迁移学习算法之TrAdaBoost
from: https://blog.csdn.net/Augster/article/details/53039489
TradaBoost算法由来已久,具体算法可以参考作者的原始文章,Boosting For Transfer Learning。
1.问题定义
传统的机器学习的模型都是建立在训练数据和测试数据服从相同的数据分布的基础上。典型的比如有监督学习,我们可以在训练数据上面训练得到一个分类器,用于测试数据。但是在许多的情况下,这种同分布的假设并不满足,有时候我们的训练数据会过期,而重新去标注新的数据又是十分昂贵的。这个时候如果丢弃训练数据又是十分可惜的,所以我们就想利用这些不同分布的训练数据,训练出一个分类器,在我们的测试数据上可以取得不错的分类效果。
定义问题模型如下:设为源样例空间,
为辅助样例空间。源样例空间也就是我们的目标空间,就是想要去分类的样例空间。设Y={0,1}为类别空间,这里简化了多分类问题为二分类问题讨论,这样我们的训练数据也就是
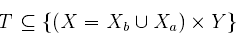
测试数据:
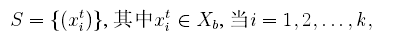
其中测试数据是未标注的,我们可以将训练数据划分为两个数据集:
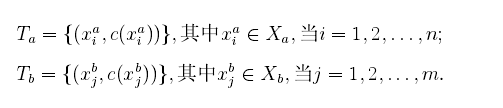
其中代表样本数据x的真实所属的类别,
和
的区别在于
和测试数据S是同分布的,
和测试数据是不同分布的,现在的任务就是给定很少的源数据
和大量的辅助数据
训练出一个分类器在测试数据S上的分类误差最小。这里假设利用已有的数据
不足以训练出一个泛化能力很强的分类器。
2.TrAdaBoost算法
我们利用AdaBoost算法的思想原理来解决这个问题,起初给训练数据T中的每一个样例都赋予一个权重,当一个源域中的样本被错误的分类之后,我们认为这个样本是很难分类的,于是乎可以加大这个样本的权重,这样在下一次的训练中这个样本所占的比重就更大了,这一点和基本的AdaBoost算法的思想是一样的。如果辅助数据集中的一个样本被错误的分类了,我们认为这个样本对于目标数据是很不同的,我们就降低这个数据在样本中所占的权重,降低这个样本在分类器中所占的比重,下面给出TradaBoost算法的具体流程:


可以看到,在每一轮的迭代中,如果一个辅助训练数据被误分类,那么这个数据可能和源训练数据是矛盾的,那么我们就可以降低这个数据的权重。具体来说,就是给数据乘上一个,其中
的值在0到1之间,所以在下一轮的迭代中,被误分类的样本就会比上一轮少影响分类模型一些,在若干次以后,辅助数据中符合源数据的那些数据会拥有更高的权重,而那些不符合源数据的权重会降低。极端的一个情况就是,辅助数据被全部忽略,训练数据就是源数据Tb,这样这时候的算法就成了AdaBoost算法了。在计算错误率的时候,当计算得到的错误率大于0.5的话,需要将其重置为0.5。
可以看到,TrAdaBoost算法在源数据和辅助数据具有很多的相似性的时候可以取得很好效果,但是算法也有不足,当开始的时候辅助数据中的样本如果噪声比较多,迭代次数控制的不好,这样都会加大训练分类器的难度。