概述
现在介绍学习一下kafka的请求处理模块,请求处理模块就是网络请求处理和api处理,这是kafka无论是对客户端还是集群内部都是非常重要的模块。现在我们对他进行源码深入探讨。当我们说到 Kafka 服务器端,也就是 Broker 的时候,往往会说它承担着消息持久化的功能,但本质上,它其实就是一个不断接收外部请求、处理请求,然后发送处理结果的 Java 进程。
kafka请求队列
高效地保存排队中的请求,是确保 Broker 高处理性能的关键。既然这样,那你一定很想知道,Broker 上的请求队列是怎么实现的呢?接下来,我们就一起看下 Broker 底层请求对象的建模和请求队列的实现原理,以及 Broker请求处理方面的核心监控指标。目前,Broker 与 Clients 进行交互主要是基于Request/Response 机制,所以,我们很有必要学习一下源码是如何建模或定义 Request 和 Response 的。
请求(Request)
我们先来看一下 RequestChannel 源码中的 Request 定义代码。
1 sealed trait BaseRequest 2 case object ShutdownRequest extends BaseRequest 3 4 class Request(val processor: Int, 5 val context: RequestContext, 6 val startTimeNanos: Long, 7 memoryPool: MemoryPool, 8 @volatile private var buffer: ByteBuffer, 9 metrics: RequestChannel.Metrics) extends BaseRequest { 10 ...... 11 }
Request 则是真正定义各类 Clients 端或 Broker 端请求的实现类。它定义的属性包括 processor、context、startTimeNanos、memoryPool、buffer 和 metrics。下面我们一一来看。
processorprocessor 是 Processor 线程的序号,即这个请求是由哪个 Processor 线程接收处理的。Broker 端参数 num.network.threads 控制了 Broker 每个监听器上创建的 Processor 线程数。假设你的 listeners 配置为 PLAINTEXT://localhost:9092,SSL://localhost:9093,那么,在默认情况下,Broker 启动时会创建 6 个 Processor 线程,每 3 个为一组,分别给 listeners 参数中设置的两个监听器使用,每组的序号分别是 0、1、2。
contextcontext 是用来标识请求上下文信息的。Kafka 源码中定义了 RequestContext 类,顾名思义,它保存了有关 Request 的所有上下文信息。RequestContext 类定义在 clients 工程中,
startTimeNanosstartTimeNanos 记录了 Request 对象被创建的时间,主要用于各种时间统计指标的计算。请求对象中的很多 JMX 指标,特别是时间类的统计指标,都需要使用 startTimeNanos 字段。你要注意的是,它是以纳秒为单位的时间戳信息,可以实现非常细粒度的时间统计精度。
memoryPoolmemoryPool 表示源码定义的一个非阻塞式的内存缓冲区,主要作用是避免 Request 对象无限使用内存。当前,该内存缓冲区的接口类和实现类,分别是 MemoryPool 和 SimpleMemoryPool。你可以重点关注下 SimpleMemoryPool 的 tryAllocate 方法,看看它是怎么为 Request 对象分配内存的。
bufferbuffer 是真正保存 Request 对象内容的字节缓冲区。Request 发送方必须按照 Kafka RPC 协议规定的格式向该缓冲区写入字节,否则将抛出 InvalidRequestException 异常。这个逻辑主要是由 RequestContext 的 parseRequest 方法实现的。
metricsmetrics 是 Request 相关的各种监控指标的一个管理类。它里面构建了一个 Map,封装了所有的请求 JMX 指标。除了上面这些重要的字段属性之外,Request 类中的大部分代码都是与监控指标相关的,后面我们再详细说。
响应(Response)
说完了 Request 代码,我们再来说下 Response。Kafka 为 Response 定义了 1 个抽象父类和 5 个具体子类。Okay,现在,我们看下 Response 相关的代码部分。
1 abstract class Response(val request: Request) { 2 locally { 3 val nowNs = Time.SYSTEM.nanoseconds 4 request.responseCompleteTimeNanos = nowNs 5 if (request.apiLocalCompleteTimeNanos == -1L) 6 request.apiLocalCompleteTimeNanos = nowNs 7 } 8 def processor: Int = request.processor 9 def responseString: Option[String] = Some("") 10 def onComplete: Option[Send => Unit] = None 11 override def toString: String 12 }
