数据的检查点
(3)Edits保存最新检查点更新后的命名空间的变化
(4)从最新检查点后,hadoop将对每个文件的更新操作都保存到edits中,为了避免edits不断扩大,secondaryNameNode会周期性的将fsimage和edits合并成新的fsimage,edits在做更新后的记录
13、Hadoop的namenode宕机如何处理?
如果namenode宕机,nn会根据他自己保存的那一份元数据和snn的冷备份数据进行恢复
一般的nn都会有HA配置,一个是active,一个是standy,保证集群一定会有一个活着的nn
14、三个datanode中有一个宕机,该怎么办
因为namenode和datanode之间是有心跳感知的,当感知到datanode宕机后,nn会启动一个新的dn,保证集群中永远有三个nn在工作,并且让这个新的dn去宕机的那个dn 上面copy数据进行备份
15、Hadoop的缓存机制?
Hadoop的缓存机制其实就是DistributedCash,在一个job提交前,将需要的数据copy到每个机器上进行缓存处理,类似于spark中的RDD广播
16、Hadoop的数据倾斜
参考: https://www.cnblogs.com/tongxupeng/p/10259552.html
原因:
Hadoop之所以会出现数据倾斜的本质是因为key值的分布过于不均匀,主要表现在某个或多个reduce在执行的时候,卡在99%不动了,那么就肯定是出现了数据倾斜的问题了
解决方法:
(1)最本质的就是合理的设置key,在map阶段为key加上一个随机数,有了随机数的key被分配到同一节点的几率就会大大的降低,然后到了reduce阶段将随机数给去掉即可
(2)增加jvm的内存,这种方法的效果并不是很显著,提升硬件性能才是最好的
(3)自定义分区,写个自定义类,实现partition类,也是我们最常用的方法
(4)增加reduce的个数,一个key对应的是一个reduce,如果reduce多点,计算的节点也就多了,就可以略微的解决数据倾斜
(5)设置combinner合并,combinner的话其实就是map端的一个reduce,将相同key
(6)的值在map端进行合并成一个大文件,然后交给reduce进行处理,也是比较常用的方法
17、Yarn(主从模式-->出现单点故障-->产生故障恢复)
(1)Yarn是hadoop2的任务资源调度管理系统,主要是由MR1演化过来的
(2)Yarn使得之前的hadoop1的jobTracke资源管理和作业调度分离了,分成了resourceManager和APPMasterApplication两个进程
resourceManager主要管理任务调度和资源分配
APPMasterApplication负责管理事务,任务监控,容错机制等功能
(3)Yarn的出现使得好多框架都能够运行在同一个集群上
18、Yarn的角色
resourceManager:中心服务器,集群统一资源管理和任务调度
nodeManager:节点管理,管理自己的资源,听从主的任务
Container:容器,对资源(集合)的一个封装 (CPU内存IO)
jobHistoryServer:历史服务器 java平台
timelineServer:历史服务器 全平台
19、Yarn运行流程
(1)client向yarn中提交应用程序,yarn为该应用程序启动相应的资源(application应用程序,application的shell,以及用户程序等)
(2)RM为该应用程序分配一个container,与NM进行通信,并要求它在这个container中启动AM
(3)AM向RM进行注册,用户就可以通过RM直接查看到该应用程序的运行状况
(4)AM采用轮询的方式通过RPC协议向RM申请资源
(5)AM申请到资源之后,便与对应的NM进行通信,要求它启动任务
(6)NM为任务设置好运行环境(二进制程序,jar包,环境变量等)后,将启动任务写成一个脚本,运行该脚本启动任务
(7)各个任务通过RPC的协议向AM汇报自己的状态和进度,以让AM能够监控自己的运行状态,能够在任务失败的时候能够重新启动任务
(8)程序运行结束后,AM向RM注销并关闭自己
MapReduce
1、概念
MapReduce是一个分布式的运算程序的编程框架
MapReduce借鉴了函数式的思想,用map和reduce两个函数提供了高层的并发编程的抽象模型
核心功能是将用户编写的逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发在hadoop集群上
2、框架架构
有三个实例架构
MRAppmaster:负责整个程序的过程调度及应用协调
mapTask:负责map阶段的整个数据处理流程
reduceTask:负责reduce阶段的整个数据处理流程
3、处理流程
Mapper阶段
(1)先读取文件数据
(2)将读取的文件数据进行拆分处理
(3)拆分完成之后,将数据解析成KV对
(4)将解析后的KV对进行分区划分,并分区内进行排序合并
(5)在进行本地mapper端的combiner合并
Reduce阶段
(1)从mapper阶段获取到数据
(2)在reduce本地进行合并文件,并进行排序处理
(3)最后调用自己的reduce逻辑算法,对数据进行逻辑处理
(4)将处理完成之后的数据保存到hdfs上
4、序列化
由于java的序列化是一个重量级的序列化,java序列化会附带很多的其他额外信息(验证,header,继承体系等),不便于高效的网络传输,所以hadoop开发了一套自己的序列化机制(writable)
Writable:精简,高效,需要哪个属性就传输哪个属性值,大大提高了网络传输速度
如果自定义的序列化需要comparator,只需要实现writableComparator接口即可
5、Partition(分区)
(1)按照自己的需求进行分区(默认分区规则,根据key的hash%reducetask的数量)
(2)自定义分区(customerPartition)规则,继承partition
(3)在job对象中,设置自定义分区job.setPartitionClass(customerPartition.class)
6、Combiner(本地合并)
Combiner是将map端的文件进行一次本地合并,来提高网络IO流传输的优化之一
(1)自定义(customerCombiner),继承reduce
(2)在job中设置combiner规则,job.setCombinerClass(customerCombiner.class)
7、MR中combine和partition的作用
combine就是map端的reduce,可以将map端从环形缓冲区中溢写出来的多个小文件进行聚合,达到减少减少输出文件的目的,reduce在拉取的时候就方便的很多,可以提高reduce的效率
partition其实就是reduce端的负载均衡的一种方式,将map端产生的kv划分给每个专属的reduce(一key一reduce),默认使用的是hashpartition,我们可以自定义类来继承partition 类
8、5个阶段
(input、map、shuffle、reduce、output)
9、Spark和MR的区别
(1)Spark没有分布式存储系统,所以数据一般都来自于Hadoop的HDFS
(2)Spark是基于内存进行迭代计算的,MR是基于硬盘进行迭代计算的
(3)Spark是对MR的优化,是在MR的基础上发展而来
(4)MR只有map和reduce两个算子,Spark有很多丰富的算子
(5)Spark的RDD和RDD之间有血缘关系,数据丢失可以去上一个RDD中去寻找,MR中的数据丢失了就要重头再来
10、MR的shuffle
Map阶段的shuffle
Map端会处理数据并产生中间结果,这个中间的结果会写入磁盘,而不是hdfs,每次从split的数据中写入到map中,map处理一行数据之后的k v 值都会先放入kvbuffer中缓存kvbuffer会根据k v的顺序进行分区(partition),每个分区中的数据再按照k进行排序,在kvbuffer中写入的数据达到阈值时,数据开始往磁盘转移,这个过程叫做溢写(spill),在spill写入之前,会有第二次的排序,根据数据所属的partition进行排序,每个partition中的数据再根据key来排序,接着运行combiner,combiner也称作map层的reduce,目的是对将要写入磁盘的文件进行一次处理,这样写入磁盘的数据量就会减少,最后将数据写到本地磁盘产生spill文件,每个map会产生多个spill文件,每个map任务结束前,会通过归并算法将这些spill文件归并成一个文件。
