先问一个问题,为什么需要有一个统一的基类:Object?
甚至,我们在编程语言中也常常见到这种模式,比如Java中的object、C#的object,甚至一些纯对象的脚本语言(Ruby里连数字123都是对象)。刚接触UE的人,看到UE里的Object,可能觉得这没什么,好像就自然而然应该有应该是这样,但是做过游戏引擎的人就知道,这里面蕴含了很多设计思想和权衡。
大部分的游戏引擎底层都是C++,而C++作为一个下接操作系统硬件底层,上接用户逻辑的编程语言,为了适应各种环境,不为你不需要的东西付代价,C++是并没有提供原生GC的。STL库的那些智能指针更多只是在C++的语言层面上再提供一些小辅助。在最开始设计游戏引擎的时候,你不光要考虑该引擎所面对的用户群体和针对的游戏重点,更要开始考虑你所能利用到的都有什么内存管理方式。简单说一下其他游戏引擎在这方便的情况:
那么引入一个Object的根基类设计到底有什么深远的影响,我们又付出了什么代价?
得到:
- 万物可追踪。有了一个统一基类Object,我们就可以根据一个object类型指针追踪到所有的派生对象。如果愿意,我们都可以把当前的所有对象都遍历出来。按照纯面向对象的思想,万物皆是对象,所以有一个基类Object会大大方便管理。如果再加上一些机制,我们甚至可以把系统中的所有对象的引用图给展示出来。
- 通用的属性和接口。得益于继承机制,我们可以在object里加上我们想应用于所有对象的属性和接口,包括但不限于:Equals、Clone、GetHashCode、ToString、GetName、GetMetaData等等。代码只要写一遍,所有的对象就都可以应用上了。
- 统一的内存分配释放。实际上Cocos2dx里的CCObject的目的就是如此,可惜就是实现得不够好而已。用引用计数方案的话,你可以在Object上添加Retain+1/Release-1的接口;用GC的方案,你也有了一个统一Object可以引用,所以这也是为何几乎所有支持GC的语言都会设计出来一个Object基类的原因了。
- 统一的序列化模型。如果想要让系统里的各种类型对象支持序列化,那么你要嘛针对各种类型分别写一套(如protobuf就是用程序生成了序列化代码),要嘛就得利用模板和宏各种标记识别(我自己Medusa引擎里实现的序列化模块Siren就是如此实现的),而如果有了一个Object基类,最差的我们就可以利用上继承机制把统一的序列化代码放到Object里面去。而如果再加上设计良好的反射机制,实现序列化就更加的方便了。
- 统计功能。比如说我们想统计看看整个程序跑下来,哪种对象分配了最多次,哪种对象分配的时间最长,哪种对象存活的时间最长。等等其他很便利的功能,在有了可追踪和统一接口的基础上,我们也能方便的实现出来。
- 调试的便利。比如对于一块泄漏了的内存数据,如果是多类型对象,你可能压根没法知道它是哪个对象。但是如果你知道它是Object基类下的一个子类对象,你可以把地址转换为一个Object指针,然后就可以一目了然的查看对象属性了。
- 为反射提供便利。如果没有一个统一Object,你就很难为各种对象实现GetType接口,否则你就得在每个子类里都定义实现一遍,用宏也只是稍微缓解治标不治本。
- UI编辑的便利。和编辑器集成的时候,为了让UI的属性面板控件能编辑各种对象。不光需要反射功能的支持,还需要引用一个统一Object指针。否则想象一下如果用一个void* Object,你还得额外添加一个ObjectType枚举用来转换成正确类型的C++对象,而且只能支持特定类型的C++类型对象。
代价:
- 臃肿的Object。这算是继承的祖传老毛病了,我们越想为所有对象提供额外功能,我们就越会在Object里堆积大量的函数接口和成员属性。久而久之,这个Object身上就挂满了各种代码,可理解性就大大降低。Java和C#里的Object比较简单,看起来只有个位数的接口,那是因为有C++在JVM和CLR的背后默默的干着那些脏活累活,没显示出来给你看而已。而UE在原生的的C++基础上开始搭建这么一套系统,就是如今这么一个重量级的UObject了,大几十个接口,很少有人能全部掌握。
- 不必要的内存负担。有时候有些属性并不是所有对象都用的到,但是因为不确定,为了所有对象在需要的时候就可以有,你还是不得不放在Object里面。比如说一个最简单的void* UserData,看起来为所有对象附加一个void*数据也挺合理的,用的时候设置取出就好了。但是其实有些类型对象可能一辈子都用不到,用不到的属性,却还占用着内存,就是浪费。所以在一个统一的Object里加数据,就得非常的克制,不然所有的对象都不得不得多一份占用。
- 多重继承的限制。比如C多重继承于A和B,以前A和B都不是Object的时候还好,虽然大家对C++里的多重继承不太推荐使用,但是基本上也是不会有大的使用问题的。然后现在A和B都继承于Object了,现在让C想多重继承于A和B,就得面临一个尴尬的局面,变成菱形继承了!而甭管用不用得上全部用虚继承显然也是不靠谱的。所以一般有object基类的编程语言,都是直接限制多重继承,改为多重实现接口,避免了数据被继承多份的问题。
