信息安全常被描述成一场军备竞赛,白帽与黑帽,渗透测试者与黑客,善与恶,本文将聚焦这场永无止境决斗中的一个小点。
HTML5 & JS 应用中充满着对输入进行验证/注入的问题,需要开发人员始终保持警惕。但同时还存在着另一个问题,就是应用中程序专用代码的易访问性。为了防止盗版或者至少使盗版更加困难,常会使用混淆工具对 JS 代码进行混淆。作为对立面,反混淆工具也可以将混淆过的 JS 代码进行还原。我曾经接触过双方的一些工具,下面是我的一些研究成果。
首先,下面这是我们的示例代码(取自Google Closure Compiler的 Wiki 页面)。一个完整的应用程序中代码会更加复杂,但这里足以用于实验了:
function displayNoteTitle(note) {
alert(note['title']);
}
var flowerNote = {};
flowerNote['title'] = "Flowers";
displayNoteTitle(flowerNote);
接下来,让我们来列举下要进行实验的混淆和反混淆工具,本文中会实验 4 个混淆工具和 2 个反混淆工具。
混淆工具:
反混淆工具:
以上除了 JScrambler 是商业软件需要付费使用外,其余全部为免费软件。
缩小和混淆
下面首先让我们看看混淆工具的混淆效果如何,随后在看看反混淆工具的表现又如何。
YUI Compressor
function displayNoteTitle(a){alert(a.title)}var flowerNote={};flowerNote.title="Flowers";displayNoteTitle(flowerNote);
Google Closure Compiler
这个工具有优化和混淆两种类型:
简单优化:
function displayNoteTitle(a){alert(a.title)}var flowerNote={title:"Flowers"};displayNoteTitle(flowerNote);
深度优化:
alert("Flowers");
UglifyJS
同前一个工具一样,UglifyJS 也有两种层次的混淆:
默认:
function displayNoteTitle(e){alert(e.title)}var flowerNote={};flowerNote.title="Flowers",displayNoteTitle(flowerNote);
高级:
function t(t){alert(t.title)}var e={};e.title="Flowers",t(e);
JScrambler
/* Obfuscate your JavaScript at https://jscrambler.com */var g5b={'S':"A",'A':function(b){flowerNote['title']=b;},'X':"V",'o':(function(E){return (function(s,p){return (function(G){return {K:G};})(function(m){var c,R=0;for(var U=s;R<m["length"];R++){var O=p(m,R);c=R===0?O:c^O;}return c?U:!U;});})((function(h,n,a,M){var y=28;return h(E,y)-M(n,a)>y;})(parseInt,Date,(function(n){return (''+n)["substring"](1,(n+'')["length"]-1);})('_getTime2'),function(n,a){return new n()[a]();}),function(m,R){var d=parseInt(m["charAt"](R),16)["toString"](2);return d["charAt"](d["length"]-1);});})('3lrno3f7c'),'e':'title','V':function(b){x=b;},'Q':"Flowers",};function displayNoteTitle(b){alert(b[g5b.e]);}var flowerNote=g5b.o.K("3d3")?{}:"Flowers";g5b[g5b.S](g5b.Q);displayNoteTitle(flowerNote);g5b[g5b.X](g5b.D);
那么,上面的代码是什么意思呢?显而易见,YUI Compressor,Google closure compiler 的简单优化模式和 UglifyJS 的默认模式都使用了相同的方法对 JS 代码进行缩小和混淆。缩小意味着压缩代码、减小应用程序的体积或者降低浏览器的加载时间。所有的这一切,在将变量名改为一个无意义的字符后,代码会变得难以阅读。
UglifyJS 的高级模式会进一步混淆函数名和全局变量的名称。Google closure compiler 的深度优化模式同时还会积极的删除无用代码,它追求最简。
而 JScrambler 则是另一种方式,它专注于对代码进行混淆,不仅不对代码进行缩小,反而通过增加代码数量使代码变的难以阅读。
美化和反混淆
jsbeautifier.org
正如其名字一样,这个在线工具试图将缩小后的代码变的更加具有可读性,但似乎它不会对代码进行进一步的反混淆。
YUI Compressor -> jsbeautified
function displayNoteTitle(e) {
alert(e.title)
}
var flowerNote = {};
flowerNote.title = "Flowers", displayNoteTitle(flowerNote);
UglifyJS Toplevel -> jsbeautified:
function t(t) {
alert(t.title)