这个抽象基类只有一个属性字段:request。这就是说,每个 Response 对象都要保存它对应的 Request 对象。我在前面说过,onComplete 方法是调用指定回调逻辑的地方。SendResponse 类就是复写(Override)了这个方法,如下所示:
1 class SendResponse(request: Request, 2 val responseSend: Send, 3 val responseAsString: Option[String], 4 val onCompleteCallback: Option[Send => Unit]) 5 extends Response(request) { 6 ...... 7 override def onComplete: Option[Send => Unit] = onCompleteCallback 8 }
这里的 SendResponse 类继承了 Response 父类,并重新定义了 onComplete 方法。复写的逻辑很简单,就是指定输入参数 onCompleteCallback。
RequestChannel
RequestChannel,顾名思义,就是传输 Request/Response 的通道。有了 Request 和 Response 的基础,下面我们可以学习 RequestChannel 类的实现了。我们先看下 RequestChannel 类的定义和重要的字段属性。
1 class RequestChannel(val queueSize: Int, val metricNamePrefix : String) extends KafkaMetricsGroup { 2 import RequestChannel._ 3 val metrics = new RequestChannel.Metrics 4 private val requestQueue = new ArrayBlockingQueue[BaseRequest](queueSize) 5 private val processors = new ConcurrentHashMap[Int, Processor]() 6 val requestQueueSizeMetricName = metricNamePrefix.concat(RequestQueueSizeMetric) 7 val responseQueueSizeMetricName = metricNamePrefix.concat(ResponseQueueSizeMetric) 8 9 ...... 10 }
RequestChannel 类实现了 KafkaMetricsGroup trait,后者封装了许多实用的指标监控方法,比如,newGauge 方法用于创建数值型的监控指标,newHistogram 方法用于创建直方图型的监控指标。就 RequestChannel 类本身的主体功能而言,它定义了最核心的 3 个属性:requestQueue、queueSize 和 processors。下面我分别解释下它们的含义。
每个 RequestChannel 对象实例创建时,会定义一个队列来保存 Broker 接收到的各类请求,这个队列被称为请求队列或 Request 队列。Kafka 使用 Java 提供的阻塞队列 ArrayBlockingQueue 实现这个请求队列,并利用它天然提供的线程安全性来保证多个线程能够并发安全高效地访问请求队列。在代码中,这个队列由变量requestQueue定义。而字段 queueSize 就是 Request 队列的最大长度。
当 Broker 启动时,SocketServer 组件会创建 RequestChannel 对象,并把 Broker 端参数 queued.max.requests 赋值给 queueSize。因此,在默认情况下,每个 RequestChannel 上的队列长度是 500。字段 processors 封装的是 RequestChannel 下辖的 Processor 线程池。每个 Processor 线程负责具体的请求处理逻辑。下面我详细说说 Processor 的管理。
Processor 管理
上面代码中的第4行创建了一个 Processor 线程池——当然,它是用 Java 的 ConcurrentHashMap 数据结构去保存的。Map 中的 Key 就是前面我们说的 processor 序号,而 Value 则对应具体的 Processor 线程对象。这个线程池的存在告诉了我们一个事实:当前 Kafka Broker 端所有网络线程都是在 RequestChannel 中维护的。既然创建了线程池,代码中必然要有管理线程池的操作。RequestChannel 中的 addProcessor 和 removeProcessor 方法就是做这些事的。
