概述
本人在使用蓝鲸过程有些许心得,所以专门写一个学习笔记供大家参考和学习,当然也为了我日后可以随意参阅。
腾讯蓝鲸智云,简称蓝鲸,是腾讯互动娱乐事业群(Interactive Entertainment Group,简称 IEG)自研自用的一套用于构建企业研发运营一体化体系的 PaaS 开发框架,提供了 aPaaS(DevOps 流水线、运行环境托管、前后台框架)和 iPaaS(持续集成、CMDB、作业平台、容器管理、数据平台、AI 等原子平台)等模块,帮助企业技术人员快速构建基础运营 PaaS。
传统的 Linux 等单机操作系统已发展数十年,随着云时代的到来,企业所需资源数暴增,操作节点(物理或虚拟服务器及容器)数量普遍达到数千个,大型互联网公司甚至达到百万级别,混合云模式成为常态,虽然 IaaS 供应商的出现从一定程度上解决了资源切割调度问题,但并未很好的解决资源与应用的融合,企业需要一种介于 IaaS 与应用(SaaS)之间的层级,用于屏蔽及控制 IaaS,快速开发及托管 SaaS,我们将其称之为基础 PaaS 层,并着重发展用于研发及托管企业内技术运营类 SaaS 的基础运营 PaaS,并将其作为区别于传统 OS 的下一代企业级分布式运营操作系统。
企业 IT 应用的全生命周期可划分为研发、运维、运营三段,在各行业进行互联网化转型的过程中,融入敏捷思维,即形成持续集成、持续部署、持续运营的概念(CI-CD-CO)。
为降低转型成本,不以增加人力数量为转型前提,腾讯 IEG 以运维团队作为转型起点,充分利用这一群体低价值重复性工作量占比高的特点,从 CD 领域切入,以 PaaS 技术进行运维自动化领域的烟囱治理,形成运维 PaaS 体系。将自动化所释放的人力资源,转型为运维开发团队,利用 PaaS 的自增长属性,将运维 PaaS 逐步向 CI 及 CO 拓展,最终完成企业级研发 - 运维 - 运营基础 PaaS 构建,落地企业研发运营一体化。
在这里我给大家普及一下IaaS,SaaS,PaaS的知识:
如果你是一个网站站长,想要建立一个网站。不采用云服务,你所需要的投入大概是:买服务器,安装服务器软件,编写网站程序。
现在你追随潮流,采用流行的云计算,
如果你采用IaaS服务,那么意味着你就不用自己买服务器了,随便在哪家购买虚拟机,但是还是需要自己装服务器软件
而如果你采用PaaS的服务,那么意味着你既不需要买服务器,也不需要自己装服务器软件,只需要自己开发网站程序
如果你再进一步,购买某些在线论坛或者在线网店的服务,这意味着你也不用自己开发网站程序,只需要使用它们开发好的程序,而且他们会负责程序的升级、维护、增加服务器等,而你只需要专心运营即可,此即为SaaS。
蓝鲸体系架构
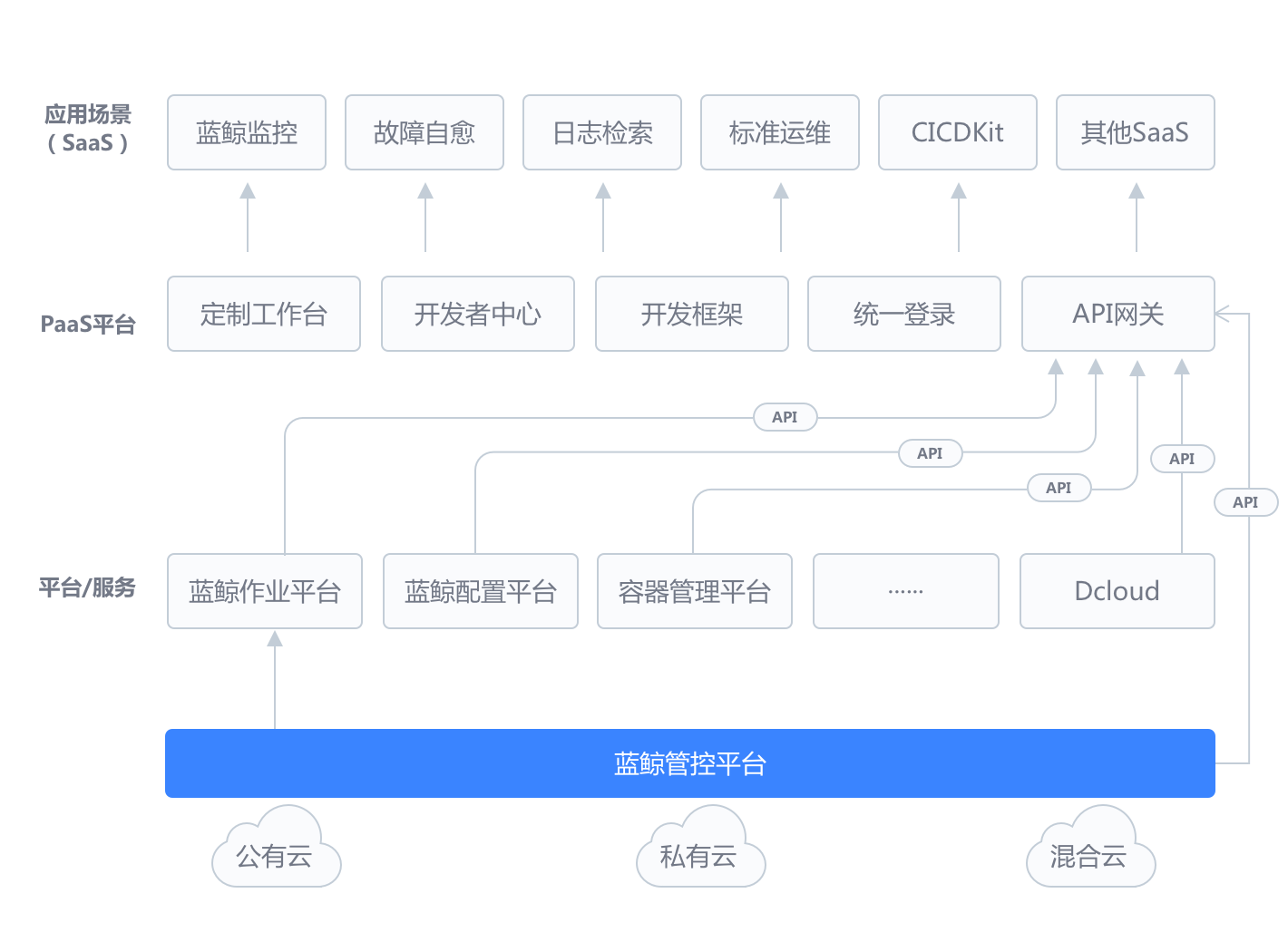
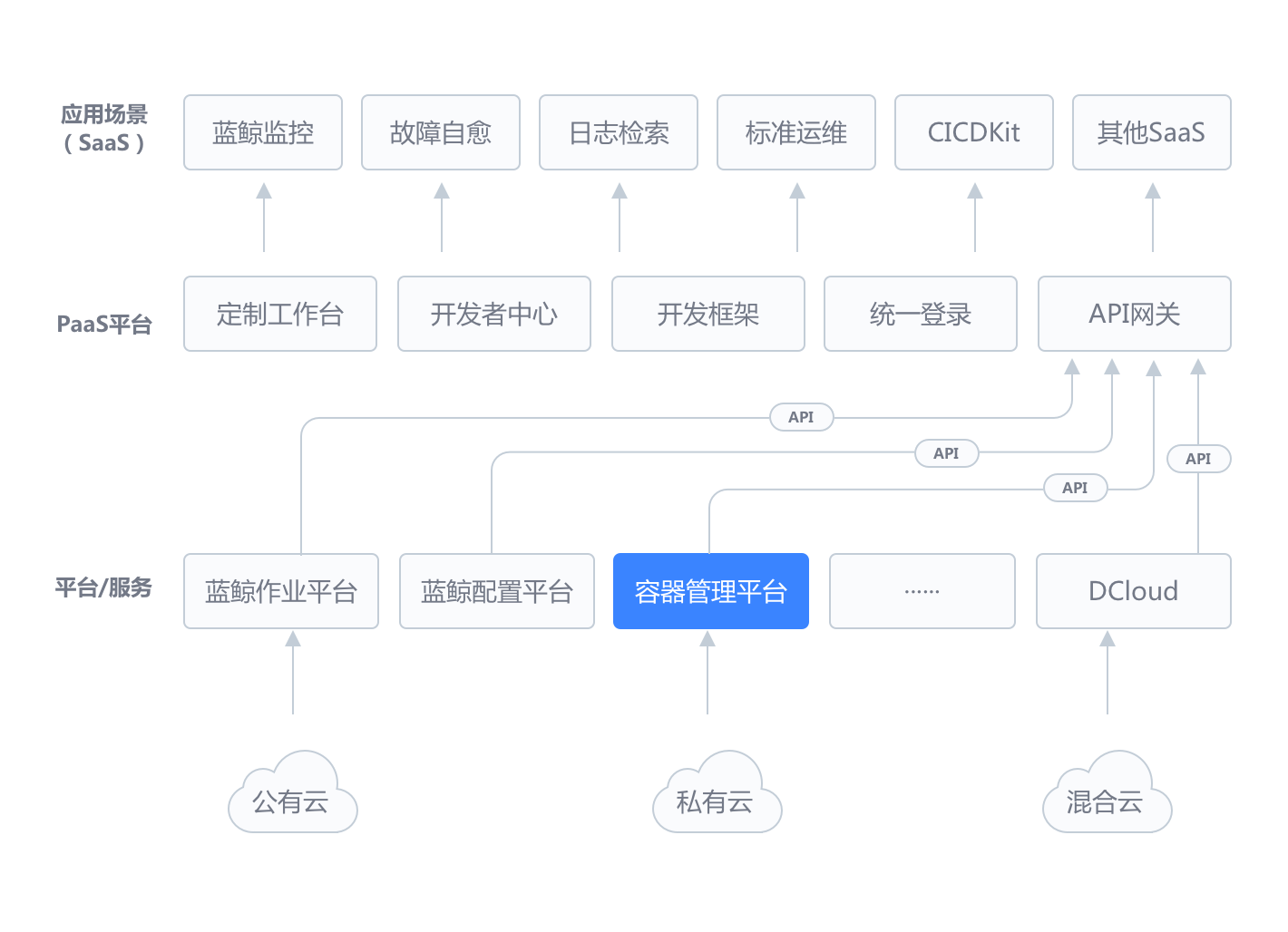
腾讯蓝鲸智云体系由原子平台和通用的一级 SaaS 服务组成,平台包括 管控平台、配置平台、作业平台、数据平台、容器管理、PaaS 平台、移动平台 等,通用 SaaS 包括节点管理、标准运维、日志检索、蓝鲸监控、故障自愈等,为各种云(公有云、私有云、混合云)的用户提供不同场景、不同需求的一站式技术运营解决方案。