Reduce阶段的shuffle
此时reduce就会远程拉取map端的分区的数据到reduce端的圆形缓冲区中,当达到圆形缓冲区的0.8时,就会溢写到reduce的临时文件中,此时reduce的各个分区就会拉取属于自己的数据(因为在map端就进行了分处理),把拿到的结果按照k进行一次归并处理,这个过程就会产生最终的结果,把结果放入hdfs即可
11、运行流程
(1)一个 mr 程序启动的时候,最先启动的是 MRAppMaster, MRAppMaster 启动后根据本次 job 的描述信息,计算出需要的 maptask 实例数量,然后向集群申请机器启动相应数量的 maptask 进程
(2)maptask 进程启动之后,根据给定的数据切片(哪个文件的哪个偏移量范围)范围进行数据处理,主体流程为
(3)MRAppMaster 监控到所有 maptask 进程任务完成之后(真实情况是,某些 maptask 进程处理完成后,就会开始启动 reducetask 去已完成的 maptask 处 fetch 数据),会根据客户指定的参数启动相应数量的 reducetask 进程,并告知 reducetask 进程要处理的数据范围(数据分区)
(4)Reducetask 进程启动之后,根据 MRAppMaster 告知的待处理数据所在位置,从若干台 maptask 运行所在机器上获取到若干个 maptask 输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果 KV,然后调用客户指定的outputformat将结果数据输出到外部存储
Zookeeper
1、概念
Zookeeper是apache旗下的一个开源的、分布式的应用协调服务的开源框架,它可以保证集群中其它程序的高可用和数据的一致性,是集群的监控者,其它程序的高可用机制全都离不开zk
从设计模式的角度理解:是一个基于观察者模式设计的分布式服务管理框架,他负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,zookeeper就将负责通知已经在zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似master/slave管理模式
Zookeeper = 文件系统 + 通知机制(本质上是一个小型的分布式文件存储系统)
提供的服务:分布式消息同步和协调机制、服务器节点动态上下线、统一配置管理、负载均衡、集群管理、分布式锁、分布式协调等功能
2、对zookeeper的理解
Zookeeper是开源的分布式应用协调服务,它主要有元数据存储,负载均衡,发布订阅,集群管理,master选举,namespace命名空间,分布式锁,分布式队列等功能
我们公司的kafka、hbase集群就是用了zookeeper集群了,配置的时候,使用的是ambari平台自行配置的
3、设计特点
为了保持数据的最终一致性
当集群中出现一个主的时候,其他的从会和主建立连接 当主发起数据的同步请求时 从会将数据的zxid发送给主 主进行id的对比 选出大的那个id的数据 如果主的ID大 那么主告诉所有的从 从将状态改为update 然后主进行广播数据让所有的从进行数据的同步 如果是从的ID大 那么主会修改自己的数据 然后进行广播
4、特点
(1)可靠性。实时性。等待无关,顺序性:数据原子性
(2)全局一致性:每一个server都保存了同一份副本
(3)顺序性:如果先发送消息a,消息a肯定会在消息b前面
(4)可靠性:如果消息被一台机器接受后,那么所有的机器都将会接受
(5)数据更新原子性:要么都成功,要么都失败,没有中间结果
(6)实时性;zookeeper保证客户端在同一时间范围内保证数据的一致性
5、角色(leader、follower、observer)
Leader:是事务请求的唯一调度者和处理者,leader决定调度工作,处理操作
Follower:处理客户端的读操作,将事务转发给leader,参与leader的投票选举
Observer:观察者,和follower差不多,但是他不参与leader的选举和和投票响应,其次是他不需要将数据持久化到磁盘,一旦observer重启,需要重新从leader中同步整个名字空间,为了防止集群的压力过大,增加吞吐量,减轻集群的压力。
6、zk中创建的临时节点在断开连接后会立马被注销吗
并不会,有一个session_timeout参数,当连接关闭后,只有超过了这个session_timeout参数设置的时间,临时节点才会被注销
7、四种节点类型(znode)
持久型节点
除非手动删除,否则会一直存在
临时节点
退出zookeeper后节点便消失
持久顺序型节点
特点同持久型节点,但是是有顺序的,节点名称后面会追加一个自增的数字
临时顺序节点
特点同临时节点,但是是有顺序的,节点名称后面会追加一个自增的数字
8、选举机制(投票机制)
9、分布式队列
队列方面,简单地讲有两种,一种是常规的先进先出队列,另一种是要等到队列成员聚齐之后的才统一按序执行。对于第一种先进先出队列,和分布式锁服务中的控制时序场景基本原理一致,这里不再赘述
第二种队列其实是在FIFO队列的基础上作了一个增强。通常可以在 /queue 这个znode下预先建立一个/queue/num 节点,并且赋值为n(或者直接给/queue赋值n),表示队列大小,之后每次有队列成员加入后,就判断下是否已经到达队列大小,决定是否可以开始执行了。这种用法的典型场景是,分布式环境中,一个大任务Task A,需要在很多子任务完成(或条件就绪)情况下才能进行。这个时候,凡是其中一个子任务完成(就绪),那么就去 /taskList 下建立自己的临时时序节点(CreateMode.EPHEMERAL_SEQUENTIAL),当 /taskList 发现自己下面的子节点满足指定个数,就可以进行下一步按序进行处理了。
10、分布式锁(独占式、控制时序)
独占式:所有的client都来试图来连接zookeeper,但最终只有一个client能够连接到zookeeper
控制时序:所有的client都来试图连接zookeeper,每个client都能够连接到zookeeper,他会在父节点下面创建带有序列号的子节点
Socket编程
Socket是一种套子节,用于描述IP和端口号的,程序通常通过socket向网络发起请求,或者应答网络请求,是网络编程的一种机制
RPC是网络远程协议

Flume
1、概念
Flume是cloudera提供的一个高可用,高可靠的分布式海量日志采集,聚合和传输的工具
支持各类数据的发送,还能够对数据进行简处理
2、ng和og区别(组件区别)
og(agent、collector、master三个组件)(source、channel、sink、collector、master)
Ng(agent一个组件)(source、channel、sink)
Og,可以存储数据,和数据采集
Ng:变成一个纯粹的数据传输采集工具
3、原理
flume将数据源收集到channel中,sink开始从channel中拉取数据,只用sink将数据拉取出来之后,channel才会将数据删除掉,这保证了数据的安全性和可靠性
4、Flume会丢失数据吗
引入了zookeeper
不会,channel可以设置成file,但是这个性能会远远低于memory
5、调优
Source:调节source的个数,可以批量运输到channel的even条数
Channel:适当的选择channel,file性能较差,但是容错性高,memory性能高,但是容错性低,可以直接使用kafka缓存,不用配置sink,因为kafka中有消费者消费数据
Sink:调节sink的个数,可以批量读取数据,增加bathsize的even的个数
6、Source、channel、sink
Source是用来收集数据的:file,avro,exec,http,syslog,NC,自定义source
Channel是对采集到的数据进行缓存:JDBC,memory,file
Sink是用于把数据发送到目的地的组件:file,avro,exec,hbase,logger,自定义
Azkaban
1、概述
Azkaban是由LinkedIn公司推出的一个工作流调度器(资源调度系统),主要应用为一个工作流内以一个特定的顺序运行一组工作和流程
2、特点
(1)兼容任何版本的hadoop
(2)易于使用的web界面
(3)简单的工作流上传
(4)方便设置工作之间的调度
(5)有关成功和失败的电子邮件提醒
(6).......