}
var e = {};
e.title = "Flowers", t(e);
JSDetox
对 UglifyJS 高级模式的代码使用 JSDetox 似乎并不比 jsbeautifier.org 好多少,这点可以理解的,毕竟对变量/函数名进行转换这是不可逆的过程。
高级的反混淆和恶意代码检测
一般的代码混淆常用于知识产权保护,而高级的代码混淆则常会被用于隐藏 WEB 应用中的恶意代码。对恶意代码进行混淆是为了躲避杀毒软件的检测,这些代码在被混淆扩充后会难以被识别为恶意软件。Metasploit 的 Javascript 混淆器常被用于开发恶意代码,所以我们下面使用 Metasploit 的混淆器对我们的代码进行混淆(参考文档)。JSDetox 声称其具有进行反混淆 JS 代码的能力,所以下面让我们来尝试下对 Metasploit 和 JScrambler 混淆后的代码进行高级的反混淆。
Metasploit Javascript 混淆器
function L(t){window[String.fromCharCode(0141,0x6c,101,0162,0164)](t[String.fromCharCode(0164,105,0164,108,0145)]);}var C={};C[(function () { var K='le',Z='tit'; return Z+K })()]=(function () { var m="s",D="r",J="F",e="lowe"; return J+e+D+m })();L(C);
使用 JSDetox 进行反混淆
JScrambler -> JSDetoxed
var g5b = {
'S': "A",
'A': function(b) {
flowerNote['title'] = b;
},
'X': "V",
'o': (function(E) {
return (function(s, p) {
return (function(G) {
return {
K: G
};
})(function(m) {
var c, R = 0;
for(var U = s; R < m["length"]; R++) {
var O = p(m, R);
c = R === 0 ? O : c ^ O;
}
return c ? U : !U;
});
})((function(h, n, a, M) {
return h(E, 28) - M(n, a) > 28;
})(parseInt, Date, (function(n) {
return ('' + n)["substring"](1, (n + '')["length"] - 1);
})('_getTime2'), function(n, a) {
return new n()[a]();
}), function(m, R) {
var d = parseInt(m["charAt"](R), 16)["toString"](2);
return d["charAt"](d["length"] - 1);
});
})('3lrno3f7c'),
'e': 'title',
'V': function(b) {
x = b;
},
'Q': "Flowers"
};
function displayNoteTitle(b){
alert(b[g5b.e]);
}
var flowerNote = g5b.o.K("3d3") ? { } : "Flowers";
g5b[g5b.S](g5b.Q);
displayNoteTitle(flowerNote);
g5b[g5b.X](g5b.D);
Metasploit -> JSDetoxed
function L(t){
window["alert"](t["title"]);
}
var C = { };
C["title"] = "Flowers";
L(C);
尽管经过 Metasploit 混淆后的 JS 代码依旧可以躲避杀毒软件,但看起来也会轻易被 JSDetox 进行反混淆。有趣的是,看起来 JSDetox 无法反混淆 JScrambled 的代码。我不确定为什么 JSDetox 可以反混淆出 metasploit 的代码却不能反混淆出 JScrambler 的,不过我猜测是 JSDetox 专门针对 metasploit 的混淆方法做过专门的支持。另一方面,JScrambler 完全是一个黑盒,但这并不意味着 JScrambled 混淆后的 Javascript 代码不能被反混淆,也许有另一个工具专门用于或包含反混淆 JScrambled 代码功能。
*原文:damilarefagbemi,FB小编xiaix编译,转自须注明来自FreeBuf黑客与极客(FreeBuf.COM)
Javascript混淆与解混淆的那些事儿
像软件加密与解密一样,javascript的混淆与解混淆同属于同一个范畴。道高一尺,魔高一丈。没有永恒的黑,也没有永恒的白。一切都是资本市场驱动行为,现在都流行你能为人解决什么问题,这个概念。那么市场究竟能容纳多少个能解决这种问题的利益者。JS没有秘密。
其实本人不赞成javascript进行hash混淆处理,一拖慢运行时速度,二体积大。JS代码前端可获取,天生赋予“开源”属性,都可以在chrome devTools下查看。JS非压缩性混淆完全违法前端优化准则。
目前网络上可以搜索的JS混淆工具不外乎以下几种:
eval混淆,也是最早JS出现的混淆加密,据说第一天就被破解,修改一下代码,alert一下就可以破解了。这种方法从出生的那天就失去了意义。其实JS加密(混淆)是相对于可读性而言的,其实真正有意义的就是压缩型混淆uglify这一类,即可减少体重,也可减少可读性。
但是,也不能排除部分商业源代码使用hash类型混淆源代码,比如 miniui 使用的JSA加密, fundebug使用的javascript-obfuscator。