- 类型系统的割裂。除非是像java和C#那样,对用户隐藏整个背后系统,否则用户在面对原生C++类型和Object类型时,就不得不去思考划分对象类型。两套系统在交叉引用、互相加载释放、消息通信、内存分配时采用的机制和规则也是大不一样的。哪些对象应该继承于Object,哪些不用;哪些可以GC,哪些只能用智能指针管理;C++对象里new了Object对象该怎么管理,Object对象里new了C++对象什么时候释放?这些都是强加给用户思考的问题。
著名的沃斯基·索德曾经说过,设计就是权衡的艺术。那些得到的UE已经想要攥在手里了,而那些代价我们也得想办法去尽量降低和规避:
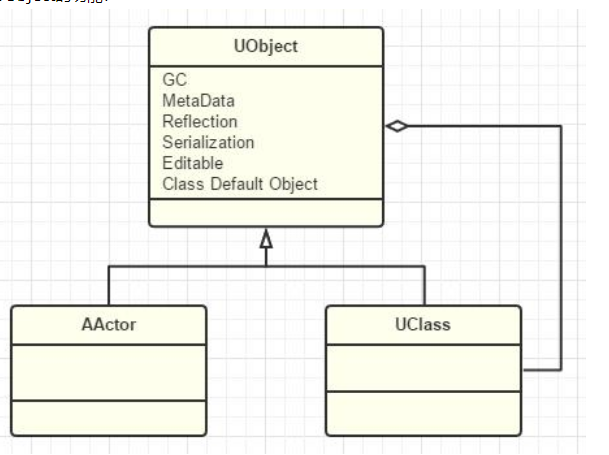
- 针对太过复杂的Object基类,虽然我常常夸UE的设计优雅卓越,但是我这里要黑一下UE,感觉UE的Object基类已经有点破罐子破摔了,能非常明显的感觉到了进化留下的痕迹,一个UObject你给我分了三层继承:(UObjectBase->UObjectBaseUtility->UObject),关键是头两层你还都没有子类。而Object相关的Flags常常竟然把32位都给占完了也是牛。念在UE提供了那么多的UObject功能模块实现,类声明里大几十个方法我们也只好忍了吧。这一块太过底层,估计也不敢大刀阔斧的整改,只能期待UE5再说了。
- sizeof(UObject)==56。56个字节相对来说应该还是可以接受,关掉Stat的话还能再少一个指针大小。当然这里并没有考虑到外围Class系统的内存占用,但是光光一个对象基础的数据占用56字节起步的话,我觉得已经非常优秀了。10000个对象是546K,1百万个对象是53M。一方面游戏里的对象其实数量没有那么多,对于百万粒子那种也可以用原生的C++对象优化,另一方面现在各个平台内存也越来越宽裕了,所以这个问题已经解决得在可接受范围内了。
- 规避多重继承,UE在BP里提供的也是多重继承Interface的方案。在C++层面上,我们只能尽量规避不要多重继承多个UObject子类,实在想要实现功能复用,也可以采用组合的组件模式,或者把共同逻辑写在C++的类型上,比如UE中众多的F开头的类就是如此的功能类。总之这个问题,好在我们可以用方式规避掉。
- 只能多学习了。没办法,现实就是不完美的。越是设计精巧的系统就越是难以理解。不过一方面UE提倡在BP里实现游戏逻辑,C++充当BP的VM,就可以完全对用户隐藏掉复杂性。另一方面,UE在UObject上也提供了大量的辅助设计,如UCLASS等各种宏的便利,NewObject方便接口,UHT的自动分析生成代码,尽量避免用户直接涉及到UObject的内部细节。所以单从一个使用者的角度来说,如今的状态已经挺友好的了,Object工作的挺好,几乎不需要去操心或者帮它补漏。至于想理解的更深层次的话,就只能靠开发者们更用心的学习了。
权衡的结果大家也都知道了,UE下定雄心选择了开始搭建Object,提供了那么多我们日常使用的功能。我的Medusa引擎也是非常艳羡UE那么多便利的功能,但是让我从头开始去再去搭建一套,限于精力有限,我是不敢去做的。光一个GC就得有大量的算法权衡,多线程处理的各种细节和各种优化,更何况再融合了反射、序列化、CDO、统计,想实现得既优雅又性能优越就真的是一件非常不容易的事,代码写完之后还得需要大量的测试和修复才能慢慢稳定下来能用。信任感的建立是很难的,一旦出现对象被释放掉了或者没有释放,你第一时间怀疑的应该是你的使用有问题,而如果UE给你的印象是怀疑UE的Object实现内部有bug,那你就会逐渐的倾向于弃用UE的那一套,开始撸起袖子自己管理C++对象了。
总结
本文作为专题的开篇,唠了些书写背景的闲话,也闲聊了一下其他游戏引擎是怎么看待游戏内对象管理这回事的。每款游戏引擎都有自己的产生背景和侧重点,再加上设计的理念也不一样,所以就会产生各种各样的架构。接着探讨了设计一个Object系统有哪些好处和缺点,我不知道UE最初的UObject设计是从何而来的,但是如果没有UObject,没有了富饶的土壤,想要有繁茂的森林就比较困难了。各引擎的开发团队竞赛的时候,大家其实水平都差不了多少,同样想支持一个最新功能的时候,我利用上了统一的Object机制开发用了一周上线;你因为少了一些代码上的便利,还得自己手动管理内存,写序列化,再撸编辑器支持,代码写了两周,修复Bug用了2周,交付用户使用的时候,代码的接口因为不能反射也不是那么易用,慢慢的竞争优势就弱了。没那么方便调试统计,开发者修复bug起来就费劲,埋的Bug多了,用户觉得你越来越不稳定,引擎的生命力就是这么一步步一点点枯萎掉的。所以不要觉得引擎只要堆积功能就行了,一开始有个好的结构是重中之重。