Hive
1、概念
Hive是由Facebook开源用于解决海量结构化数据的分析统计工具
Hive是个数据仓库,是基于Hadoop的,可以将结构化的数据映射为一张表,一般使用hive做数据分析,hive支持一种语法叫做HQL,HQL可以将sql语句翻译成MR提交到集群中执行
本质是,将HQL转化为MapReduce程序运行
处理存储是:HDFS
计算分析是:MapReduce
执行程序是:yarn
2、设计原则
(1)支持不同的存储类型,文本,hbase中的文件
(2)将元数据保存在关系型数据库中,大大较少了在查询过程中检查语义的时间
(3)可以直接使用存储在hadoop文件系统中的数据
(4)内置大量的UDF函数,来操作时间,字符串和其他数据挖掘工具
(5)支持自定义函数来完成内置函数无法实现的操作
(6)类SQL查询,将SQL语句转化为MapReduce的job在hadoop集群上运行
3、特点
优点
(1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写MapReduce,减少开发人员的学习成本。
(3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
(4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
(5)Hive支持用户自定义函数,用户可以根据自己的需求来自定义自己的函数,来实现内置函数没有的功能。
缺点
(1)hive不适合实时性较高的场景
(2)不能够迭代计算
(3)运行速度较慢,因为他基于MapReduce,还有hive没有索引功能
4、运行原理
(1)用户通过接口连接hive ,并发布hive sql
(2)Hive解析查询并制定计查询计划
(3)Hive将查询转换成MapReduce作业
(4)Hive在hadoop上执行MapReduce作业
1.用户提交查询等任务给driver
2.编译器获得该用户的任务plan
3.编译器根据用户任务plan去MetaStore中获取需要的hive的元数据信息
4.编译器得到元数据信息,对任务进行编译
5.将最终的计划提交给driver
6.driver 将计划转交给ExecutionEngine去执行,获取元数据
7.获取执行结果并且返回执行结果
5、Hive 解析hql转换成MR的过程
(1)将HQL进行解析
(2)将解析的HQL语句进行编译,编译成一个job任务
(3)对job任务进行优化
(4)优化之后调用hadoop进行执行
6、Hive的元数据包括哪些
表的元数据包括表的名称,属性,以及表所在的位置,还有建表时间等
7、架构
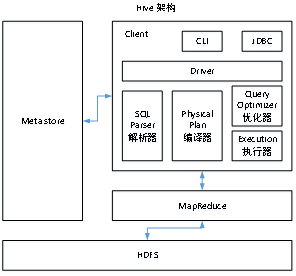
Hive架构分为四类
(1)Client接口:webUI、JDBC、命令行
(2)元数据存储(默认存储在derby中,线上使用一般mysql,能够多会话)
(3)Driver驱动(解释器,编译器,优化器,执行器)
(4)HDFS数据存储(user/hive/warehouse),MapReduce进行计算
8、基本数据类型
int、bigint、double、string
9、复杂的数据类型
Struct、map、array
10、Hive的文件存储格式
Textfile 行存储
存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高
Sequencefile 行存储
存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载
不能load加载数据
rcfile 列存储
存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低
不能load加载数据,使用插入形式添加数据
orcfile 列存储
是rcfile的升级版,运用ORC File可以提高Hive的读、写以及处理数据的性能
11、数据导入的四种方式
(1)数据在linux:load data local inpath ‘ /in/data’ into table student;
(2)数据在hdfs:load data inpath ‘/in/data’ into table student;
(3)创建表的时候导入:create table student select * from studnet1t;
(4)直接导入数据:insert into table student select * from student1;
12、数据导出的几种方式
(1)insert overwrite local directory ‘/in/data’ select * from student;
(2)使用hadoop命令:hadoop fs -get /in/data ./
(3)使用sqoop数据迁移工具
13、Hive的两个重要参数是什么
Hive -e
从命令行执行指定的HQL
Hive -f
hql执行hive脚本命令
14、hive的自定义函数
UDF:一进一出
UDAF:多进一出
UDTF:一进多出
15、Hive的分区分桶
为了提高查询效率,数据存储在hdfs上
分区对应的是文件夹,分桶对应的文件
分区时按照key进行切割数据的,容易造成数据倾斜;分桶是按照hash函数进行切割数据的,相对比较均匀
分桶是随机切割数据库,分区是非随机切割数据库
分区是粗粒度的数据处理,分桶对应的是细粒度的数据处理
16、hive内部表和外部表的区别
创建表:
如果创建的是内部表,数据来源会移动到表,如果创建的是外部表,数据来源不会丢失,相当于是copy到表中
删除表:
内部表的元数据和数据都是由表本身保存,删除表后元数据和数据都会丢失
外部表的元数据是保存在hdfs之上,数据由表保存,删除表后元数据会丢失,但是数据不会丢失
17、Hive排序的关键字
(1)order by:全局排序,一个reduce,数据规模大时,会需要大量的时间
(2)sort by:不是全局排序,数据在进入reduce中前完成排序,每个reduce内部排序,对全局结果集来说不是排序
(3)distribute by:按照指定的字段对数据进行划分输出到不同的reduce中,相当于MR中的partition分区,结合sort by使用
(4)Cluster by:当distribute 和sort的字段相同时,可以使用cluster by
18、Hive和数据库的区别
hive除了和数据库的SQL类似之外,其他没有相同之处,因为hive是数据仓库,本身不存在存储和计算的
|
|
Hive |
数据库 |
|
查询语言 |
是HQL |
是SQL |
|
数据存储位置 |
存储在hdfs上 |
存储在自己的系统中 |
|
底层执行原理 |
底层是MapReduce |
底层是executor执行器 |
|
数据格式 |
可以用户自定义 |
有自己的系统定义格式 |
|
数据更新 |
只读,不可写 |
支持数据更新 |
|
索引 |
Hive没有索引,因为查询数据的时候是通过MapReduce暴力查询所有数据,所以延迟较高 |
支持索引功能 |
|
延迟性 |
延迟较高 |
延迟较低 |
|
数据规模 |
Hive存储、数据量超级大 |
只能存储一些少量的业务数据 |
19、数据倾斜的原因
(1)key分布不均
(2)数据本身问题
(3)Sql语句问题
(4)建表考虑不周问题
20、企业优化
(1)fetch抓取,更改为more之后,在全局查询、limit、字段查找的时候不需要走MapReduce程序
(2)开启本地模式,开启之后,在数据量小的情况下,会节省大量的时间
set hive.exec.mode.local.auto=true;
(3)小表驱动大表的时候可以关闭mapjoin功能
(4)大表join大表的时候,会由于jvm内存不够导致oom,这是可以将key为null值过滤掉或者将key为null的值替换为其他值(NVL函数)
(5)动态分区的调整
(6)Where子句中增加过滤器
(7)尽量使用left semi join ,因为semi在查询时,当左表指定的一条记录,在右表中找到,会立即停止扫面
(8)设置合理的map和reduce数
(9)limit调节
(10)开启并发执行
set hive.exec.parallel=true