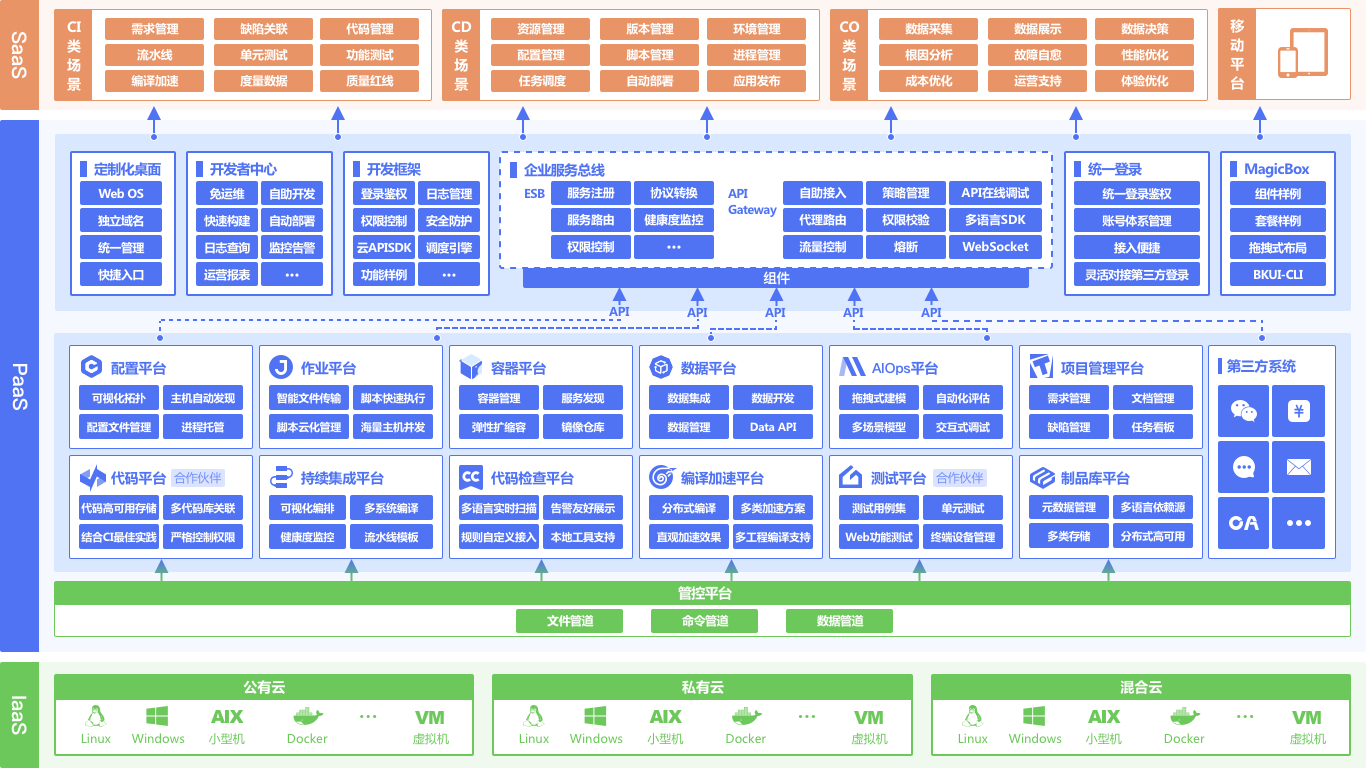
在蓝鲸体系架构中,配置平台位于原子平台层,通过蓝鲸 PaaS 的 ESB 为上层 SaaS 提供覆盖研发运营 CI(持续集成)、CD(持续交付和持续部署)、CO(持续运营)领域的配置管理能力。
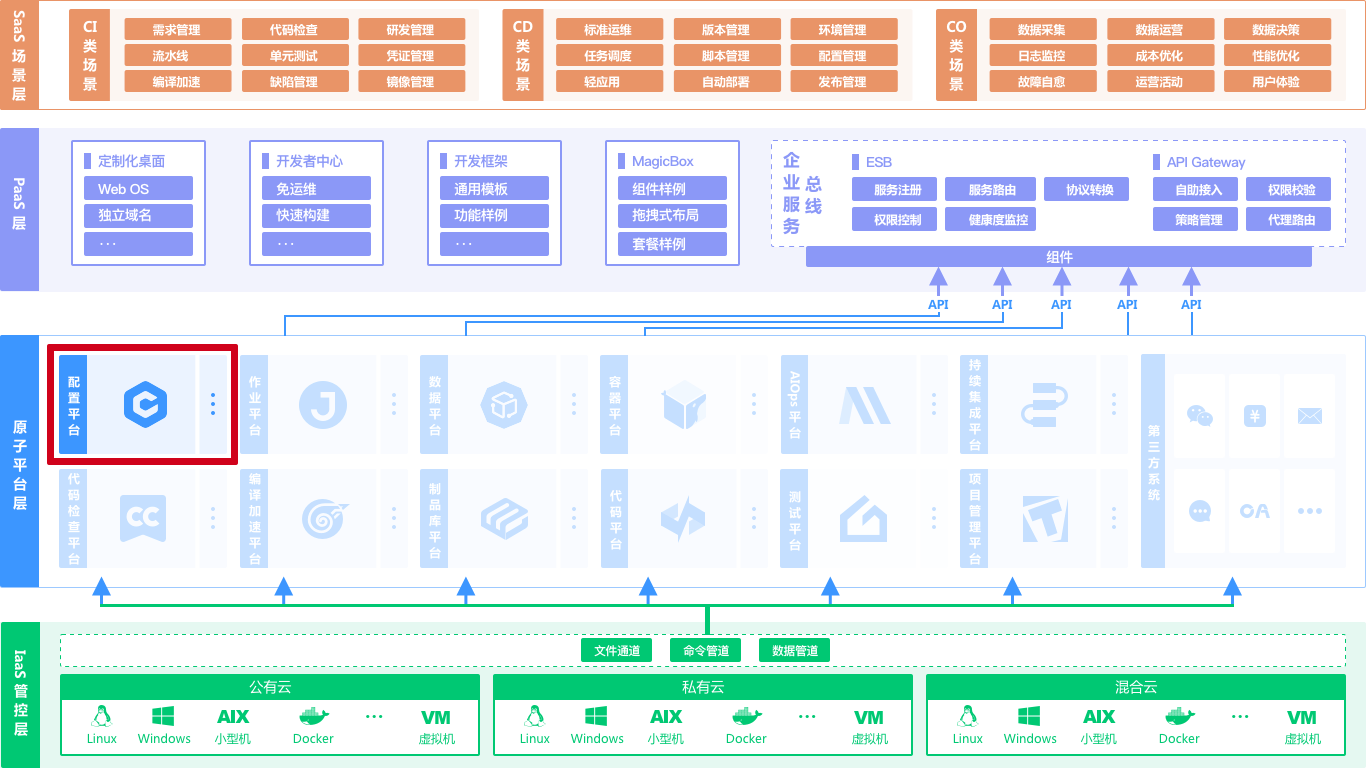
腾讯蓝鲸智云体系依托企业级 SOA、 集成等理念,运用 Docker 等最先进的云技术构建起了全新的运维模式, 致力于以“原子服务集成”和“低成本工具构建”的方式落地 DevOps,帮助运维快速实现“基础服务无人值守”及“增值服务”,并进一步通过 DevOps 的落地实现企业更全面和可持续的效率提升。
蓝鲸部署
对于蓝鲸部署所需的硬件配置选型,并无规定。
蓝鲸由众多开源组件和自研组件构成。
开源组件的硬件选型可以参考相应的官方文档。
蓝鲸产品本身的建议配置如下:
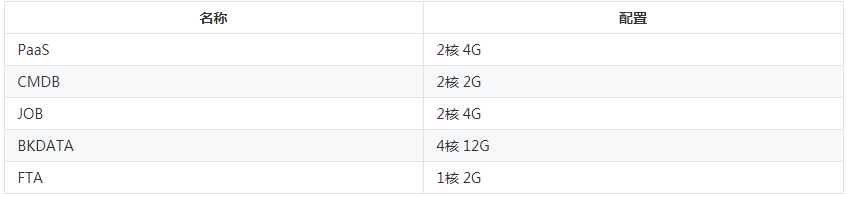
资源规划是一个复杂的、动态的过程,更像是一门艺术而不是科学。如果硬件资源富余,可以一开始拆分搭建部署。若硬件资源不足,一开始可以混合搭建,注意观测资源消耗情况,可以适时增加机器,迁移模块的方式来保证整体的可用性。
这里给出的一个比较合理的初始配置,基于以下考虑:
1. 分布式模块达到高可用至少三个节点,所以至少需要三个 OS (物理机或虚拟机均可)。
2. BKDATA 是耗费资源最多的蓝鲸组件。请分配到 4 核 16G 以上的机器。
3. 若日志检索,蓝鲸监控是主要使用场景,请给 influxdb 和 elasticsearch 模块更多的内存,更好磁盘性能。如 SSD。
4. Nginx 模块所在的机器需要有对外提供服务,可访问的 IP。这是蓝鲸平台的总入口。
5. 如果需要有跨云管理需求,GSE 部署的机器需要有跨云的网络条件。
根据以上考虑,安装蓝鲸初始配置,请满足:
- 1台 4核 16G
- 2台 4核 8G
蓝鲸组件
开源组件
开源组件的实际配置均在 /data/bkce/etc 目录下,而这些配置文件其实是通过变量替换 /data/src/service/support-files/templates/ (模板目录路径随用户解压至的目录而不同) 下的预设模板文件生成的,所以要从源头修改配置应该修改 /data/src 下的,然后通过以下命令同步,并渲染模板文件:
- ./bkcec sync 模块
- ./bkcec render 模块
渲染模板时,bkcec 脚本通过调用 templates_render.rc 里定义的函数 render_cfg_templates 来实现
举例说明,假设 /data/src/service/support-files/templates/ 目录下有如下文件:
- #etc#nginx#job.conf