下面通过代码来说明 JSA加密 和 javascript-obfuscator 的区别:
要混淆的代码:
function logG(message) {
console.log('x1b[32m%sx1b[0m', message);
}
function logR(message) {
console.log('x1b[41m%sx1b[0m', message);
}
logG('logR');
logR('logG');
通过JSA加密混淆后生成的代码
function o00($){console.log("x1b[32m%sx1b[0m",$)}function o01($){console.log("x1b[41m%sx1b[0m",$)}o00("logR");o01("logG")
然后再beautifier一下:
function o00($) {
console.log("x1b[32m%sx1b[0m", $)
}
function o01($) {
console.log("x1b[41m%sx1b[0m", $)
}
o00("logR");
o01("logG")
可以发现,其实没有做什么什么修改,只是做了一些变量替换。想还原也比较简单的。这里就不拿它来做代表,也没有什么人用。
通过javascript-obfuscator混淆后生成的代码
var _0xd6ac=['[41m%s[0m','logG','log'];(function(_0x203a66,_0x6dd4f4){var _0x3c5c81=function(_0x4f427c){while(--_0x4f427c){_0x203a66['push'](_0x203a66['shift']());}};_0x3c5c81(++_0x6dd4f4);}(_0xd6ac,0x6e));var _0x5b26=function(_0x2d8f05,_0x4b81bb){_0x2d8f05=_0x2d8f05-0x0;var _0x4d74cb=_0xd6ac[_0x2d8f05];return _0x4d74cb;};function logG(_0x4f1daa){console[_0x5b26('0x0')]('[32m%s[0m',_0x4f1daa);}function logR(_0x38b325){console[_0x5b26('0x0')](_0x5b26('0x1'),_0x38b325);}logG('logR');logR(_0x5b26('0x2'));
再beautifier一下:
var _0xd6ac = ['[41m%s[0m', 'logG', 'log'];
(function(_0x203a66, _0x6dd4f4) {
var _0x3c5c81 = function(_0x4f427c) {
while (--_0x4f427c) {
_0x203a66['push'](_0x203a66['shift']());
}
};
_0x3c5c81(++_0x6dd4f4);
}(_0xd6ac, 0x6e));
var _0x5b26 = function(_0x2d8f05, _0x4b81bb) {
_0x2d8f05 = _0x2d8f05 - 0x0;
var _0x4d74cb = _0xd6ac[_0x2d8f05];
return _0x4d74cb;
};
function logG(_0x4f1daa) {
console[_0x5b26('0x0')]('[32m%s[0m', _0x4f1daa);
}
function logR(_0x38b325) {
console[_0x5b26('0x0')](_0x5b26('0x1'), _0x38b325);
}
logG('logR');
logR(_0x5b26('0x2'));这个复杂得多,但是分析一下你会发现,其实多了一个字典,所有方法变量,都有可能存在字典中,调用时先调用字典还原方法名变量再执行。
其实入口都是变量的规则。
字典函数:
var _0xd6ac = ['[41m%s[0m', 'logG', 'log'];
(function(_0x203a66, _0x6dd4f4) {
var _0x3c5c81 = function(_0x4f427c) {
while (--_0x4f427c) {
_0x203a66['push'](_0x203a66['shift']());
}
};
_0x3c5c81(++_0x6dd4f4);
}(_0xd6ac, 0x6e));
var _0x5b26 = function(_0x2d8f05, _0x4b81bb) {
_0x2d8f05 = _0x2d8f05 - 0x0;
var _0x4d74cb = _0xd6ac[_0x2d8f05];
return _0x4d74cb;
};
通过以上发现,我们可以把JS混淆归结为三类,分别是 eval类型,hash类型,压缩类型。而压缩类型,是目前前端性能优化的常用工具,以uglify为代表。
常用的前端压缩优化工具:
JavaScript:
CSS:
HTML:
从工具流(workflow) 来看,不论是 webpack 还是 gulp ,目前javascript最流行工具还是uglify。
相应的解混淆工具:
- eval对应的解混淆工具, 随便百度都可以搜索到,如jspacker
- JSA对应的解混淆工具unjsa
- javascript-obfuscator对应的解混淆工具crack.js
- 压缩类型uglify对应的工具UnuglifyJS,在线版jsnice
解混淆策略其实是依据生成代码规律编写,不外乎观察特征分析,再观察特征分析,不断调整。都是手办眼见功夫。
都没有什么难度可言,有的就是耐性。比如javascript-obfuscator对应的解混淆工具可以
分解为N因子问题:
如何查询function的作用域?