(11)开启安全模式
(12)JVM重用(在mapper-site.xml中设置JVM重用的连接次数,默认等待时长是60S)
Hbase
1、概念
Hbase是根据google的bigtable延伸出来的一个项目
Hbase是一个高可用,高可靠,面向列,可伸缩,面向列的数据库
基于HDFS进行存储,zookeeper对其进行管理
hbase 的容量是非常大的,一个表可能有数十亿行数百万列,因为它是面向列的数据库,所以它进行查询的时候速度是非常快的,并且hbase的表结构是稀疏的,如果存储的是null,是不会占用底层 存储空间的
使用廉价的PC机,就能够实现横向扩展,来提高计算和存储能力
2、特点
海量存储(延伸了hadoop的特点,能够存储PB级别的数据)
列式存储(按照列族存储数据的)
易扩展(处理能力的扩展:RegionServer 存储能力的扩展:HDFS)
高并发(使用廉价的PC机器,实现高并发,地延迟的性能)
稀疏表(基于列式存储,能够存储大量的数据,当列是null时,不占用底层内存)
3、优点
(1)列可以动态增减,对于值是空值的列,不占用底层存储空间
(2)自动切分数据,使得数据存储自动且具有水平扩展能力
(3)支持高并发顺序读写操作(底层具有缓存机制)
(4)列式存储
(5)表数据是稀疏的多维映射表
(6)读写的严格一致性
(7)提供很高的数据读写速度
(8)良好的线性可扩展性
(9)提供海量数据
(10)对于数据故障,hbase是有自动的失效检测和恢复能力。
(11)提供了方便的与HDFS和MapReduce集成的能力。
4、缺点
(1)不支持条件查询,暂时只支持rowkey查询
(2)不能够实现故障切换,当master宕机后,这个存储系统都会挂掉
5、Hbase表结构
行键 列族 时间戳 版本 列值
6、架构
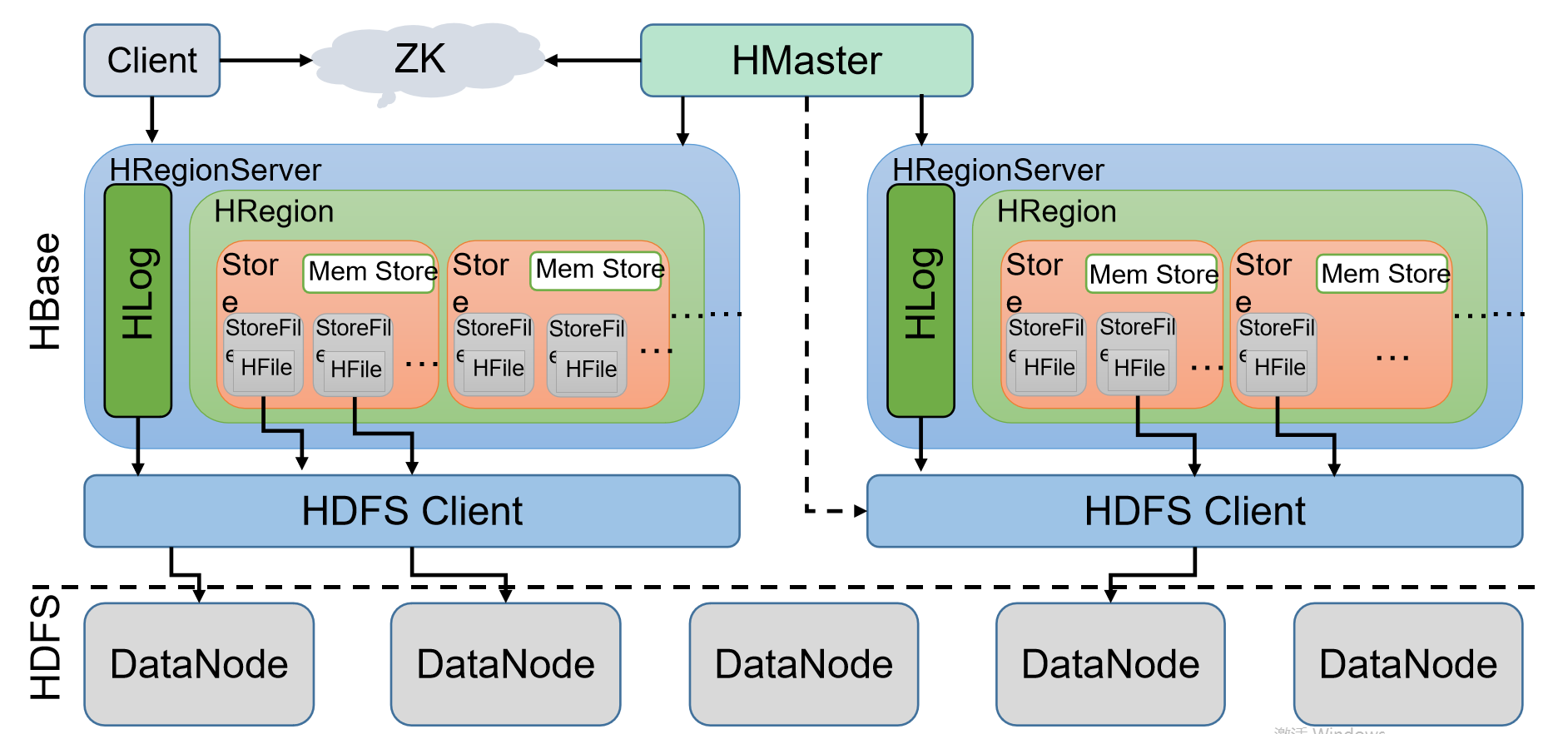
7、组件说明
Hmaster:进行一些管理及通信类的操作
HRegionServer:负责处理HMaster发送给它的HRegion,一个HRegionServer中包含多个HRegion和Hlog
Hlog:用来做灾难恢复的,数据会优先写入到HLog中
HRegion:HRegion中包含有MemStore和StoreFile,StoreFile中有HFile,HRegion 才是真正用来存储数据的
StoreFile:存储数据,里面包含HFile
HFile:Hbase中最小的存储结构,HFile从根本上来说就是HDFS中的文件
8、读流程
(1)client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据,meta中又存储了用户表的region信息
(2)根据namespace、表名和rowkey在meta表中找到对应的region信息
(3)根据rowkey找到这个region对应的regionServer
(4)返回rowkey对应的regionServer
(5)先从memstore找数据,如果没有,在到blockCache里面读取,如果blockCache还没有,在到storeFile上读取(为了读取效率)
(6)如果是从storeFile里面读取的数据,不是直接返回给客户端,而是先写入blockCache,在返回给客户端
9、写流程
(1)client向regionServer发送写请求(如果是旧版本的话,client先向-ROOT表-META表-请求)
(2)Hregionserver将数据写入到hlog,为了数据的持久化和恢复
(3)Hregionserver将数据写到内存memstore
(4)返回client写成功
10、Flush合并
(1)当memory达到内存的40%时,会flush
(2)当memory达到128M时,会flush,老版本是64M就会flush
11、数据合并
(1)当store达到3个时,会数据合并
(2)当store数据存储7天时,会数据合并
12、过滤器种类
列植过滤器—SingleColumnValueFilter
过滤列植的相等、不等、范围等
列名前缀过滤器—ColumnPrefixFilter
过滤指定前缀的列名
多个列名前缀过滤器—MultipleColumnPrefixFilter
过滤多个指定前缀的列名
rowKey过滤器—RowFilter
通过正则,过滤rowKey值。
13、Hive和hbase比较
(1)hive是建立在hadoop之上为了减少MapReduce jobs编写工作的批处理,hbase是为了支持弥补hadoop对实时操作的缺陷
(2)想象在操作RMDB数据库时,如果是全表扫面就是用hive+hadoop,如果是索引查询就是用hbase+hadoop
(3)Hive查询速度慢,底层是依赖于MapReduce计算的,hbase查询速度快,能够实现毫秒的数据查询,rowkey可以看做是索引
(4)Hive本身不存储索引,他是一个数据仓库,完全依赖于hdfs和MapReduce计算框架
(5)Hbase是一个物理表,不是一个逻辑表,它提供了一个超大的内存hash表,搜索引擎就是通过他来实现的
(6)Hbase是列式存储
(7)Hdfs作为存储底层,hdfs负责存储文件,hbase负责组织文件
14、Hbase和传传统数据库的区别
|
|
Hbase |
传统数据库 |
|
数据类型 |
只有简单的String类型 |
有丰富的数据类型 |
|
数据操作 |
只有插入,查询,删除,清空表操作,表与表之间是分离的,没有复杂的表与表之间的关系 |
有着丰富多样的函数连接操作 |
|
数据维护 |
只有更新操作 |
实质上是替换和修改操作 |
|
可伸缩 |
Hbase能够轻松的增加或减少机器的数量,并对错误的兼容性较高 |
需要中间间才行 |
|
存储模式 |
Hbase是列式存储的,每个列族都有不同的文件,rowkey即是他的索引,不需要在建立索引上花费时间,同时降低了大量的IO流传输 |
传统数据库是基于表结构存储的,需要手动建立索引,建立索引和存储需要花费大量的时间和空间 |
|
事务 |
Hbase只能实现单行事务,表与表之间没有事务 |
能够实现跨行,跨表的事务 |
15、实时查询的原理
Hbase可以理解为数据是存储在内存中的,一般响应时间是1秒内,写入数据的时候,数据先写入到内存中,如果达到128M才会写入到磁盘中,从内存中查询数据的时候,是不会进行数据的更新和合并的,这使得用户的写操作只要写入到内存中即可,保证了数据的IO流的高性能
16、Hbase宕机如何处理
宕机分为hmaster和hregionServer宕机两种
hregionServer宕机hmaster会将其管理的所有的region重新划分在其他的hregionServer上,由于数据和日志都保存到hdfs上,该操作是不会丢失数据的,所以数据的一致性是有保障的
Hmaster宕机,hbase没有单点问题,会启动多个hmaster,会通过zookeeper的masterElection机制保证总会有一个hmaster在对外提供服务
17、Hbase的容错与恢复机制
从架构中我们可以发现,每一个RegionServer中有一个HLog文件,在每次用户操作写入MemStore的同时,也会先向Hlog中写一份,Hlog文件会定期更新,并删除旧的文件(已经持久化到StoreFile中的数据)。当RegionServer宕机以后,Master会通过Zookeeper感知到,Master首先会处理遗留的Hlog文件,将其不同的Region的log数据进行拆分,分别放到相应的Region目录上,然后再将失效的Region重新分配到其他RegionServers上,RegionServer在load Region过程中,会发现有历史Hlog需要处理,因此会replay Hlog中的数据到MemStore中然后flush进StoreFile中完成数据的恢复
18、RK的热点问题
热点问题的话,其实就类似于MR中的数据倾斜问题,读取数据的时候,全部读取的是某一个HRegion,一个HRegion处理的数据太多,其它的太闲,我们一般是为RK加哈希,也可以用加盐和反转的方式(热点问题只会出现在Get+rk的查询方法中,Scan是不会出现热点问题的)
19、Rowkey设计
唯一性
使用时间戳+列名+列值
长度性
官方默认是100bit,实际使用是30-50bit,rowkey过长会占用内存,影响Hfile的存储效率,占用memstore无法缓存更多的数据降低检索效率