那么当模板渲染时,它里面的占位符诸如 __BK_HOME__ 会被对应的 $BK_HOME 变量的值替换掉然后生成 /data/bkce/etc/nginx/job.conf 这个文件。 可以发现,脚本将文件名中的 # 替换成 / ,然后放到 $INSTALL_PATH 目录下,也就是默认的 /data/bkce
- kafka#config#server.properties
这个形式的模板文件和上述的不同之处时没有以 # 开头,那么它表示一个相对模块安装路径的配置,也就是 对于 /data/src/service/ 来说,它会被安装到 /data/bkce/service ,那么 kafka#config#server.properties 就会生成到 /data/bkce/service/kafka/config/server.properties
- #etc#my.cnf.tpl
这类文件名和第一个不同之处在于多了 .tpl 的后缀名,生成时 tpl 后缀会被去掉。
其他模块文件,以此类推。
以下列举当前所有的开源组件配置文件路径:
Consul
Consul 的配置文件比较特殊,因为它是全局依赖, Consul 的配置文件会存放在 /data/bkce/etc/consul.conf ,它没有对应的模板文件,是由 /data/install/parse_config 这个脚本来生成。
不过 Consul 启动的 supervisor 配置文件模板在:
- #etc#supervisor-consul.conf
MySQL
- #etc#my.cnf.tpl
Redis
- #etc#redis.conf
Nginx
- #etc#nginx.conf
Nginx 主配置文件,安装时会 ln -s /data/bkce/etc/nginx.conf /etc/nginx/nginx.conf
- #etc#nginx#paas.conf
PaaS 平台的 Nginx server 配置
- #etc#nginx#cmdb.conf
配置平台的 Nginx server 配置,主配置会 include /data/bkce/etc/nginx/ 下的配置文件
- #etc#nginx#job.conf
作业平台的 Nginx server 配置
- #etc#nginx#miniweb.conf
存放 Agent 安装时所需要下载的脚本和依赖软件包
MongoDB
- #etc#mongodb.yaml
ZooKeeper
- #etc#zoo.cfg
RabbitMQ
- #etc#rabbitmq#rabbitmq-env.conf
- #etc#rabbitmq#rabbitmq.config
- #etc#rabbitmq#enabled_plugins
Elasticsearch
- es#config#elasticsearch.yml.tpl
Kafka
- kafka#config#server.properties
Beanstalk
- #etc#beanstalkd
InfluxDB
- #etc#influxdb.conf