预执行变量替换可能存在类型?
...
如:
var _0xd6ac = ['[41m%s[0m', 'logG', 'log'];
(function(_0x203a66, _0x6dd4f4) {
var _0x3c5c81 = function(_0x4f427c) {
while (--_0x4f427c) {
_0x203a66['push'](_0x203a66['shift']());
}
};
_0x3c5c81(++_0x6dd4f4);
}(_0xd6ac, 0x6e));
var _0x5b26 = function(_0x2d8f05, _0x4b81bb) {
_0x2d8f05 = _0x2d8f05 - 0x0;
var _0x4d74cb = _0xd6ac[_0x2d8f05];
return _0x4d74cb;
};
function logG(_0x4f1daa) {
console[_0x5b26('0x0')]('[32m%s[0m', _0x4f1daa);
}
function logR(_0x38b325) {
console[_0x5b26('0x0')](_0x5b26('0x1'), _0x38b325);
}
logG('logR');
logR(_0x5b26('0x2'));要还原成
function logG(message) {
console.log('x1b[32m%sx1b[0m', message);
}
function logR(message) {
console.log('x1b[41m%sx1b[0m', message);
}
logG('logR');
logR('logG');
第一步你总得知道字典函数,然后执行字典函数 _0x5b26('0x0') 还原成 log.
那么就好办了,写代码的事。
如 https://github.com/jscck/crack.js/blob/master/crack.js
还原后,如何重构代码,那么你还得知道代码生成之前是通过什么工具打包的webpack? 还是?
如webpack 的各种封装头和尾
https://webpack.js.org/config...
(function webpackUniversalModuleDefinition(root, factory) {
if(typeof exports === 'object' && typeof module === 'object')
module.exports = factory();
else if(typeof define === 'function' && define.amd)
define([], factory);
else if(typeof exports === 'object')
exports['MyLibrary'] = factory();
else
root['MyLibrary'] = factory();
})(typeof self !== 'undefined' ? self : this, function() {
return _entry_return_;
});假如再深入一点,可能会涉及到JS语法解释器, AST抽象语法树
目前涉及到 JS语法解释器, AST抽象语法树的功能如下:
或者可以阅读《编程语言实现模式》,涉及到 antlr4。
当然也可以通过esprima等工具来做解混淆,只是工作量大一点,值不值的问题。
对于未来,JS商业源码加密的方向可能webassembly,先在服务端编译成wasm,源码就能真正的闭源。
有人的地方就有路,有混淆的地方就有解混淆,目前机器学习编程响应的解混淆工具也做的相当出色,比如
Machine Learning for Programming 产品
nice2predict,jsnice ...
查看 https://www.sri.inf.ethz.ch/r...
拓展参考
AST抽象语法树
为什么额外说一下AST抽象语法树,因为你可以 input-> ast -> output Anything。
比如你jsx转换小程序模版语法,这样你就可以用react语法来写小程序,如Taro。
mpvue, wepy, postcss …… 这些都是通过AST进行构建转换的工具,es6 -> es5, babel 都是使用AST。
AST抽象语法树大致流程:
Input 生成 AST tree
然后通过AST类型断言进行相应的转换
http://esprima.org/demo/parse...
反编译工具全集
小程序
https://github.com/qwerty4721...
推荐.Net、C# 逆向反编译四大工具利器
https://www.cnblogs.com/ldc21...
2018年支持java8的Java反编译工具汇总
https://blog.csdn.net/yannqi/...
原文:http://blog.w3cub.com/blog/20...