散列性
分区键+时间戳+列名+列值,就是说在设计的时候,将rowkey的高位用作散列字段,低位用作时间戳,这样就能将rowkey分散到各个region上面,提高负载均衡,避免出现热点问题
20、Scan和get的区别
(1)Scan
是全表扫描,每次查询一张表,他有一个startRow和endRow的功能,一次查询一个范围
可以通过setFilter()方法添加一个过滤器,这是分页,多条件查询的基础
可以通过setCaching与setBath方法提高查询速度(空间换取时间)
(2)Get
可以根据条件查询(时间戳、rowkey)获取唯一的一条记录
主要用来保证行的事务性
每个get是以row来做标记的,一个row中可以有很多family和column
21、Hbase中zookeeper的作用
保证任何时候,集群中一定会有一个Hmaster的存在
含有.ROOT.表,保存的是HRegion的具体地址
实时的监控HRegionServer的上线和下线
存储Hbase的元数据信息
22、为什么不使用Hbase自带的zookeeper
我们公司在搭建集群的时候,并没有使用hbase自带的zookeeper,因为如果hbase关闭后,那么他自带的zookeeper也会相应的关闭,我们公司有自己搭建的zookeeper集群,就算是hbase关闭,也不会影响到zookeeper的正常运行6
23、企业优化
(1)配置高可用配置
在HBase中Hmaster负责监控RegionServer的生命周期,均衡RegionServer的负载,如果Hmaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对Hmaster的高可用配置
(2)开启预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能
(3)Rowkey设计
Rowkey的目的主要是为了让数据能够均匀的分布在region中,有效的避免数据倾斜,这取决于预分区的设置长度性、唯一性、散列性,之后将rowkey转换为int之后进行hash%region的数量就是最终的rowkey
(4)数据存储时间
在创建表的时候,如果不是重要的数据,我们可以为该表设置一个数据声明周期, 比如说只存储两天,一天等
(5)内存优化
一般会把可用内存的70%分配给hbase的java堆内存,这个不建议分配太大
如果内存太大每次处理的数据就会太大,就会使hregionServer长期处于不可用状态,这个会因为框架使用内存太高导致系统内存不足,框架一样会被服务器拖死
如果内存太小会频繁发生拆分,频繁的发生IO流操作,导致性能的降低
(6)基础优化
允许hdfs的文件追加内容:可以有效的保证数据的同步和持久化
优化DataNode文件的最大打开数(默认4096),同一时间操作大量的文件数
优化延迟高的数据操作等待时间(默认60000ms)
开启数据的写入效率
优化RPC监听数量(默认30)
优化hstore的文件大小,(默认10G),如果是MR的任务,可以调低
实行hbase的获取行数
Flush、split机制
Sqoop(数据迁移工具,会使用就行)
hadoop生态圈上的数据传输工具。
可以将关系型数据库的数据导入非结构化的hdfs、hive或者bbase中,也可以将hdfs中的数据导出到关系型数据库或者文本文件中。
使用的是mr程序来执行任务,使用jdbc和关系型数据库进行交互。
import原理:通过指定的分隔符进行数据切分,将分片传入各个map中,在map任务中在每行数据进行写入处理没有reduce。
export原理:根据要操作的表名生成一个java类,并读取其元数据信息和分隔符对非结构化的数据进行匹配,多个map作业同时执行写入关系型数据库
Nginx
Ngnix是一款高性能的http和反向代理服务器
在项目中目的:静态资源服务器(动态很少用),负载均衡,日志收集、动静态资源分离
Lucene
1、概念
Lucene是java开发的一款全文检索引擎工具包
根据倒排索引的原理开发
2、全文检索
先建立索引,在对索引在进行检索的过程就是全文检索
3、流程(本质上就是创建索引和查询索引)
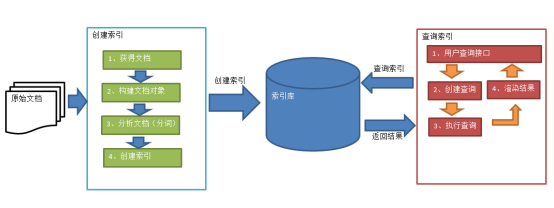
(1) 创建索引
原始文档->获取文档->构建文档对象->分析文档->构建索引->创建索引库
(2) 查询索引
用户通过搜索界面->创建查询->执行查询
从索引库中搜索->返回结果->渲染搜索结果
(term查询,多个域查询,范围查询,parseQuery查询,组合查询,关键词查询)
elasticSearch
1、认识
elasticSearch基于lucene,隐藏复杂性,提供了一个restful api接口和java api接口
elasticSearch是一个实时的分布式搜索和分析引擎,用于全文检索,结构化搜索、分析引擎,它可以准实时地快速存储、搜索、分析海量的数据。
2、Why使用ES
因为项目中使用到了模糊查询,特征匹配,这些查询会放弃索引查询,导致扫描表的时候是全表扫描,在百万级别的数据库中效率非常低下,而是用ES就会创建索引库,使用平时查询到的商品名称,id,描述... ,从而来提高查询效率
3、Elasticsearch是如何实现Master选举的
Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;
对所有可以成为master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
补充:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能。
4、在并发的情况下 ES如何保证读写一致
1.可以通过版本号使用乐观并发控制 以确保新版本不会被旧版本覆盖 由应用层来处理具体的冲突
2.另外对于写操作 一致性级别支持quorum/one/all 默认为quorum 即只有当大多数分片可用时才允许写操作,但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建
3.对于读操作,可以设置replilcation为sync,这使得操作在主分片和副本分片都完成后才会返回,如果设置replilcation为async时,也可以通过设置搜索请求参数 preference为primary
5、适用场景
作为实时的分布式集群技术,处理PB级别的数据,适用于大公司,单机版集群,也服务于小公司
6、elasticSearch和数据库类比
|
关系型数据库(比如Mysql) |
非关系型数据库(Elasticsearch) |
|
数据库Database |
索引Index |
|
表Table |
类型Type |
|
数据行Row |
文档Document |
|
数据列Column |
字段Field |
|
约束 Schema |
映射Mapping |
MySQL
mysql是关系型的,mysql当数据达到100w的时候,性能就开始降低了。关系型数据库。
在不同的引擎上有不同 的存储方式。
查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
开源数据库的份额在不断增加,mysql的份额页在持续增长。
缺点就是在海量数据处理的时候效率会显著变慢
MySQL和Oracle的区别
(1) 对事务的提交
MySQL默认是自动提交,而Oracle默认不自动提交,需要用户手动提交,需要在写commit;指令或者点击commit按钮
(2) 分页查询
MySQL是直接在SQL语句中写"select... from ...where...limit x, y",有limit就可以实现分页;而Oracle则是需要用到伪列ROWNUM和嵌套查询
(3) 事务隔离级别
MySQL是read commited的隔离级别,而Oracle是repeatable read的隔离级别,同时二者都支持serializable串行化事务隔离级别,可以实现最高级别的
读一致性。每个session提交后其他session才能看到提交的更改。Oracle通过在undo表空间中构造多版本数据块来实现读一致性,每个session
查询时,如果对应的数据块发生变化,Oracle会在undo表空间中为这个session构造它查询时的旧的数据块