蓝鲸组件
蓝鲸组件除了作业平台和管控平台,其他均用 supervisor 来做进程启停,所以都会存在一个对应的 supervisor 进程配置文件
它的标准规范是:#etc#supervisor-模块名-工程名.conf,如果没有子工程,则工程名等于模块名。
例如 bkdata 存在三个子工程,所以各自的 supervisor 配置为:
- #etc#supervisor-bkdata-dataapi.conf
- #etc#supervisor-bkdata-databus.conf
- #etc#supervisor-bkdata-dataapi.conf
故障自愈模块,因为没有子工程,所以它的 supervisor 配置文件为:
- #etc#supervisor-fta-fta.conf
因为 supervisor 配置具有一致性,下面不再具体列举 supervisor 相关配置文件。
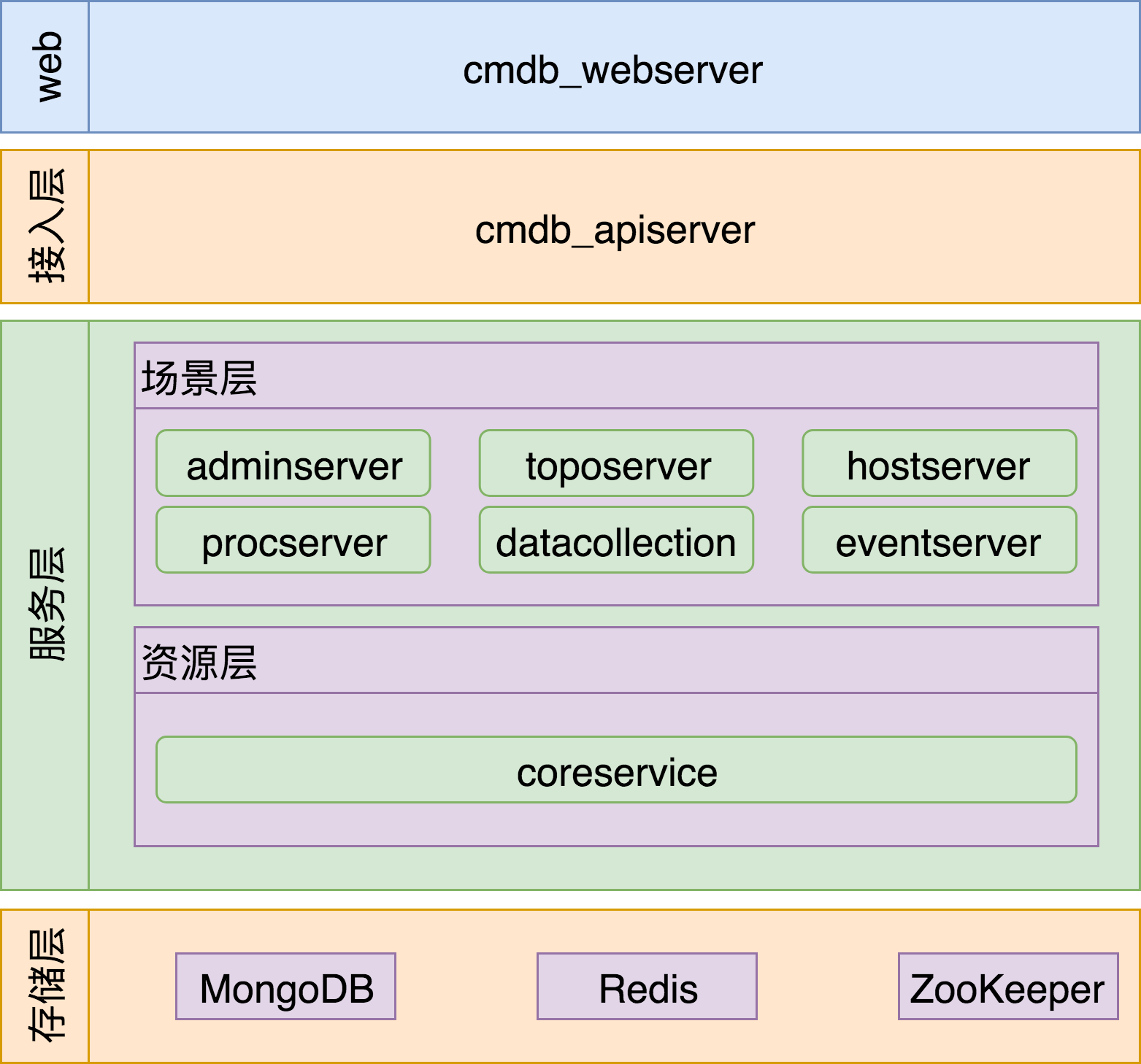
配置平台 CMDB
CMDB 的后台是微服务化架构,每个进程对应一个配置文件,所以配置文件模板也有很多,
- server#conf#模块名.conf
模块名对应进程名,比如进程名叫 cmdb_webserver 那它对应的配置文件名叫 webserver.conf
- #etc#nginx#cmdb.conf
CMDB 进程对应的 Nginx 配置,里面会通过 url rewrite 兼容 v2 的接口。cmdb_webserver 提供的 Web 页面 也是经过这层 Nginx 反向代理。
作业平台 JOB
作业平台的配置文件比较简单。一个配置文件,一个启动脚本:
- #etc#job.conf
主配置文件,里面的中文注释非常详尽,这里不再赘述。
- job#bin#job.sh
Job 进程的启停脚本,里面可以设置一些调试参数,Java 虚拟机内存分配大小等
PaaS
PaaS 平台 在 src 目录下叫 open_paas 它实际上由 appengine login esb paas 四个子工程组成。
- #etc#uwsgi-open_paas-工程名.ini
这里工程名用上面四个工程分别替换可得到,是这四个 Python 工程 uwsgi 的配置文件
以下四个分别是对应工程的 配置文件
- paas#conf#settings_production.py.tpl
- login#conf#settings_production.py.tpl
- esb#configs#default.py.tpl
- appengine#controller#settings.py.tpl
其中 ESB 的配置中,配置了访问其他周边模块的接口域名和端口。
GSE
GSE 目录下的模板文件分为 agent、plugins、proxy、后台。
GSE 后台的配置模板,需要留意的是生成后的配置中监听的 IP 地址是否符合预期:
- #etc#gse#api.conf
- #etc#gse#btsvr.conf
- #etc#gse#data.conf