链接:https://www.zhihu.com/question/47047191/answer/121013968
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如果是保护知识产权的角度,脱离混淆的js加密是伪命题,无论怎么加密,如果不加以混淆手段保护,都没有意义。如同传统软件的加壳保护,js混淆给底层的加密算法加了最基本的保障,在js层面来说,混淆和加密一定是相辅相成的。
1、为什么需要js混淆显而易见,是为了保护我们的前端代码逻辑。
在web系统发展早期,js在web系统中承担的职责并不多,只是简单的提交表单,js文件非常简单,也不需要任何的保护。
随着js文件体积的增大,为了缩小js体积,加快http传输速度,开始出现了很多对js的压缩工具,比如 uglify、compressor、clouser。。。它们的工作主要是
- 合并多个js文件
- 去除js代码里面的空格和换行
- 压缩js里面的变量名
- 剔除掉注释

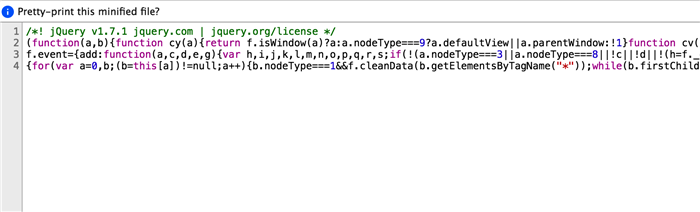 压缩后的代码
压缩后的代码
虽然压缩工具出发点都是为了减少js文件的体积,但是人们发现压缩替换后的代码已经比源代码可读性差了很多,间接起到了代码保护的作用,于是压缩js文件成为了前端发布的标配之一。但是后来市面上主流浏览器chrome、Firefox等都提供了js格式化的功能,能够很快的把压缩后的js美化,再加上现代浏览器强大的debug功能,单纯压缩过的js代码对于真正怀有恶意的人,已经不能起到很好的防御工作,出现了"防君子不防小人"的尴尬局面。
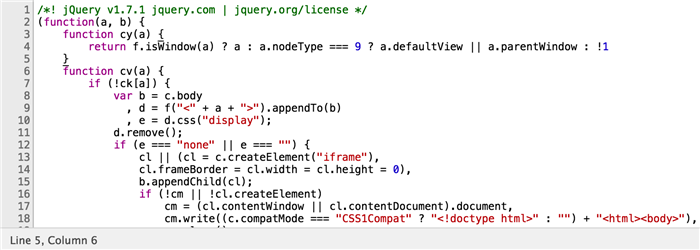
 chrome开发者工具格式化之后的代码
chrome开发者工具格式化之后的代码
而在web应用越来越丰富的今天,伴随着浏览器性能和网速的提高,js承载了更多的工作,不少后端逻辑都在向前端转移,与此同时也让更多的不法分子有机可乘。在web模型中,js往往是不法分子的第一个突破口。知晓了前端逻辑,不法分子可以模拟成一个正常的用户来实施自己的恶意行为。所以,在很多登录、注册、支付、交易等等页面中,关键业务和风控系统依赖的js都不希望被人轻易的破解,js混淆应运而生。
2、js混淆是不是纸老虎
这是一个老生常谈的问题。实际上,代码混淆早就不是一个新鲜的名词,在桌面软件时代,大多数的软件都会进行代码混淆、加壳等手段来保护自己的代码。Java和.NET都有对应的混淆器。黑客们对这个当然也不陌生,许多病毒程序为了反查杀,也会进行高度的混淆。只不过由于js是动态脚本语言,在http中传输的就是源代码,逆向起来要比打包编译后的软件简单很多,很多人因此觉得混淆是多此一举。

 .NET混淆器dotFuscator
.NET混淆器dotFuscator
其实正是因为js传输的就是源代码,我们才需要进行混淆,暴露在外的代码没有绝对的安全,但是在对抗中,精心设计的混淆代码能够给破坏者带来不小的麻烦,也能够为防守者争取更多的时间,相对于破解来说,混淆器规则的更替成本要小得多,在高强度的攻防中,可以大大增加破解者的工作量,起到防御作用。从这个角度来讲,关键代码进行混淆是必不可少的步骤。
3、如何进行js混淆js混淆器大致有两种:
- 通过正则替换实现的混淆器
- 通过语法树替换实现的混淆器