MySQL没有类似Oracle的构造多版本数据块的机制,只支持read commited的隔离级别。一个session读取数据时,其他session不能更改数据,但
可以在表最后插入数据。session更新数据时,要加上排它锁,其他session无法访问数据
(4) 对事务的支持
MySQL在innodb存储引擎的行级锁的情况下才可支持事务,而Oracle则完全支持事务
(5) 保存数据的持久性
MySQL是在数据库更新或者重启,则会丢失数据,Oracle把提交的sql操作线写入了在线联机日志文件中,保持到了磁盘上,可以随时恢复
(6) 并发性
MySQL以表级锁为主,对资源锁定的粒度很大,如果一个session对一个表加锁时间过长,会让其他session无法更新此表中的数据。
虽然InnoDB引擎的表可以用行级锁,但这个行级锁的机制依赖于表的索引,如果表没有索引,或者sql语句没有使用索引,那么仍然使用表级锁。
Oracle使用行级锁,对资源锁定的粒度要小很多,只是锁定sql需要的资源,并且加锁是在数据库中的数据行上,不依赖与索引。所以Oracle对并
发性的支持要好很多。
(7) 逻辑备份
MySQL逻辑备份时要锁定数据,才能保证备份的数据是一致的,影响业务正常的dml使用,Oracle逻辑备份时不锁定数据,且备份的数据是一致
(8) 复制
MySQL:复制服务器配置简单,但主库出问题时,丛库有可能丢失一定的数据。且需要手工切换丛库到主库。
Oracle:既有推或拉式的传统数据复制,也有dataguard的双机或多机容灾机制,主库出现问题是,可以自动切换备库到主库,但配置管理较复杂。
(9) 性能诊断
MySQL的诊断调优方法较少,主要有慢查询日志。
Oracle有各种成熟的性能诊断调优工具,能实现很多自动分析、诊断功能。比如awr、addm、sqltrace、tkproof等
(10)权限与安全
MySQL的用户与主机有关,感觉没有什么意义,另外更容易被仿冒主机及ip有可乘之机。
Oracle的权限与安全概念比较传统,中规中矩。
(11)分区表和分区索引
MySQL的分区表还不太成熟稳定。
Oracle的分区表和分区索引功能很成熟,可以提高用户访问db的体验。
(12)管理工具
MySQL管理工具较少,在linux下的管理工具的安装有时要安装额外的包(phpmyadmin, etc),有一定复杂性。
Oracle有多种成熟的命令行、图形界面、web管理工具,还有很多第三方的管理工具,管理极其方便高效。
(13)最重要的区别
MySQL是轻量型数据库,并且免费,没有服务恢复数据。
Oracle是重量型数据库,收费,Oracle公司对Oracle数据库有任何服务。
CDH平台搭建
其实是Cludera Manager是一款端到端的应用
1、使用的原因
大量的服务器集群的搭建需要大量的时间
版本更新,以及更新之后的兼容性问题
2、优点
有webUI界面管理
兼容任何版本的hadoop
可扩展存储
分布式计算
版本划分清晰
更新速度快
Hadoop生态圈的认识
主要从hdfs的读写流程
Zookeeper分布式应用协调服务
Flume收集数据
Sqoop数据互导
Hbase数据库
Hive数据仓库
Kafka集群
Spark的大数据分析
数据来源的方式
通过web服务器tomcat收集到的日志数据,保存早tamcat的log中
通过js的sdk埋点的方法,document调用function,通过ngnix集群进行日志的收集
通过flume采集的数据保存到hdfs上或kafka中
谈项目(60%的时间*****重点)
项目的数据来源
数据收集
数据分析
数据存储
数据展示
Scala、Spark(另有word文档)
spark1和spark2的区别?
1.Spark2 Apache Spark作为编译器:增加新的引擎Tungsten执行引擎,比Spark1快10倍
2.Spark2.x引入了很多优秀特性,性能上有很大提升,API更易用。实现了离线计算和流计算的统一,实现了Spark sql和Hive Sql操作API的统一。
3.Spark 2.x基本上是基于Spark 1.x进行了更多的功能和模块的扩展,及性能的提升
4.Spark 2.x新特性:Spark Core/SQL,sparksession,Spark Streaming,其它特性等
Spark、flink、storm区别
|
|
Spark |
Flink |
Storm |
|
流式计算 |
支持 |
支持 |
支持 |
|
|
|
|
|
|
核心组件 |
SparkSQL |
|
|
|
发展方向 |
sparkSQL是核心组件,在性能上进行优化 |
流式计算和迭代计算支持力度将会更加增强 |
|
Spark和Flink都支持实时计算,且都可基于内存计算。Spark后面最重要的核心组件仍然是SparkSQL,
而在未来几次发布中,除了性能上更加优化外(包括代码生成和快速Join操作),还要提供对SQL语句的扩展和更好地集成。
至于Flink,其对于流式计算和迭代计算支持力度将会更加增强。
无论是Spark、还是Flink的发展重点,将是数据科学和平台API化,除了传统的统计算法外,还包括学习算法,同时使其生态系统越来越完善。
Spark
1、执行流程
1、client通过driver端的spark-submit提交任务
2、初始化自己的实例(sc)
3、通过调用main方法将任务提交到集群上
4、开始分配资源,调度worker,启动executor
5、executor反向和driver端进行注册
6、driver端要解析代码,记录RDD的依赖关系,解析逻辑,记录分区中的数据存放的位置
7、生成DAG有向无环图,将DAG有向无环图提交给DAGScheduler进行处理(DAGScheduler.runJob())提交每一个准备好了的阶段,准备好的阶段里面所有的task放入到一个taskSet中进行提交,提交到taskScheduler中
8、TaskScheduler将任务进行接收,并且通过序列化的方式StandaloneSchedulerBackEnd提交给executor端执行,并且监控任务的执行,故障前切换
9、Driver端和executor端通过SchedulerBakeEnd通信,保持Driver端和executor是连接的
10、executor接受任务,executor执行器,要执行SchedulerbackEnd发送过来的task信息,进行遍历,如果是多重集合则压平,然后把每一个任务进行反序列化,完毕以后使用tcp心跳进行发送
11、将任务放入到一个多线程的taskRunner对象中,然后扔进线程池Executor将任务从taskSet中取出,进行执行
12、执行完毕后,executor销毁,driver端销毁
DAGScheduler进行切分阶段:
先找到finalRDD,(resultStage),然后判断他是否存在父类,如果存在父类则进行下一步的遍历,如果迭代到最后没有了,直接提交将这个stag组成一个TaskSet提交给taskScheduler
如果你是resultStage那么就将这个taskSet组成resultTask,如果你是shuffleMapStage,那么就将taskSet组成一个shuffleMapTask
taskScheduler阶段:
TaskScheduler将任务进行接收,并且通过序列化的方式提交给executor端执行,并且监控任务的执行,故障前切换
Driver端和executor端通过SchedulerBakeEnd通信,保持Driver端和executor是连接的
2、Stage划分
Spark中的stage的划分依据是,从后往前推,遇到宽依赖就划分为一个stage,遇到窄依赖就将这个RDD加入到这个stage中,也就是说遇到shuffle类算子就会分出一个stage
Stage会根据宽依赖划分,窄依赖在一个stage中,只有遇到了宽依赖才会进行stage划分
Stage = shuffle + 1
Stage是一个抽象的,
Stage会划分为shuffleMapStage(发生shuffle时)和resultStage(最终的stage)
一个job中会有多个shuffleMAPStage和一个resultStage
3、driver的功能