- #etc#gse#dba.conf
- #etc#gse#task.conf
GSE Proxy 后台的配置模板:
- proxy#etc#btsvr.conf
- proxy#etc#proxy.conf
- proxy#etc#transit.conf
GSE Agent 的配置模板,* 表示匹配所有的,这里 Agent 按系统和 CPU 架构区分了不同的目录
- agent_*#etc#agent.conf
- agent_*#etc#iagent.conf
- agent_*#etc#procinfo.conf
GSE agent plugins 的配置模板
- plugins_*#etc#basereport.conf
- plugins_*#etc#alarm.json
paas_agent
paas_agent 是 appo、和 appt 模块对应的后台代码目录,它的配置文件由两部分构成:
- #etc#nginx.conf #etc#nginx#paasagent.conf
paas_agent 依赖一个 Nginx 做路由转发,这里是它的 Nginx 配置
- #etc#paas_agent_config.yaml.tpl
paas_agent 的主配置,需要特别注意的是,这里的 sid 和 token 是激活 paas_agent 成功后,获取返回的字符串自动填充的,里面的配置应该和开发者中心,服务器信息页面看到的一致
BKDATA
BKDATA 分为dataapi 、 databus 、 monitor 三个工程,
dataapi 是 Python 工程,databus 是 Java 工程,monitor 是 Python 工程。
dataapi 的配置:
- dataapi#conf#dataapi_settings.py
- dataapi#pizza#settings_default.py
- dataapi#tool#settings.py
databus 的配置:
- databus#conf#es.cluster.properties
- databus#conf#jdbc.cluster.properties
- databus#conf#tsdb.cluster.properties
- databus#conf#etl.cluster.properties
- databus#conf#redis.cluster.properties
monitor 的配置:
- monitor#bin#environ.sh
- monitor#conf#worker#production#community.py
故障自愈 FTA
故障自愈后台的配置
fta#project#settings_env.py
PaaS平台
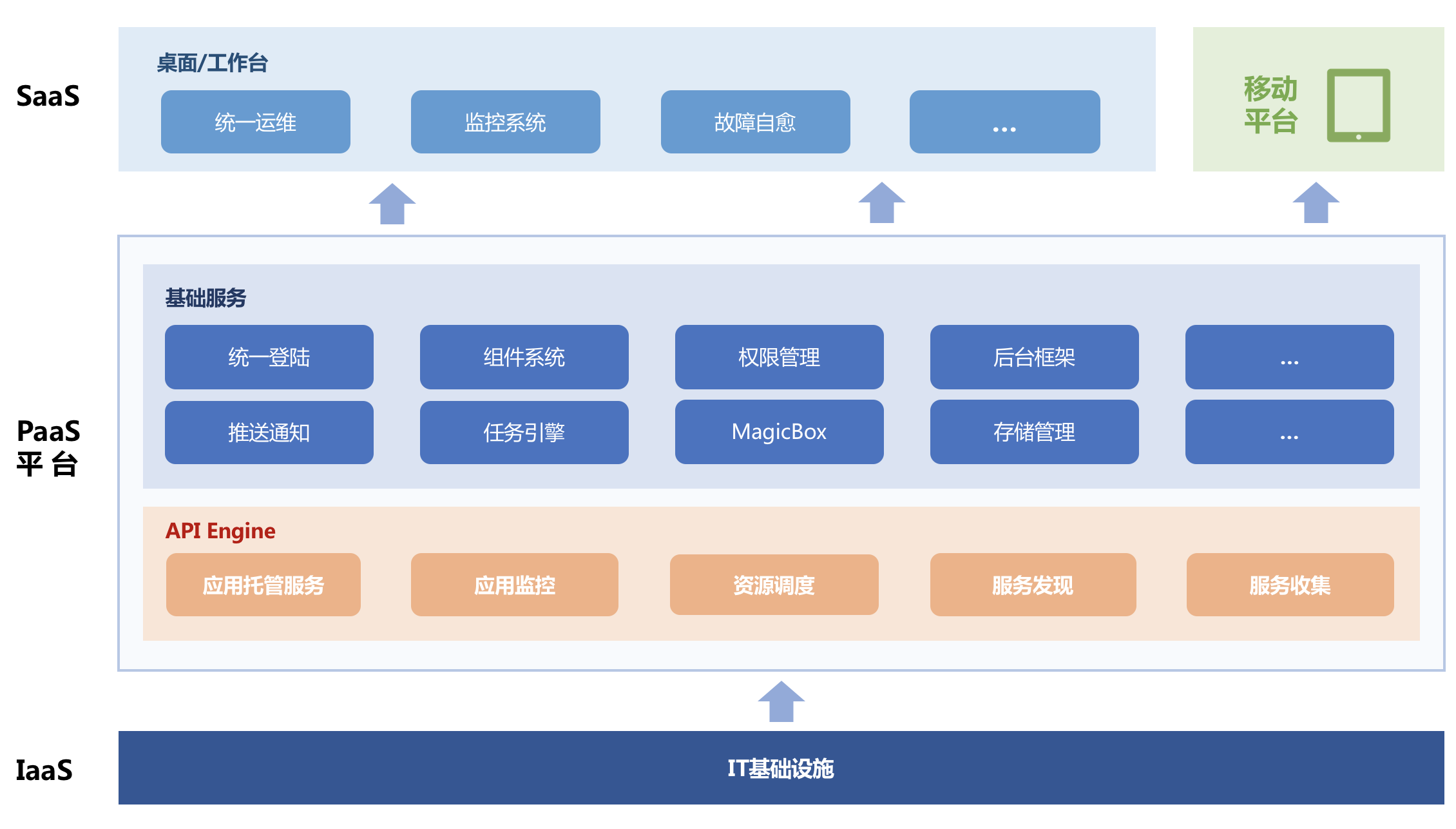
蓝鲸 PaaS 平台是一个开放的平台,又称蓝鲸 PaaS。该产品在蓝鲸体系中有 3 个重要的作用:
一、面向普通用户,它是进入蓝鲸体系的第一个产品,提供了通用的基础服务,如登录认证、消息通知、其他产品的快捷入口(工作台)、获取更多产品的应用市场等;
