SVM
mean_precision:0.94,mean_recall:0.82,mean_f:0.88,mean_accuracy:0.85,mean_auc:0.88

Gaussian Naive Bayes¶
mean_precision:0.95,mean_recall:0.78,mean_f:0.86,mean_accuracy:0.83,mean_auc:0.91

logisClassifier
mean_precision:0.90,mean_recall:0.84,mean_f:0.87,mean_accuracy:0.83,mean_auc:0.90
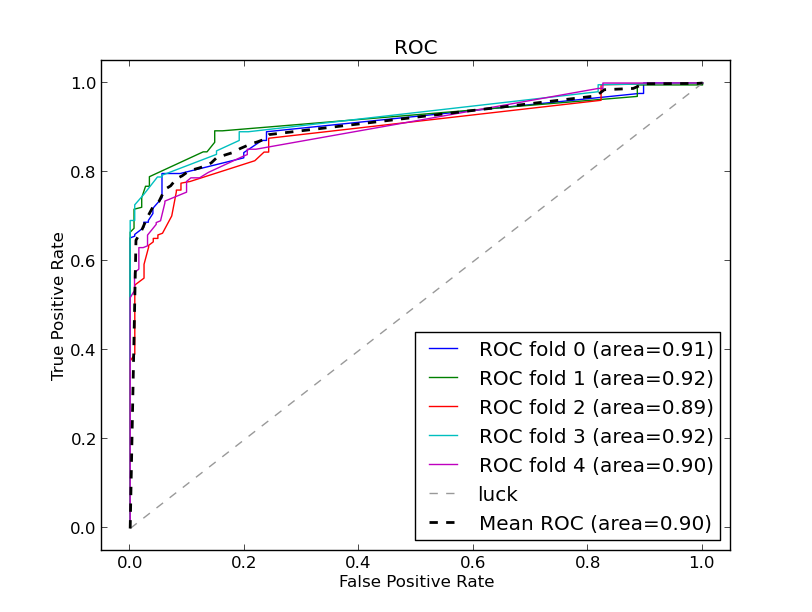
SGD
mean_precision:0.94,mean_recall:0.84,mean_f:0.89,mean_accuracy:0.86,mean_auc:0.93

去除一类属性之后:
mean_precision:0.89,mean_recall:0.64,mean_f:0.75,mean_accuracy:0.71,mean_auc:0.76
mean_precision:0.90,mean_recall:0.76,mean_f:0.82,mean_accuracy:0.79,mean_auc:0.84
mean_precision:0.90,mean_recall:0.82,mean_f:0.86,mean_accuracy:0.82,mean_auc:0.88
mean_precision:0.88,mean_recall:0.72,mean_f:0.79,mean_accuracy:0.75,mean_auc:0.79
mean_precision:0.88,mean_recall:0.70,mean_f:0.78,mean_accuracy:0.74,mean_auc:0.76
mean_precision:0.89,mean_recall:0.81,mean_f:0.85,mean_accuracy:0.81,mean_auc:0.86
mean_precision:0.88,mean_recall:0.77,mean_f:0.82,mean_accuracy:0.78,mean_auc:0.80
最后一次实验的脚本是:


#!/usr/python #!-*-coding=utf8-*- #本周主要工作是对比几种分类算法的差别 import numpy as np import random import myUtil from sklearn import metrics from sklearn import cross_validation from sklearn import svm from sklearn import naive_bayes from sklearn import metrics from sklearn import linear_model from sklearn import ensemble from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer import pylab as pl root_dir="/media/新加卷/小论文实验/data/liweibo" def loadAllFileWithSuffix(suffix): file_list=list() #myUtil.traverseFile(root_dir,suffix,file_list) # file_list.append(root_dir+"/团圆饭/团圆饭.result") # file_list.append(root_dir+"/时间都去哪儿/时间都去哪儿.result") file_list.append(root_dir+"/bobo.pincou") return file_list def loadData(): print "start to preDataByMyOwn..." all_file_list=loadAllFileWithSuffix(['result']) for file_name in all_file_list: print file_name label_list=list() data_list=list() with open(file_name) as in_file: for line in in_file: line_list=list() label_list.append(int(line.strip().split(' ')[0])) all_features=line.strip().split(' ')[1:] for feature in all_features: line_list.append(float(feature)) data_list.append(line_list) data_list=np.array(data_list) label_list=np.array(label_list) return (data_list,label_list) def trainModel(data,classifier,n_folds=5): print "start to trainModel..." x=data[0] y=data[1] #shupple samples n_samples,n_features=x.shape print "n_samples:"+str(n_samples)+"n_features:"+str(n_features) p=range(n_samples) random.seed(0) random.shuffle(p) x,y=x[p],y[p] #cross_validation cv=cross_validation.KFold(len(y),n_folds=5) mean_tpr=0.0 mean_fpr=np.linspace(0,1,100) mean_recall=0.0 mean_accuracy=0.0 mean_f=0.0 mean_precision=0.0 for i,(train,test) in enumerate(cv): print "the "+str(i)+"times validation..." classifier.fit(x[train],y[train]) y_true,y_pred=y[test],classifier.predict(x[test]) mean_precision+=metrics.precision_score(y_true,y_pred) mean_recall+=metrics.recall_score(y_true,y_pred) # mean_accuracy+=metrics.accuracy_score(y_true,y_pred) mean_accuracy+=classifier.score(x[test],y_true) mean_f+=metrics.fbeta_score(y_true,y_pred,beta=1) probas_=classifier.predict_proba(x[test]) fpr,tpr,thresholds=metrics.roc_curve(y[test],probas_[:,1]) mean_tpr+=np.interp(mean_fpr,fpr,tpr) mean_tpr[0]=0.0 roc_auc=metrics.auc(fpr,tpr) pl.plot(fpr,tpr,lw=1,label='ROC fold %d (area=%0.2f)'%(i,roc_auc)) pl.plot([0,1],[0,1],'--',color=(0.6,0.6,0.6),label='luck') mean_precision/=len(cv) mean_recall/=len(cv) mean_f/=len(cv) mean_accuracy/=len(cv) mean_tpr/=len(cv) mean_tpr[-1]=1.0 mean_auc=metrics.auc(mean_fpr,mean_tpr) print("mean_precision:%0.2f,mean_recall:%0.2f,mean_f:%0.2f,mean_accuracy:%0.2f,mean_auc:%0.2f " % (mean_precision,mean_recall,mean_f,mean_accuracy,mean_auc)) pl.plot(mean_fpr,mean_tpr,'k--',label='Mean ROC (area=%0.2f)'% mean_auc,lw=2) pl.xlim([-0.05,1.05]) pl.ylim([-0.05,1.05]) pl.xlabel('False Positive Rate') pl.ylabel('True Positive Rate') pl.title('ROC') pl.legend(loc="lower right") #pl.show() def chooseSomeFeaturesThenTrain(data,clf,choose_index): x=data[0] y=data[1] (n_samples,n_features)=x.shape result_data=np.zeros(n_samples).reshape(n_samples,1) for i in choose_index: if i<1 or i > n_features: print "error feture comination..." return choose_column=x[:,(i-1)].reshape(n_samples,1) result_data=np.column_stack((result_data,choose_column)) result_data=(result_data[:,1:],y) trainModel(result_data,clf) def main(): #尝试四种分类方法 data=loadData() #print "classify by svm:" # clf_svm=svm.SVC(kernel='linear',C=1,probability=True,random_state=0) # trainModel(data,clf_svm) # #采用朴素贝页斯作为分类器 # print "classify by naive_bayes_multinomialNB:" # clf_mnb=naive_bayes.GaussianNB() # trainModel(data,clf_mnb) # #采用逻辑回归作为分类器 # print "classify by logisClassifier" # clf_sgd=linear_model.SGDClassifier(loss='log',penalty='l1') # trainModel(data,clf_sgd) # #利用梯度增强树作为分类器 print "classify by gradientBoostingClassifier" clf_gbc=ensemble.GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0) #trainModel(data,clf_gbc) #尝试不同的属性组合 chooseSomeFeaturesThenTrain(data,clf_gbc,[5,6]) if __name__=='__main__': main()