第一种实现成本低,但是效果也一般,适合对混淆要求不高的场景。第二种实现成本较高,但是更灵活,而且更安全,更适合对抗场景,我这里主要讲一下第二种。基于语法层面的混淆器其实类似于编译器,基本原理和编译器类似,我们先对编译器做一些基本的介绍。
名词解释
token: 词法单元,也有叫词法记号的,词法分析器的产物,文本流被分割后的最小单位。
AST: 抽象语法树,语法分析器的产物,是源代码的抽象语法结构的树状表现形式。

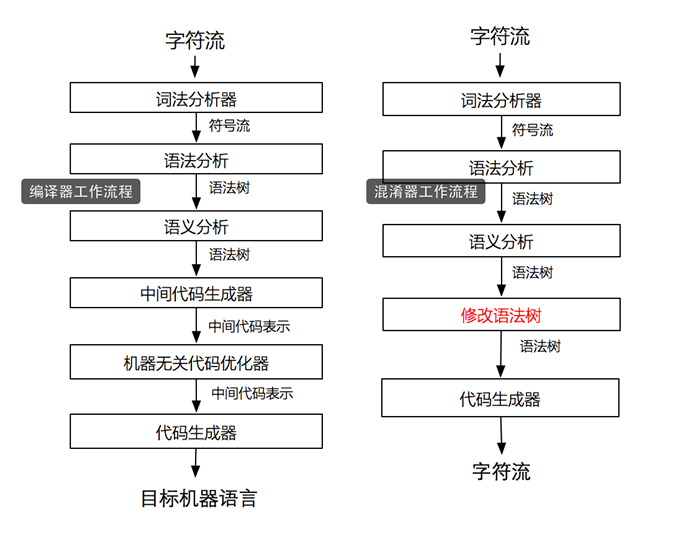 编译器VS混淆器
编译器VS混淆器
编译器工作流程
简单的说,当我们读入一段字符串文本(source code),词法分析器会把它拆成一个一个小的单位(token),比如数字1 是一个token, 字符串'abc'是一个token等等。接下来语法分析器会把这些单位组成一颗树状结构(AST),这个树状结构就代表了token们的组成关系。比如 1 + 2 就会展示成一棵加法树,左右子节点分别是token - 1 和token - 2 ,中间token表示加法。编译器根据生成的AST转换到中间代码,最终转换成机器代码。
对编译器更多细节感兴趣的同学可以移步龙书:编译原理
混淆器工作流程
编译器需要把源代码编译成中间代码或者机器码,而我们的混淆器输出其实还是js。所以我们从语法分析之后往下的步骤并不需要。想想我们的目标是什么,是修改原有的js代码结构,在这里面这个结构对应的是什么呢?就是AST。任何一段正确的js代码一定可以组成一颗AST,同样,因为AST表示了各个token的逻辑关系,我们也可以通过AST反过来生成一段js代码。所以,你只需要构造出一颗AST,就能生成任何js代码!混淆过程如上右图所示
通过修改AST生成一个新的AST,新的AST就可以对应新的JavaScript代码。
规则设计
知道了大致的混淆流程,最重要的环节就是设计规则。我们上面说了,我们需要生成新的AST结构意味着会生成和源代码不一样的js代码,但是我们的混淆是不能破坏原有代码的执行结果的,所以混淆规则必须保证是在不破坏代码执行结果的情况下,让代码变得更难以阅读。
具体的混淆规则各位可以自行根据需求设计,比如拆分字符串、拆分数组,增加废代码等等。
参考:提供商业混淆服务的jscramble的混淆规则
实现
很多人看到这里就望而却步,因为词法分析和文法分析对编译原理要求较高。其实这些现在都有工具可以帮助搞定了,借助工具,我们可以直接进行最后一步,对AST的修改。 市面上JavaScript词法和文法分析器有很多,比如其实v8就是一个,还有mozilla的SpiderMonkey, 知名的esprima等等,我这里要推荐的是uglify,一个基于nodejs的解析器。它具有以下功能:
- parser,把 JavaScript 代码解析成抽象语法树
- code generator,通过抽象语法树生成代码
- scope analyzer,分析变量定义的工具
- tree walker,遍历树节点
- tree transformer,改变树节点
对比下我上面给出的混淆器设计的图,发现其实只需要修改语法树 这一步自己完成。
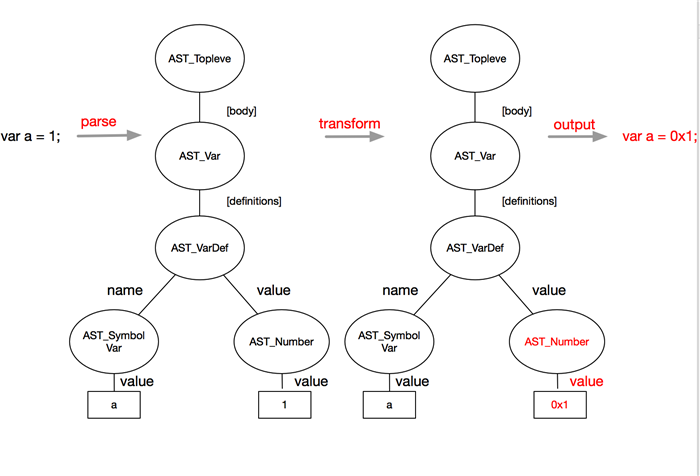
实例
说了这么多,可能很多人还是一头雾水,为了帮助各位理解,我准备了一个简单的例子,假设我们的混淆规则是想把 var a = 1; 中的数字1换成16进制,我们该如何设计混淆器呢。首先对源代码做词法分析和语法分析,uglify一个方法就搞定了,生成一颗语法树,我们需要做的就是找到语法树中的数字然后修改成16进制的结果,如下图所示:
var UglifyJS = require("uglify-js");
var code = "var a = 1;";
var toplevel = UglifyJS.parse(code); //toplevel就是语法树
var transformer = new UglifyJS.TreeTransformer(function (node) {
if (node instanceof UglifyJS.AST_Number) { //查找需要修改的叶子节点
node.value = '0x' + Number(node.value).toString(16);
return node; //返回一个新的叶子节点 替换原来的叶子节点
};
});
toplevel.transform(transformer); //遍历AST树
var ncode = toplevel.print_to_string(); //从AST还原成字符串
console.log(ncode); // var a = 0x1;
上面的代码很简单,首先通过parse方法构建语法树,然后通过TreeTransformer遍历语法树,当遇到节点属于UglifyJS.AST_Number类型(所有的AST类型见ast),这个token具有一个属性 value 保存着数字类型的具体值,我们将其改成16进制表示,然后 return node 就会用新的节点代替原来的节点。
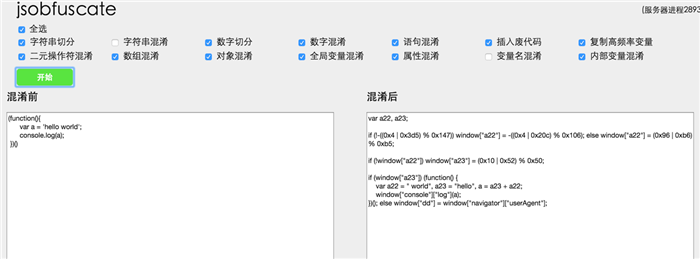
效果展示贴一个我自己设计的混淆器混淆前后代码:

4、混淆对性能的影响
由于增加了废代码,改变了原有的AST,混淆对性能肯定会造成一定的影响,但是我们可以通过规则来控制影响的大小。
- 减少循环混淆,循环太多会直接影响代码执行效率
- 避免过多的字符串拼接,因为字符串拼接在低版本IE下面会有性能问题
- 控制代码体积,在插入废代码时应该控制插入比例,文件过大会给网络请求和代码执行都带来压力
我们通过一定的规则完全可以把性能影响控制在一个合理的范围内,实际上,有一些混淆规则反而会加快代码的执行,比如变量名和属性名的压缩混淆,会减小文件体积,比如对全局变量的复制,会减少作用域的查找等等。在现代浏览器中,混淆对代码的影响越来越小,我们只需要注意合理的混淆规则,完全可以放心的使用混淆。
5、混淆的安全性混淆的目的是保护代码,但是如果因为混淆影响了正常功能就舍本逐末了。
由于混淆后的AST已经和原AST完全不同了,但是混淆后文件的和原文件执行结果必须一样,如何保证既兼顾了混淆强度,又不破坏代码执行呢?高覆盖的测试必不可少:
- 对自己的混淆器写详尽的单元测试
- 对混淆的目标代码做高覆盖的功能测试,保证混淆前后代码执行结果完全一样
- 多样本测试,可以混淆单元测试已经完备了的类库,比如混淆 Jquery 、AngularJS 等,然后拿混淆后的代码去跑它们的单元测试,保证和混淆前执行结果完全一样
你知道吗?JS代码混淆加密,很有用!
JS代码为什么要进行混淆加密?
因为:JS代码是明文。
JS是种开放源码的编程语言,
无论是前端浏览器中的JS代码,还是在后端使用,如nodejs,js代码都是明文,
明文代码,他人可以随意查看、复制、分析、盗用,极不安全!