二、面向开发人员,它提供了很多的 “SaaS 开发者服务”,让开发者可以简单、快速地创建、部署和管理应用,它提供了完善的前后台开发框架、API 网关(ESB)、调度引擎、公共组件等模块,帮助开发者快速、低成本、免运维地构建支撑工具和运营系统。PaaS 平台为一个应用从创建到部署,再到后续的维护管理提供了完善的自助化和自动化服务,如日志查询、监控告警、运营数据等,从而使开发者可以将全部精力投入到应用的开发之中。主要功能有:支持多语言的开发框架 / 样例、免运维托管、SaaS 运营数据可视化、企业服务总线(API 网关)、可拖拽的前端服务(MagicBox)等。
三、面向系统维护人员(系统管理员),它提供了用户管理(含角色管理)、服务器基本信息维护、第三方服务可视化管理、API 权限控制等功能,更好地维护和管理平台的可用性。
目前,蓝鲸 PaaS 平台已正式对外开源,GitHub 地址: https://github.com/Tencent/bk-PaaS
配置平台
蓝鲸配置平台是一款面向应用的 CMDB,在 ITIL 体系里,CMDB 是构建其它流程的基石,而在蓝鲸智云体系里,配置平台就扮演着基石的角色,为应用提供了各种运维场景的配置数据服务。它是企业 IT 管理体系的核心,通过提供配置管理服务,以数据和模型相结合映射应用间的关系,保证数据的准确和一致性;并以整合的思路推进,最终面向应用消费,发挥配置服务的价值。
目前,蓝鲸配置平台已正式对外开源,GitHub 地址: https://github.com/Tencent/bk-cmdb
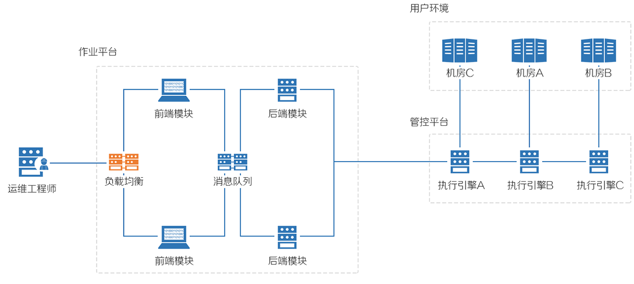
作业平台
作业平台(JOB)是一套基于蓝鲸智云管控平台 Agent 管道之上的基础操作平台,具备万级并发处理能力。除了支持脚本执行、文件拉取 / 分发、定时任务等一系列可实现的基础运维场景以外,还运用流程化的理念很好的将零碎的单个任务组装成一个作业流程。而每个任务都可做为一个原子节点,提供给其它系统和平台调度,实现调度自动化。
除了批量执行的万级高并发性能优势,作业平台还支持复杂的运维操作场景,定制作业功能将一个操作流程制作成完整的作业任务,丰富的 API 开放接口使得作业任务原子化,提供给其它系统或平台进行调度,进一步扩大了业务使用场景。

作业平台分为 Web 层和后台任务调度层,并通过消息队列来消费任务,任务执行依赖底层的管控平台,管控平台采用 C/S 架构,用户只需要在目标机上安装蓝鲸 Agent,即可通过作业平台实现脚本执行或文件分发。
管控平台
蓝鲸管控平台,是整个蓝鲸平台的底层管控系统,是蓝鲸所有其他服务的基础,是蓝鲸服务体系与用户机器的连接器。
在整个蓝鲸体系中,蓝鲸管控平台作为蓝鲸的底层管控通道,没有提供独立的接口供用户直接访问调用,而是通过蓝鲸 esb 能力向上提供服务,供上层平台或者 SaaS 去实现场景赋能,蓝鲸管控平台主要提供了三种类型的服务能力:文件传输能力、实时任务执行能力、数据采集与传输的能力。