1 def addProcessor(processor: Processor): Unit = { 2 // 添加Processor到Processor线程池 3 if (processors.putIfAbsent(processor.id, processor) != null) 4 warn(s"Unexpected processor with processorId ${processor.id}") 5 newGauge(responseQueueSizeMetricName, 6 () => processor.responseQueueSize, 7 // 为给定Processor对象创建对应的监控指标 8 Map(ProcessorMetricTag -> processor.id.toString)) 9 } 10 11 def removeProcessor(processorId: Int): Unit = { 12 processors.remove(processorId) // 从Processor线程池中移除给定Processor线程 13 removeMetric(responseQueueSizeMetricName, Map(ProcessorMetricTag -> processorId.toString)) // 移除对应Processor的监控指标 14 }
代码很简单,基本上就是调用 ConcurrentHashMap 的 putIfAbsent 和 remove 方法分别实现增加和移除线程。每当 Broker 启动时,它都会调用 addProcessor 方法,向 RequestChannel 对象添加 num.network.threads 个 Processor 线程。如果查询 Kafka 官方文档的话,你就会发现,num.network.threads 这个参数的更新模式(Update Mode)是 Cluster-wide。这就说明,Kafka 允许你动态地修改此参数值。比如,Broker 启动时指定 num.network.threads 为 8,之后你通过 kafka-configs 命令将其修改为 3。显然,这个操作会减少 Processor 线程池中的线程数量。在这个场景下,removeProcessor 方法会被调用。
处理 Request 和 Response
除了 Processor 的管理之外,RequestChannel 的另一个重要功能,是处理 Request 和 Response,具体表现为收发 Request 和发送 Response。比如,收发 Request 的方法有 sendRequest 和 receiveRequest:
1 def sendRequest(request: RequestChannel.Request): Unit = { 2 requestQueue.put(request) 3 } 4 def receiveRequest(timeout: Long): RequestChannel.BaseRequest = 5 requestQueue.poll(timeout, TimeUnit.MILLISECONDS) 6 def receiveRequest(): RequestChannel.BaseRequest = 7 requestQueue.take()
所谓的发送 Request,仅仅是将 Request 对象放置在 Request 队列中而已,而接收 Request 则是从队列中取出 Request。整个流程构成了一个迷你版的“生产者 - 消费者”模式,然后依靠 ArrayBlockingQueue 的线程安全性来确保整个过程的线程安全。
对于 Response 而言,则没有所谓的接收 Response,只有发送 Response,即 sendResponse 方法。sendResponse 是啥意思呢?其实就是把 Response 对象发送出去,也就是将 Response 添加到 Response 队列的过程。
kafka使用NIO通信
在深入学习 Kafka 各个网络组件之前,我们先从整体上看一下完整的网络通信层架构,如下图所示:
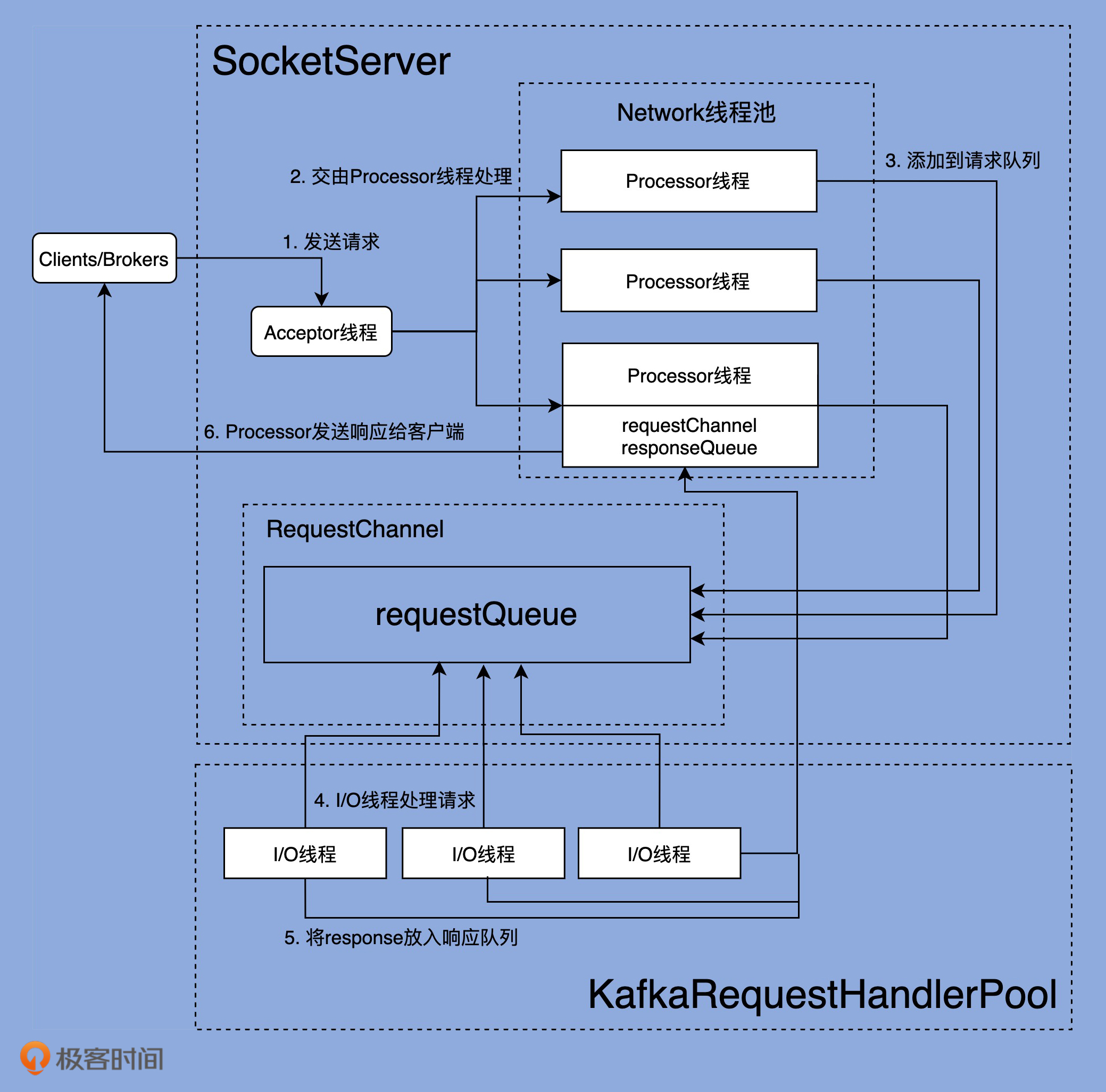
可以看出,Kafka 网络通信组件主要由两大部分构成:SocketServer 和 KafkaRequestHandlerPool。SocketServer 组件是核心,主要实现了 Reactor 模式,用于处理外部多个 Clients(这里的 Clients 指的是广义的 Clients,可能包含 Producer、Consumer 或其他 Broker)的并发请求,并负责将处理结果封装进 Response 中,返还给 Clients。KafkaRequestHandlerPool 组件就是我们常说的 I/O 线程池,里面定义了若干个 I/O 线程,用于执行真实的请求处理逻辑。两者的交互点在于 SocketServer 中定义的 RequestChannel 对象和 Processor 线程。对了,我所说的线程,在代码中本质上都是 Runnable 类型,不管是 Acceptor 类、Processor 类。