如果你辛辛苦苦的开发了一个程序、写了一段功能代码,不希望别人随随便便拿走用吧?
那就得对JS代码进行混淆加密、保护JS代码。
如何对JS代码进行混淆加密?
有专业人平台、工具,专门用于JS代码混淆加密。
比如国外的JScramber,国内的JShaman。
以JShaman为例,提供有免费、收费的JS代码混淆加密服务。
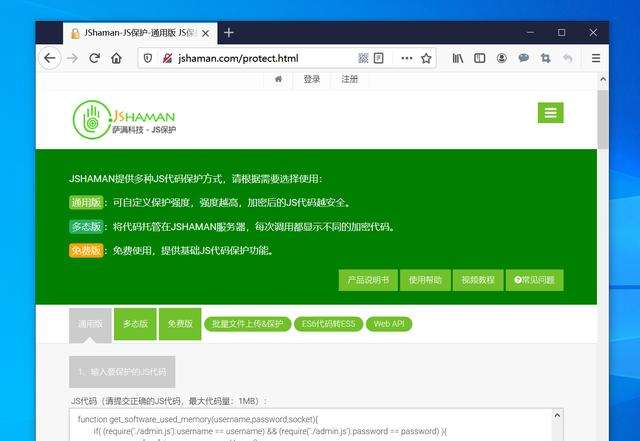
JShaman保护方式也有多种:
- 可以在线提交代码,一键完成混淆加密;
- 也有更高强度的多态变异保护:每次调用,JS代码都会是不同的;
- 还有上传压缩包,完成批量JS文件混淆加密的功能;
- 也提供了WEB API接口,供有需要的三方开发自定义接入使用,当然也可以进行二次开发;
- 更有OEM版,可进行独立部署,供某些安全要求较高的需要方使用;
总体而言,JShaman是国内做的很专业的JS代码保护平台。
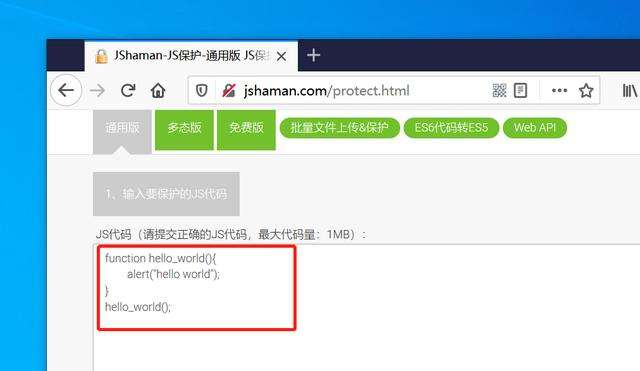
保护效果怎么样?
举个例子,保护前的代码:
保护选项:
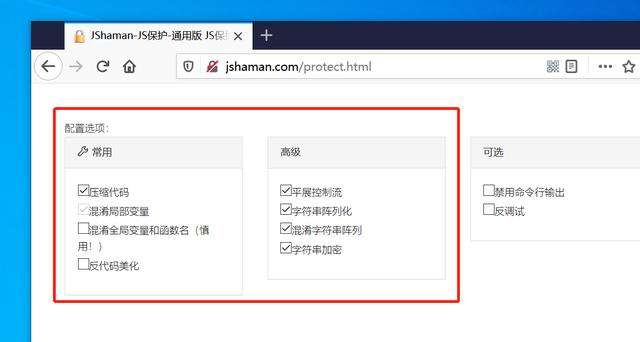
说明:保护选项可以自定义,通常而言,选中的项目越多,安全性越高。
混淆加密后的安全代码:
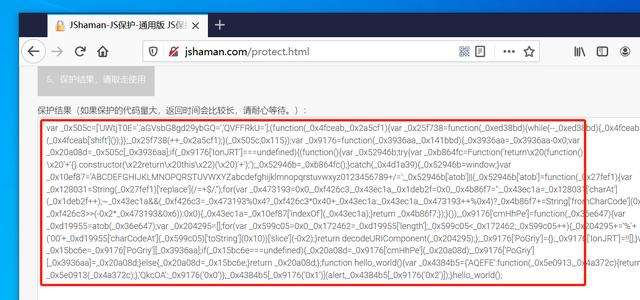
经过保护的JS代码,代码失去了可读性,且不可逆,可以有效防止代码被分析、复制、盗用等问题。