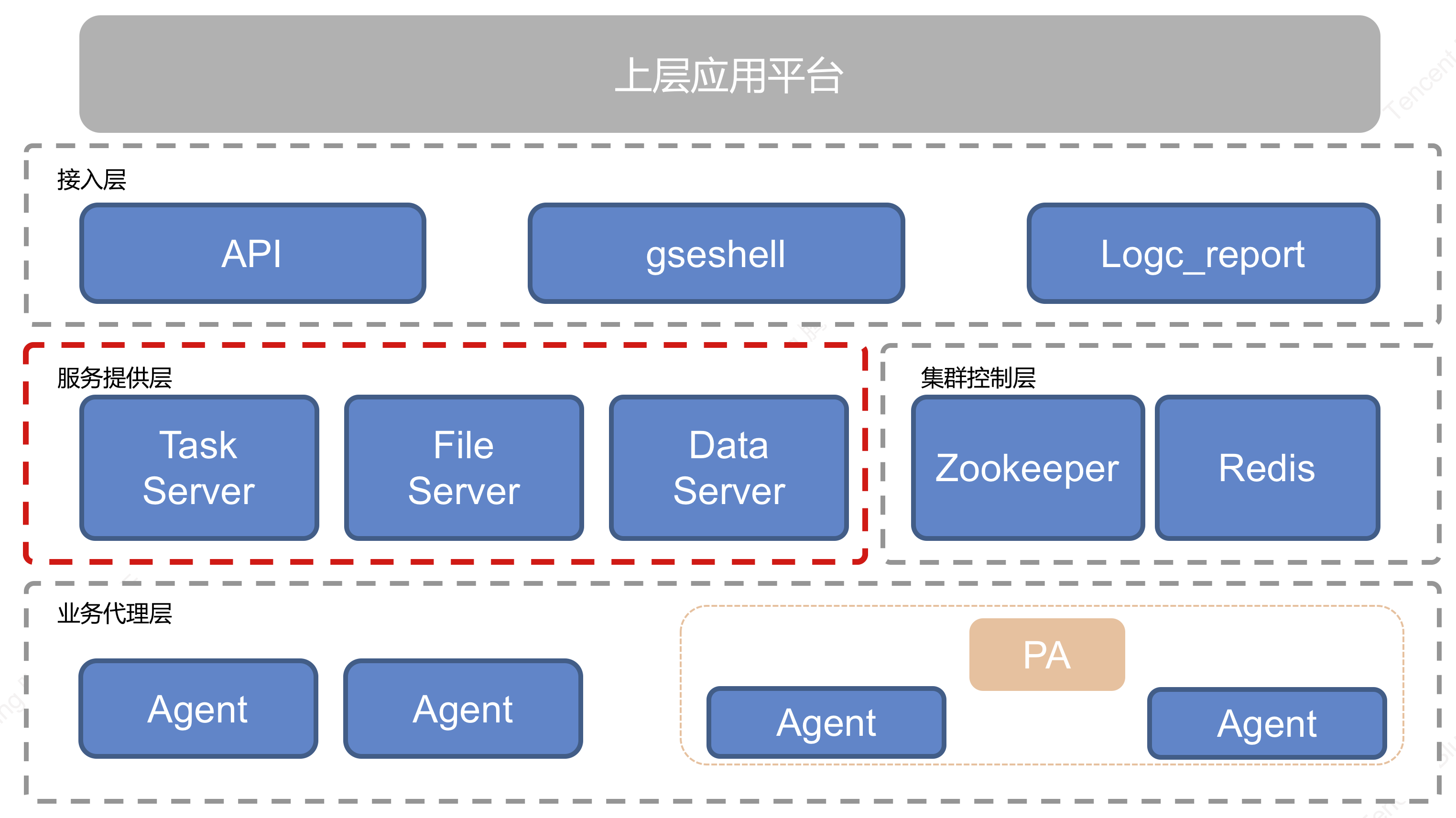
从网络框架层面来看,蓝鲸管控平台分为两层网络架构,分别为 服务层 和 业务代理层 ,服务层由三种不同类型的服务集群构成:控制任务执行的 TaskServer 集群、负责数据采集传输服务的 DataServer 集群以及提供文件高速传输服务的 FileServer 集群,业务代理层则是部署在业务服务器上的蓝鲸Agent,承载了服务层提供的三种服务。
Agent:蓝鲸智能 Agent,可以安装在业务需要管控的 实体机、虚拟机或者容器里面 ,BK Agent 是蓝鲸管控平台提供三大服务能力的实际执行者。
PA:蓝鲸管控平台跨云代理节点,为云区域 BK Agent 提供代理转发服务,提供跨云区域机器管控能力。
TaskServer:蓝鲸管控平台任务及控制服务端程序,该程序提供对集群内 Agent 的管理能力,并支持对 Agent 批量下发和执行发命令或脚本。
FileServer:蓝鲸管控平台文件传输控制服务端程序,该程序对指定范围内 Agent 节点提供 BT 种子服务,保证对传输的安全性、不同区域及业务模块间的隔离性,并控制 BT 传输在有限的贪婪特性范围内。
DataServer:蓝鲸管控平台数据传输服务端程序,该服务端主要提供对 Agent 采集的数据进行汇聚、分类、流转能力。对于普通的千兆网卡机器,BK DataServer 能够提供百兆级别的数据处理能力。
Redis:Redis 在本系统中提供工作区数据缓存作用。
Zookeeper:Zookeeper 主要提供对集群的管理能力,包括集群中不同节点间的相互发现,有效性探测等。
容器管理平台
蓝鲸容器服务(BCS,Blueking Container Service)是 高度可扩展、灵活易用的容器管理服务。
蓝鲸容器服务支持两种不同的集群模式,分别为原生 Kubernetes 模式和基于 Mesos 自研的模式。
用户无需关注基础设施的安装、运维和管理,只需要调用简单的 API,或者在页面上进行简单的配置,便可对容器进行启动、停止等操作,查看集群、容器及服务的状态,以及使用各种组件服务。
用户可以依据自身的需要选择容器编排的方式,以满足业务的特定要求。
BCS 是统一的容器部署管理解决方案,为了适应不同业务场景的需要,BCS 内部同时支持基于 Mesos 和基于 K8S 的两种不同的实现。
BCS 由 BCS SaaS 和 BCS 后台 组成,以下为对应的架构图。
BCS SaaS 架构图
BCS SaaS 功能结构图
BCS SaaS 作为 BCS 的上层产品,包含已开源的项目管理系统(bcs-projmgr)、容器服务产品层主体功能模块(bcs-app)、底层的配置中心模块(bcs-cc)以及未开源的监控中心,同时它依赖蓝鲸体系下的其他产品服务(如 PaaS、CMDB 等)。

SaaS 依赖的服务介绍:
-
bk-PaaS: 为 BCS SaaS 提供了 4 大服务(统一登录、开发者中心、ESB 和应用引擎),其中 bcs-app 由应用引擎托管
-