我们要重点关注一下 SocketServer 组件。这个组件是 Kafka 网络通信层中最重要的子模块。它下辖的 Acceptor 线程、Processor 线程和 RequestChannel 等对象,都是实施网络通信的重要组成部分。现在讲解一下最重要的部分。Acceptor 线程、Processor 线程。
Acceptor 线程
经典的 Reactor 模式有个 Dispatcher 的角色,接收外部请求并分发给下面的实际处理线程。在 Kafka 中,这个 Dispatcher 就是 Acceptor 线程。
Acceptor 线程接收 5 个参数,其中比较重要的有 3 个。
endPoint。它就是你定义的 Kafka Broker 连接信息,比如 PLAINTEXT://localhost:9092。Acceptor 需要用到 endPoint 包含的主机名和端口信息创建 Server Socket。
sendBufferSize。它设置的是 SocketOptions 的 SO_SNDBUF,即用于设置出站(Outbound)网络 I/O 的底层缓冲区大小。该值默认是 Broker 端参数 socket.send.buffer.bytes 的值,即 100KB。
recvBufferSize。它设置的是 SocketOptions 的 SO_RCVBUF,即用于设置入站(Inbound)网络 I/O 的底层缓冲区大小。该值默认是 Broker 端参数 socket.receive.buffer.bytes 的值,即 100KB。
如果在你的生产环境中,Clients 与 Broker 的通信网络延迟很大(比如 RTT>10ms),那么我建议你调大控制缓冲区大小的两个参数,也就是 sendBufferSize 和 recvBufferSize。通常来说,默认值 100KB 太小了。
除了类定义的字段,Acceptor 线程还有两个非常关键的自定义属性。
nioSelector:是 Java NIO 库的 Selector 对象实例,也是后续所有网络通信组件实现 Java NIO 机制的基础。
processors:网络 Processor 线程池。Acceptor 线程在初始化时,需要创建对应的网络 Processor 线程池。可见,Processor 线程是在 Acceptor 线程中管理和维护的。
Acceptor 类逻辑的重头戏其实是 run 方法,它是处理 Reactor 模式中分发逻辑的主要实现方法。下面我使用注释的方式给出 run 方法的大体运行逻辑,如下所示:
1 def run(): Unit = { 2 //注册OP_ACCEPT事件 3 serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT) 4 // 等待Acceptor线程启动完成 5 startupComplete() 6 try { 7 // 当前使用的Processor序号,从0开始,最大值是num.network.threads - 1 8 var currentProcessorIndex = 0 9 while (isRunning) { 10 try { 11 // 每500毫秒获取一次就绪I/O事件 12 val ready = nioSelector.select(500) 13 if (ready > 0) { // 如果有I/O事件准备就绪 14 val keys = nioSelector.selectedKeys() 15 val iter = keys.iterator() 16 while (iter.hasNext && isRunning) { 17 try { 18 val key = iter.next 19 iter.remove() 20 if (key.isAcceptable) { 21 // 调用accept方法创建Socket连接 22 accept(key).foreach { socketChannel => 23 var retriesLeft = synchronized(processors.length) 24 var processor: Processor = null 25 do { 26 retriesLeft -= 1 27 // 指定由哪个Processor线程进行处理 28 processor = synchronized { 29 currentProcessorIndex = currentProcessorIndex % processors.length 30 processors(currentProcessorIndex) 31 } 32 // 更新Processor线程序号 33 currentProcessorIndex += 1 34 } while (!assignNewConnection(socketChannel, processor, retriesLeft == 0)) // Processor是否接受了该连接 35 } 36 } else 37 throw new IllegalStateException("Unrecognized key state for acceptor thread.") 