这里使用的环境和上一篇的一样。上一篇的Mapreduce是在本地执行任务,在http://192.168.1.2:8088/cluster 在如下图中是看不到job的提交,本篇将指导你怎么在windows中提交job到远程linux上面。意思在一般开发的时候,我们可以在window上做开发,在linux上执行任务。
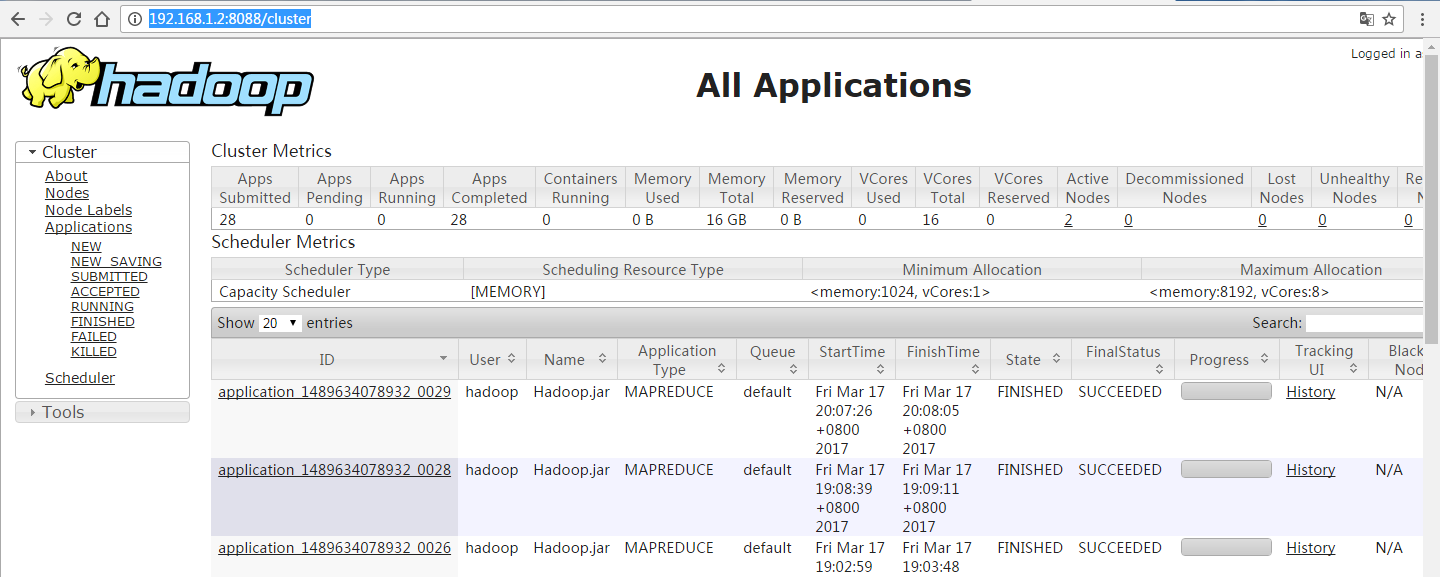
1、在这个开发中会遇到以下错误:
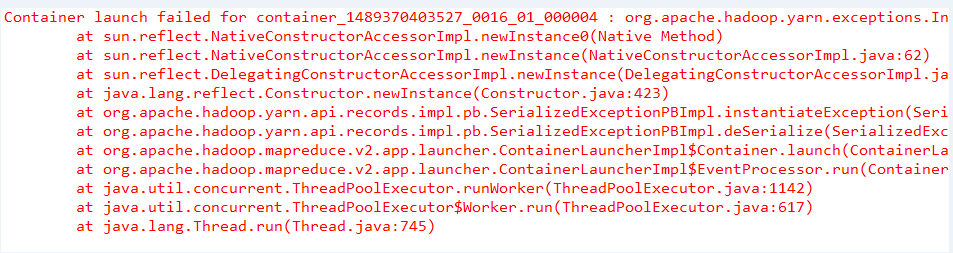
需要修改YARNRunner类,重写YARNRunner类。在这里使用所有都是2.7.3jar包,由于本地系统是windows ,发布到的是linux 做以下改变:
把方法代码放到YARNRunner末尾
private void replaceEnvironment(Map<String, String> environment) { String tmpClassPath = environment.get("CLASSPATH"); tmpClassPath=tmpClassPath.replaceAll(";", ":"); tmpClassPath=tmpClassPath.replaceAll("%PWD%", "\$PWD"); tmpClassPath=tmpClassPath.replaceAll("%HADOOP_MAPRED_HOME%", "\$HADOOP_MAPRED_HOME"); tmpClassPath= tmpClassPath.replaceAll("\\", "/" ); environment.put("CLASSPATH",tmpClassPath); }
2、在376行左右,把代码
vargs.add(MRApps.crossPlatformifyMREnv(jobConf, Environment.JAVA_HOME)
+ "/bin/java");
改成
vargs.add("$JAVA_HOME/bin/java");
3、
在以上代码的上一行添加replaceEnvironment(environment); //后来添加
// Setup ContainerLaunchContext for AM container
ContainerLaunchContext amContainer =
ContainerLaunchContext.newInstance(localResources, environment,
vargsFinal, null, securityTokens, acls);
4、接下来是拷贝hadoop的配置文件到resource目录下
core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/hadoop/tmp/</value> <description> Abase for other temporary directories</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://namenode:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.nameservices</name> <value>namenode</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>namenode:50090</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/hadoop/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
maperd-site.xml
<configuration> <property> <name>mapreduce.application.classpath</name> <value> /usr/hadoop/opt/hadoop/etc/hadoop, /usr/hadoop/opt/hadoop/share/hadoop/common/*, /usr/hadoop/opt/hadoop/share/hadoop/common/lib/*, /usr/hadoop/opt/hadoop/share/hadoop/hdfs/*, /usr/hadoop/opt/hadoop/share/hadoop/hdfs/lib/*, /usr/hadoop/opt/hadoop/share/hadoop/mapreduce/*, /usr/hadoop/opt/hadoop/share/hadoop/mapreduce/lib/*, /usr/hadoop/opt/hadoop/share/hadoop/yarn/*, /usr/hadoop/opt/hadoop/share/hadoop/yarn/lib/* </value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>namenode:50030</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>namenode:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>namenode:19888</value> </property> <property> <!--see job--> <name>mapred.job.tracker</name> <value>namenode:9001</value> </property> </configuration>
yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> --> <property> <name>yarn.resourcemanager.address</name> <value>namenode:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>namenode:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>namenode:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>namenode:8033</value> </property> <property> <name>yarn.resourcemanager.web.address</name> <value>namenode:8088</value> </property> <property> <name>yarn.application.classpath</name> <value> /usr/hadoop/opt/hadoop/etc/hadoop, /usr/hadoop/opt/hadoop/share/hadoop/common/*, /usr/hadoop/opt/hadoop/share/hadoop/common/lib/*, /usr/hadoop/opt/hadoop/share/hadoop/hdfs/*, /usr/hadoop/opt/hadoop/share/hadoop/hdfs/lib/*, /usr/hadoop/opt/hadoop/share/hadoop/mapreduce/*, /usr/hadoop/opt/hadoop/share/hadoop/mapreduce/lib/*, /usr/hadoop/opt/hadoop/share/hadoop/yarn/*, /usr/hadoop/opt/hadoop/share/hadoop/yarn/lib/* </value> </property> </configuration>
上述xml文件引入都lib 都是linux上面的jar目录,因为最终需要打包成jar的形式在linux上面运行
pom.xml 相对上一篇文章中多引入了几个包,对比看一下就知道了
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>HadoopJar</groupId> <artifactId>Hadoop</artifactId> <version>0.0.1-SNAPSHOT</version> <name>Hadoop</name> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.7.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.7.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-jobclient --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.7.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-app --> <!-- <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-app</artifactId> <version>2.7.3</version> </dependency> --> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> </dependencies> <build> <finalName>Hadoop</finalName> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-resources-plugin</artifactId> <configuration> <encoding>UTF-8</encoding> </configuration> </plugin> </plugins> </build> </project>
接下来java类和上一篇的差不多,这里需要多添加一行代码到Wcount.java 中
conf.set("mapred.jar", "D:\workspace\Hadoop\target\Hadoop.jar");
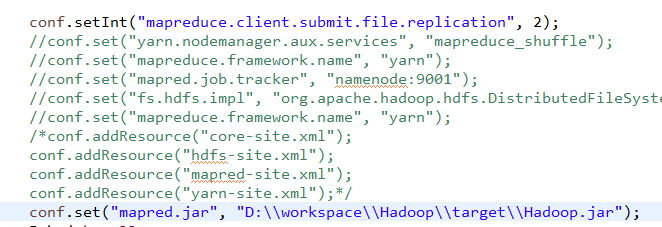
这个包Hadoop.jar是由maven打包而来,注意这里在打包的时候先把这一行注释掉再打包,如果不添加这一行就会报如下错误:

如有不理解地方欢迎联系QQ1565189664