bk-bcs-services: BCS 底层服务。作为后台服务,bk-bcs-services 给 bcs-app 提供了集群搭建,应用编排等丰富的底层接口,更多详见下 BCS 后台架构图 。
-
bk-cmdb: 蓝鲸配置平台。bcs-app 的集群管理功能涉及的业务和主机信息来源于配置平台
-
bk-iam: 蓝鲸权限中心,BCS SaaS 基于 bk-iam,实现了用户与平台资源之间的权限控制
-
bk-Habor: 蓝鲸容器管理平台镜像仓库服务。bcs-app 使用 bk-Habor 提供的 API,实现了业务镜像的查询与配置功能
BCS SaaS 部署拓扑图
SaaS 包含 bcs-projmgr, bcs-app, bcs-cc 三个模块。
SaaS 依赖的后端服务 bk-bcs-services 也已开源,bk-iam 等灰色标注的系统暂未开源,需要依托蓝鲸独立部署版本进行搭建。

BCS 后台架构图
下图为 BCS 以及 Mesos 集群的整体架构图:BCS Client 或者业务 SaaS 服务通过 API 接入,API 根据访问的集群将请求路由到 BCS 下的 Mesos 集群或者 K8S 集群。

Kubenetes 容器编排的说明:
- BCS 支持原生 K8S 的使用方式。
- K8S 集群运行的 Agent(bcs-k8s-agent) 向 BCS API 服务进行集群注册。
- K8S 集群运行的 Data Watch 负责将该集群的数据同步到 BCS Storage。
Mesos 编排的具体说明:
- Mesos 自身包括 Mesos Master 和 Mesos Slave 两大部分,其中 Master 为中心管理节点,负责集群资源调度管理和任务管理;Slave 运行在业务主机上,负责宿主机资源和任务管理。
- Mesos 为二级调度机制,Mesos 本身只负责资源的调度,业务服务的调度需要通过实现调度器(图中 Scheduler)来支持,同时需实现执行器 Executor(Mesos 自身也自带有 Executor)来负责容器或者进程的起停和状态检测上报等工作。
- Mesos(Master 和 Slave)将集群当前可以的资源以 offer(包括可用 CPU、MEMORY、DISK、端口以及定义的属性键值对)的方式上报给 Scheduler,Scheduler 根据当前部署任务来决定是否接受 Offer,如果接受 Offer,则下发指令给 Mesos,Mesos 调用 Executor 来运行容器。
- Mesos 集群数据存储在 ZooKeeper,通过 Datawatch 负责将集群动态数据同步到 BCS 数据中心。
- Mesos Driver 负责集群接口转换。
- 所有中心服务多实例部署实现高可用:Mesos driver 为 Master-Master 运行模式,其他模块为 Master-Slave 运行模式。服务通过 ZooKeeper 实现状态同步和服务发现。
总结
本人本着学习和选择比较重要的部分进行摘抄和总结官网,详细见官方文档:https://bk.tencent.com/docs/