38 } catch { 39 case e: Throwable => error("Error while accepting connection", e) 40 } 41 } 42 } 43 } 44 catch { 45 case e: ControlThrowable => throw e 46 case e: Throwable => error("Error occurred", e) 47 } 48 } 49 } finally { // 执行各种资源关闭逻辑 50 debug("Closing server socket and selector.") 51 CoreUtils.swallow(serverChannel.close(), this, Level.ERROR) 52 CoreUtils.swallow(nioSelector.close(), this, Level.ERROR) 53 shutdownComplete() 54 } 55 }
基本上,Acceptor 线程使用 Java NIO 的 Selector + SocketChannel 的方式循环地轮询准备就绪的 I/O 事件。这里的 I/O 事件,主要是指网络连接创建事件,即代码中的 SelectionKey.OP_ACCEPT。一旦接收到外部连接请求,Acceptor 就会指定一个 Processor 线程,并将该请求交由它,让它创建真正的网络连接。
Processor 线程
如果说 Acceptor 是做入站连接处理的,那么,Processor 代码则是真正创建连接以及分发请求的地方。显然,它要做的事情远比 Acceptor 要多得多。processor线程的run方法如下:
1 override def run(): Unit = { 2 startupComplete() // 等待Processor线程启动完成 3 try { 4 while (isRunning) { 5 try { 6 configureNewConnections() // 创建新连接 7 // register any new responses for writing 8 processNewResponses() // 发送Response,并将Response放入到inflightResponses临时队列 9 poll() // 执行NIO poll,获取对应SocketChannel上准备就绪的I/O操作 10 processCompletedReceives() // 将接收到的Request放入Request队列 11 processCompletedSends() // 为临时Response队列中的Response执行回调逻辑 12 processDisconnected() // 处理因发送失败而导致的连接断开 13 closeExcessConnections() // 关闭超过配额限制部分的连接 14 } catch { 15 case e: Throwable => processException("Processor got uncaught exception.", e) 16 } 17 } 18 } finally { // 关闭底层资源 19 debug(s"Closing selector - processor $id") 20 CoreUtils.swallow(closeAll(), this, Level.ERROR) 21 shutdownComplete() 22 } 23 }
每个 Processor 线程在创建时都会创建 3 个队列。注意,这里的队列是广义的队列,其底层使用的数据结构可能是阻塞队列,也可能是一个 Map 对象而已,如下所示:
1 private val newConnections = new ArrayBlockingQueue[SocketChannel](connectionQueueSize) 2 private val inflightResponses = mutable.Map[String, RequestChannel.Response]() 3 private val responseQueue = new LinkedBlockingDeque[RequestChannel.Response]()
队列一:newConnections
它保存的是要创建的新连接信息,具体来说,就是 SocketChannel 对象。这是一个默认上限是 20 的队列,而且,目前代码中硬编码了队列的长度,因此,你无法变更这个队列的长度。每当 Processor 线程接收新的连接请求时,都会将对应的 SocketChannel 放入这个队列。后面在创建连接时(也就是调用 configureNewConnections 时),就从该队列中取出 SocketChannel,然后注册新的连接。
队列二:inflightResponses
严格来说,这是一个临时 Response 队列。当 Processor 线程将 Response 返还给 Request 发送方之后,还要将 Response 放入这个临时队列。为什么需要这个临时队列呢?这是因为,有些 Response 回调逻辑要在 Response 被发送回发送方之后,才能执行,因此需要暂存在一个临时队列里面。这就是 inflightResponses 存在的意义。
队列三:responseQueue
