话不多说,先看个案例:
我们有一个分布式缓存,此时我们有3万张图片要存入缓存中。

- 通常我们都会想到,采用哈希算法,对每一个图片进行分片:

余数可以对应到相应的缓存节点,但是这样有一个缺陷:
如果我们新增一个节点【s4】,可以发现一个这样的问题,有一个图片对应ID为6: 以前:6%3=0 --> s0 现在:6%4=2 --> s2 由于服务器数量的改变,导致大量缓存失效,请求只能直接查询数据库,导致数据库容易被压垮
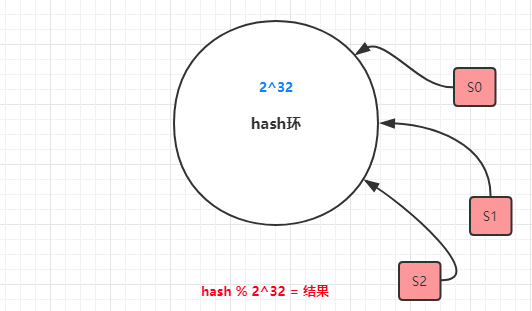
- 我们现在看一下【一致性哈希算法】
策略是采取一个hash环,然后ID取模,找到最近的节点。

此时我们增加一个节点【s4】,会出现什么情况呢?

最终也只是会影响到上图中圈出来的位置数据,影响范围不会很大。
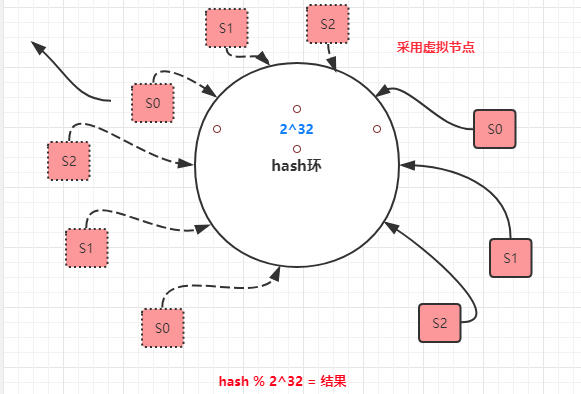
- 不过一致性哈希会出现一个问题?
节点可能会出现【哈希偏斜】情况,即所有的节点都偏斜到一侧,导致【s0】节点缓存数据较多,缓存分布不均匀。
解决方式:可以采用增加虚拟节点的方式,是节点分布尽量均匀,从而解决缓存不均匀的问题。