负责向集群申请资源,向master注册信息,负责了作业的调度,负责作业的解析,生成stage并调度task到executor上,包括DAGScheduler,taskScheduler
4、RDD机制
Rdd是弹性式分布式数据集,简单的理解成一种数据结构,是spark框架上的一种通用的货币
所有算子都是基于rdd来执行的,不同的场景会有不同的rdd实现类,但是都可以进行互相转换
5、Spark的缺点
由于spark是基于内存的,所以对于内存的要求比较高,如果所要处理的数据比较大(1T或以上),就要进行调优方面的处理,否则就会发生OOM内存溢出的问题
6、宽依赖,窄依赖如何理解
宽依赖指的就是父RDD分区中的数据被多个子RDD分区所读取,就是宽依赖(多对多,一对多,多对一),宽依赖会导致stage的切分
窄依赖指的就是父RDD分区中的数据只被一个子RDD分区所读取,就是窄依赖(一对一)
7、DAG 划分stage过程
(1) 当RDD触发Action操作的时候,会导致SparkContext的runJob的方法执行,最后会调用DAGScheduler的submit方法。
(2) DAGScheduler的submit方法中,向eventProcessLoop对象发送了JobSubmitted消息。
(3) DAGSchedulerEventProcessLoop负责接收各种消息并进行处理,处理的逻辑在其doOnReceive方法中,方式是进行模式匹配,我们的JobSubmitted消息最后会交给dagScheduler的handleJobSubmitted方法进行处理。
(4) DAG划分stage的逻辑是根据finalRDD获取他的父RDD的依赖,判断依赖类型,如果是窄依赖,则将父RDD压入栈中,如果是宽依赖,则作为父Stage。
(5) 划分好stage后,则将stage进行提交,具体逻辑是根据当前stage获取父stage,如果父stage为空,则当前Stage为起始stage,交给submitMissingTasks处理,如果当前stage不为空,则递归调用submitStage进行提交。
8、Task 提交的过程
1)DAGScheduler将Job划分成由Stage组成的DAG后,就根据Stage的具体类型来生成ShuffleMapTask和ResultTask,然后使用TaskSet对其进行封装,最后调用TaskScheduler的submitTasks方法提交具体的TaskSet,而实际上是调用的TaskSchedulerImpl的submitTasks方法。
2)进入backend的reviveOffers()方法,给DriverEndpoint发送了一条ReviveOffers消息。Driver收到消息后调用makeOffers()方法,进行资源分配,最后调用launchTask方法将task提交到executor上。
9、Spark中广播变量的好处是什么
如果我们在driver端声明了一个变量,这个变量的数据特别庞大,而每个executor在读取这个变量的时候,是将这个变量给拷贝到每一个task下,会影响程序的运行速度,但是如果我们对这个变量进行广播处理,那么executor会将这个变量拷贝到blockmanger 中,使用的时候就会去blockmanger中去拿,相当于是自己拿自己的东西,速度会变得很快,广播变量也可以让每个executor使用的都是这一份的数据
10、RDD为什么不能进行广播
RDD是个抽象的概念
RDD是不存储数据的
如果想广播RDD中的数据,需要将RDD中的数据拉取到本地然后进行广播
11、ReduceByKey和GroupByKey的异同
相同点:
ReduceByKey和GroupByKey都是转换算子,都会产生shuffle,都可以改变分区数量
不同点:
ReduceByKey会对数据先进行分组,然后聚合GroupByKey只会单纯的对数据进行分组
12、Spark有哪些组件
Driver,Master,Worker,Client,SparkContext
13、RDD的五大特性
1)RDD是由多个分区组成的,在spark中,有多少个分区就有多少个task任务
2)RDD之间是含有血缘关系的
3)对某个RDD进行计算,其实是对RDD的每个split和partition进行计算的
4)如果RDD中的数据是按照kv类型的存储的,那么则可以使用分区器来控制分区
5)移动计算比移动数据更加划算
14、Spark的运行速度为什么比MR的运行速度快
1)Spark是基于内存进行运算操作的,虽然最终也会落地到磁盘,但还是以内存为主,减少了和磁盘的交互
2)高效的调度算法,基于DAG有向无环图运行程序
3)容错机制高,RDD和RDD之间是有血缘关系的,一个RDD的数据丢失可以去上一个对应的RDD中找数据
15、Driver端宕机如何解决
最好的解决方法就是调节Driver分配的内存大小
16、使用过的窗口函数有哪些
窗口函数使用的非常少,或者说就不使用,因为我们的SparkStreaming使用的是直连的方式,需要手动的去维护偏移量,如果要使用高级的api,也就是使用默认的Receiver方式,是无法去维护偏移量的,我们使用的都是低级的api
17、Spark的调度模式有哪俩种
FIFO
先进先出,谁先提交谁先执行,后面的任务需要等待前面的执行完毕才能继续执行,是spark的默认调度模式
FAIR
公平调度,在调度池为任务进行分组,不同的调度池的权重分配不同,任务是按照权重的占比来决定谁先进行执行的
18、真正想要扩大分区
repartition(扩大分区)
coalesce(合并分区)
repartition底层是调用的coalesce
19、公共RDD一定要实现持久化
无论对这个RDD做多少次计算,都是可以直接读取这个RDD的持久化的数据。持久化可以进行序列化的,序列化大大减少内存的占用空间
20、foreachRDD在哪里执行
在dirver端 因为driver端产生RDD 在excetor端运行程序
21、Spark on Yarn
Spark on Yarn 分为俩种运行模式,一种是Cluster一种是Client
Sparksql
22、sparkSQL的3中join
Shuffle hash join
分区的平均大小不超过100M,基表不能被广播,一侧的表要明显小于另外一侧,小的一侧将被广播
Sort merge join
两个大表
Broadcast join
只能广播很小的表 基表不能被广播 放在内存中,当表很小的时候用 (官方默认小表是25MB)
23、UpdateStateByKey的主要功能
有状态的进行转换
updatebykey需要的3个参数是什么:
Iterator[K] :需要聚合的key单词
Seq[v] : 当前批次产生的单词在每一个分区出现的次数
Option[s]: 初始值或者累计的中间值
24、reducebykeyAndWindow需要的3个参数是什么
窗口大小 , 滑动时长 , 批次处理
25、缓存和检查点的区别是什么
缓存在内存中,检查点(机制)将数据保存在hdfs中
26、检查点(机制)
将数据持久化,保证数据的完整性,数据丢失时能够数据恢复
7*24
sparkStreaming
1、如何理解streaming
做流式计算,吞吐量高。 准实时查询
工作原理:他会将接收的数据拆分成batch,每一秒数据封装成一个batch,然后吧每个batch交给spark的计算引擎处理,最后会产生一个数据结果流
2、
27、Cache之后能不能接其他算子
28、数据本地化是在哪个环节
29、RDD弹性表现在那个环节
30、常规的容错方式有哪几种
31、RDD有哪些缺陷
32、Spark程序的编写步骤
33、Spark有哪些聚合列的算子,我们应该避免哪些算子
34、如何从kafka中获取到数据
35、RDD创建的几种方式
36、Spark中的数据是被谁管理的
37、Spark如何处理不能被序列化的对象
38、Collect的功能是什么其底层是怎么实现的
39、Spark程序中,有什么会默认产生task,怎么修改task的执行个数
40、为什么要序列化
41、Spark的通信机制
42、sparkContext的理解
Kafka
1、kafka的设计特点
采用pull的方式
2、用途(解耦、广播,速度快)
监控指标、日志聚合、时间采集、提交日志
3、如何保证数据顺序消费
1)一个分区、一个消费者、一个生产者