看名字我们就可以知道,这是 Response 队列,而不是 Request 队列。这告诉了我们一个事实:每个 Processor 线程都会维护自己的 Response 队列,而不是像网上的某些文章说的,Response 队列是线程共享的或是保存在 RequestChannel 中的。Response 队列里面保存着需要被返还给发送方的所有 Response 对象。
请求要分优先级
在阅读 SocketServer 代码、深入学习请求优先级实现机制之前,我们要先掌握一些基本概念,这是我们理解后面内容的基础。
1.Data plane 和 Control plane社区将 Kafka 请求类型划分为两大类:数据类请求和控制类请求。Data plane 和 Control plane 的字面意思是数据面和控制面,各自对应数据类请求和控制类请求,也就是说 Data plane 负责处理数据类请求,Control plane 负责处理控制类请求。目前,Controller 与 Broker 交互的请求类型有 3 种:LeaderAndIsrRequest、StopReplicaRequest 和 UpdateMetadataRequest。这 3 类请求属于控制类请求,通常应该被赋予高优先级。像我们熟知的 PRODUCE 和 FETCH 请求,就是典型的数据类请求。对这两大类请求区分处理,是 SocketServer 源码实现的核心逻辑。
2. 监听器(Listener)目前,源码区分数据类请求和控制类请求不同处理方式的主要途径,就是通过监听器。也就是说,创建多组监听器分别来执行数据类和控制类请求的处理代码。在 Kafka 中,Broker 端参数 listeners 和 advertised.listeners 就是用来配置监听器的。在源码中,监听器使用 EndPoint 类来定义。
每个 EndPoint 对象定义了 4 个属性,我们分别来看下。
host:Broker 主机名。
port:Broker 端口号。
listenerName:监听器名字。目前预定义的名称包括 PLAINTEXT、SSL、SASL_PLAINTEXT 和 SASL_SSL。Kafka 允许你自定义其他监听器名称,比如 CONTROLLER、INTERNAL 等。
securityProtocol:监听器使用的安全协议。Kafka 支持 4 种安全协议,分别是 PLAINTEXT、SSL、SASL_PLAINTEXT 和 SASL_SSL。
这里简单提一下,Broker 端参数 listener.security.protocol.map 用于指定不同名字的监听器都使用哪种安全协议。我举个例子,如果 Broker 端相应参数配置如下:
1 listener.security.protocol.map=CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:SSL 2 listeners=CONTROLLER://192.1.1.8:9091,INTERNAL://192.1.1.8:9092,EXTERNAL://10.1.1.5:9093
那么,这就表示,Kafka 配置了 3 套监听器,名字分别是 CONTROLLER、INTERNAL 和 EXTERNAL,使用的安全协议分别是 PLAINTEXT、PLAINTEXT 和 SSL。有了这些基础知识,接下来,我们就可以看一下 SocketServer 是如何实现 Data plane 与 Control plane 的分离的。当然,在此之前,我们要先了解下 SocketServer 的定义。
Data plane 和 Control plane 注释下面分别定义了一组变量,即 Processor 线程池、Acceptor 线程池和 RequestChannel 实例。
创建 Data plane 所需资源
SocketServer 的 createDataPlaneAcceptorsAndProcessors 方法负责为 Data plane 创建所需资源。我们看下它的实现:
1 private def createDataPlaneAcceptorsAndProcessors( 2 dataProcessorsPerListener: Int, endpoints: Seq[EndPoint]): Unit = { 3 // 遍历监听器集合 4 endpoints.foreach { endpoint => 5 // 将监听器纳入到连接配额管理之下 6 connectionQuotas.addListener(config, endpoint.listenerName) 7 // 为监听器创建对应的Acceptor线程 8 val dataPlaneAcceptor = createAcceptor(endpoint, DataPlaneMetricPrefix) 9 // 为监听器创建多个Processor线程。具体数目由num.network.threads决定 10 addDataPlaneProcessors(dataPlaneAcceptor, endpoint, dataProcessorsPerListener) 11 // 将<监听器,Acceptor线程>对保存起来统一管理 12 dataPlaneAcceptors.put(endpoint, dataPlaneAcceptor) 13 info(s"Created data-plane acceptor and processors for endpoint : ${endpoint.listenerName}") 14 } 15 }