2)Partition写入的顺序是有序的,只能保证一个消费者在一个分区中的顺序消费,不能保证topic的顺序消费
4、Kafka有两个线程(main线程、sender线程)
Main负责创建消息,分区器,序列化器,拦截器之后的数据缓存到RecordAccumulator,
sender是将RecordAccumulator的数据发送到kafka中
5、消费者组中的消费者个数如果超过了分区的个数,是否有消费者就会消费不到数据
不会,可以自定义分区分配策略,因为consumer可以将指向所有的partition
6、哪些情况下,会造成数据重复消费数据
消费完之后,没有提交offset
7、哪些情况下会造成数据漏消费
数据没有消费完,就提交了数据
8、Kafka的三种机制
0:producer发送过来的消息,服务器不会等待broker的ack,当leader宕机后,数据就会丢失
1:producer发送过来的消息,服务器会等待leader ack之后,但是当leader挂掉之后,leader也会丢失数据
-1:producer发送过来的消息,服务器会等待所有的副本ack之后,leader才会ack ,这样数据不会丢失
9、Zookeeper对于kafka的作用是什么
Zookeeper是高可用的分布式的应用协调服务,保存了kafka的offset信息
Kafka的leader检测,分布式服务,配置管理都在zookeeper中保存
10、kafka中常见的BUG
Kafka中的数据只能保存七天,随之而来的问题就是某个偏移量对应的数据被清除, 我们通过偏移量去查找数据而发生的报错(数据已经被Kafka给清除掉了),也就是说我们读取的偏移量小于Kafka中数据保存的最早的偏移量,说明数据已经被Kafka给干掉了
解决方式:
将拿到的偏移量和Kafka中保存的最小的偏移量进行对比,哪个大用哪个
11、为什么要使用Kafka
Kafka是个高可用的高并发的高吞吐量的程序,当生产者生产的数据过多,消费者无法处理,我们就需要一个消息中间件来作为缓冲,存储数据,这个消息中间件我们就使用的是Kafka
12、kafka中获取偏移量
通过foreachRDD获取当前批次的RDD的偏移量(rdd.aslnstanceOf [HasOffsetRanges].offsetRanges)
13、给kafka写数据的时候如何定义topic属于哪个分片
1)如果定义k,没有定义分区,就根据k的hash值hash出一个分区
2)如果没有定义k,分区 都没有定义,则使用轮循的方式
3)如果定义K,分区 就根据定义的k,分区
14、Broker的意义
一个broker代表kafka集群中的一个节点
15、怎么解决kafka数据丢失
高阶API开启WLAS预写机制
低阶API是手动维护偏移量,将offset保存在mysql中,采用副本机制
16、Kafka分区内的选举机制
Kafka在所有broker中选取一个controller,并在zk中注册一个监听,当controller出现问题时,立马进行切换,并注册新的监听。所有分区的leader都是由controller决定的,(controller负责增删topic和重新分区),当broker挂掉后也就是leader挂掉后,会选择一个幸存的partition作为leader。
17、Kafka如何实现广播
先将数据cache,然后再用广播变量 广播出去
18、为什么使用kafka前必须配置zookeeper
Zookeeper是为了防止Hmaster的单点故障,保证其他程序的高可用和数据一致性,防止集群因为hmaster宕机而导致崩溃,并且kafka的元数据也保存在zookeeper中
19、Kafka不是主从框架,但是kafka分区分为 leader 和 follower分区,主分区负责读写,follower分区负责同步数据
20、Kafka 的ack机制(数据可靠性保证)
0:不等待broker返回确认消息
1:等待topic中某个partition leader保存成功的状态反馈
-1:等待topic中某个partition 所有副本都保存成功的状态反馈
仅设置acks=-1也不能保证数据不丢失,当Isr列表中只有Leader时,同样有可能造成数据丢失。要保证数据不丢除了设置acks=-1, 还要保证ISR的大小大于等于2,具体参数设置:
request.required.acks:设置为-1 等待所有ISR列表中的Replica接收到消息后采算写成功;
min.insync.replicas: 设置为大于等于2,保证ISR中至少有两个Replica
注意:Producer要在吞吐率和数据可靠性之间做一个权衡
21、Kafka分布式情况下,如何保证消息的顺序
可以为他添加一个内存队列,通过hash,将相同的hash过的数据放在一个内存队列中,这样就能保证消息的顺序
生产者在向partition中写数据的时候,可以指定一个key,比如订单id,这个时候写入数据一定是有序的,消费者在从partition中读取数据的时候也是有序的,但是如果kafka开启多线程,那么就会导致数据不一致,这个时候就要用到内存队列,通过hash,将相同的hash过的数据保存在一个内存队列中,这样就能保证一个线程对应一个内存队列的数据在写入数据库的时候数据是有序的,从而开启多个线程对应多个内存队列
22、Kafka的组件
Broker,生产者,消费者,topic,消费者组,partition
23、如何设定Kafka的分区数量
broker数量*每台机器上可用的cpu核数
24、Kafka数据丢失如何处理
数据丢失我们要看它是在生产者端丢失还是消费者端丢失的
如果是在生产者端丢失的,那么我们要调整它的分区数,副本数,还有leader的副本感知数
如果是消费者端,那么说明数据在未处理完毕的时候就进行了偏移量的提交,所以我们就不使用手动提交偏移量,改为自动提交偏移量
25、Kafka重复消费的问题遇到过吗?如何解决的
使用的是kafka0.8直连方式,手动维护偏移量的,暂时没有遇到数据重复消费的问题
假如每条数据的处理时间超过60s,当处理了几百条数据之后,又开始从第一条数据开始计算
原因:kafka消费者有两个参数配置,一个是
Max.poll.interval.ms
意思是两次poll操作的时间间隔最长时间 默认值是3000s
另一个是max.poll.records
意思是每次poll操作的消息数量,默认是50
当我们每条数据的处理时间大于60s的时候,如果两次poll的时间一旦超过了最长时间间隔,kafka就会触发reblance操作,就会导致客户端连接失败,无法提交offset,导致重复消费
如果每次poll操作的消息数量是50,每条数据的处理时间超过了60s,就会超过poll的最大时间间隔(3000s),那么就会导致重复消费数据
处理方法就是:调大两个poll之间的讲个时间,调小每个poll的操作消息数量
26、从kafka读取数据的时候一定会遇到一个峰值,如何解决
1)我们开启了sparkstreaming的背压机制
2)foreachRDD中加入了一个线程池,并行的去处理数据
27、什么是背压机制
背压机制,通过动态收集集群中的一些数据,来自动适配集群的数据处理能力
Spark1.5之后,默认是关闭的
在原有架构上,增加了RateController组件,可以通过监控集群中的一些事件,自动估算出当前数据处理能力的最大速率,这个速率主要用于更新每秒能够处理数据的最大条数,RateController可以存下计算好的最大速率,然后将速率推送到接收器中,接收器就知道接受多少数据合适
30.ALS算法原理?
答:对于user-product-rating数据,als会建立一个稀疏的评分矩阵,其目的就是通过一定的规则填满这个稀疏矩阵。
als会对稀疏矩阵进行分解,分为用户-特征值,产品-特征值,一个用户对一个产品的评分可以由这两个矩阵相乘得到。
通过固定一个未知的特征值,计算另外一个特征值,然后交替反复进行最小二乘法,直至差平方和最小,即可得想要的矩阵。
31.kmeans算法原理?
随机初始化中心点范围,计算各个类别的平均值得到新的中心点。
重新计算各个点到中心值的距离划分,再次计算平均值得到新的中心点,直至各个类别数据平均值无变化。
32.canopy算法原理?
根据两个阈值来划分数据,以随机的一个数据点作为canopy中心。
计算其他数据点到其的距离,划入t1、t2中,划入t2的从数据集中删除,划入t1的其他数据点继续计算,直至数据集中无数据。