createDataPlaneAcceptorsAndProcessors 方法会遍历你配置的所有监听器,然后为每个监听器执行下面的逻辑。
初始化该监听器对应的最大连接数计数器。后续这些计数器将被用来确保没有配额超限的情形发生。
为该监听器创建 Acceptor 线程,也就是调用 Acceptor 类的构造函数,生成对应的 Acceptor 线程实例。
创建 Processor 线程池。对于 Data plane 而言,线程池的数量由 Broker 端参数 num.network.threads 决定。
将 < 监听器,Acceptor 线程 > 对加入到 Acceptor 线程池统一管理。
创建 Control plane 所需资源
前面说过了,基于控制类请求的负载远远小于数据类请求负载的假设,Control plane 的配套资源只有 1 个 Acceptor 线程 + 1 个 Processor 线程 + 1 个深度是 20 的请求队列而已。和 Data plane 相比,这些配置稍显寒酸,不过在大部分情况下,应该是够用了。SocketServer 提供了 createControlPlaneAcceptorAndProcessor 方法,用于为 Control plane 创建所需资源,源码如下:
1 private def createControlPlaneAcceptorAndProcessor( 2 endpointOpt: Option[EndPoint]): Unit = { 3 // 如果为Control plane配置了监听器 4 endpointOpt.foreach { endpoint => 5 // 将监听器纳入到连接配额管理之下 6 connectionQuotas.addListener(config, endpoint.listenerName) 7 // 为监听器创建对应的Acceptor线程 8 val controlPlaneAcceptor = createAcceptor(endpoint, ControlPlaneMetricPrefix) 9 // 为监听器创建对应的Processor线程 10 val controlPlaneProcessor = newProcessor(nextProcessorId, controlPlaneRequestChannelOpt.get, connectionQuotas, endpoint.listenerName, endpoint.securityProtocol, memoryPool) 11 controlPlaneAcceptorOpt = Some(controlPlaneAcceptor) 12 controlPlaneProcessorOpt = Some(controlPlaneProcessor) 13 val listenerProcessors = new ArrayBuffer[Processor]() 14 listenerProcessors += controlPlaneProcessor 15 // 将Processor线程添加到控制类请求专属RequestChannel中 16 // 即添加到RequestChannel实例保存的Processor线程池中 17 controlPlaneRequestChannelOpt.foreach( 18 _.addProcessor(controlPlaneProcessor)) 19 nextProcessorId += 1 20 // 把Processor对象也添加到Acceptor线程管理的Processor线程池中 21 controlPlaneAcceptor.addProcessors(listenerProcessors, ControlPlaneThreadPrefix) 22 info(s"Created control-plane acceptor and processor for endpoint : ${endpoint.listenerName}") 23 } 24 }
总体流程和 createDataPlaneAcceptorsAndProcessors 非常类似,只是方法开头需要判断是否配置了用于 Control plane 的监听器。目前,Kafka 规定只能有 1 套监听器用于 Control plane,而不能像 Data plane 那样可以配置多套监听器。如果认真看的话,你会发现,上面两张图中都没有提到启动 Acceptor 和 Processor 线程。那这些线程到底是在什么时候启动呢?实际上,Processor 和 Acceptor 线程是在启动 SocketServer 组件之后启动的,具体代码在 KafkaServer.scala 文件的 startup 方法中,如下所示:
1 // KafkaServer.scala 2 def startup(): Unit = { 3 try { 4 info("starting") 5 ...... 6 // 创建SocketServer组件 7 socketServer = new SocketServer(config, metrics, time, credentialProvider) 8 // 启动SocketServer,但不启动Processor线程 9 socketServer.startup(startProcessingRequests = false) 10 ...... 11 // 启动Data plane和Control plane的所有线程 12 socketServer.startProcessingRequests(authorizerFutures) 13 ...... 14 } catch { 15 ...... 16 } 17 }
1 def startProcessingRequests(authorizerFutures: Map[Endpoint, CompletableFuture[Void]] = Map.empty): Unit = { 2 info("Starting socket server acceptors and processors") 3 this.synchronized { 4 if (!startedProcessingRequests) { 5 // 启动处理控制类请求的Processor和Acceptor线程 6 startControlPlaneProcessorAndAcceptor(authorizerFutures) 7 // 启动处理数据类请求的Processor和Acceptor线程 8 startDataPlaneProcessorsAndAcceptors(authorizerFutures) 9 startedProcessingRequests = true 10 } else { 11 info("Socket server acceptors and processors already started") 12 } 13 } 14 info("Started socket server acceptors and processors") 15 }
请求处理全流程
要知道,Kafka 官网可没有告诉我们,什么是网络线程和 I/O 线程。如果不明白“请求是被网络线程接收并放入请求队列的”这件事,我们就很可能犯这样的错误——当请求队列快满了的时候,我们会以为是网络线程处理能力不够,进而盲目地增加 num.network.threads 值,但最终效果很可能是适得其反的。我相信,在今天的课程结束之后,你就会知道,碰到这种情况的时候,我们更应该增加的是 num.io.threads 的值。num.io.threads 参数表征的就是 I/O 线程池的大小。所谓的 I/O 线程池,即 KafkaRequestHandlerPool,也称请求处理线程池。这节课我会先讲解 KafkaRequestHandlerPool 源码,再具体解析请求处理全流程的代码。
KafkaRequestHandlerPool
KafkaRequestHandlerPool 是真正处理 Kafka 请求的地方。切记,Kafka 中处理请求的类不是 SocketServer,也不是 RequestChannel,而是 KafkaRequestHandlerPool。
1 // 关键字段说明 2 // id: I/O线程序号 3 // brokerId:所在Broker序号,即broker.id值 4 // totalHandlerThreads:I/O线程池大小 5 // requestChannel:请求处理通道 6 // apis:KafkaApis类,用于真正实现请求处理逻辑的类 7 class KafkaRequestHandler( 8 id: Int, 9 brokerId: Int, 10 val aggregateIdleMeter: Meter, 11 val totalHandlerThreads: AtomicInteger, 12 val requestChannel: RequestChannel, 13 apis: KafkaApis, 14 time: Time) extends Runnable with Logging { 15 ...... 16 }
KafkaRequestHandler 是一个 Runnable 对象,因此,你可以把它当成是一个线程。每个 KafkaRequestHandler 实例,都有 4 个关键的属性。
id:请求处理线程的序号,类似于 Processor 线程的 ID 序号,仅仅用于标识这是线程池中的第几个线程。
brokerId:Broker 序号,用于标识这是哪个 Broker 上的请求处理线程。
requestChannel:SocketServer 中的请求通道对象。KafkaRequestHandler 对象为什么要定义这个字段呢?我们说过,它是负责处理请求的类,那请求保存在什么地方呢?实际上,请求恰恰是保存在 RequestChannel 中的请求队列中,因此,Kafka 在构造 KafkaRequestHandler 实例时,必须关联 SocketServer 组件中的 RequestChannel 实例,也就是说,要让 I/O 线程能够找到请求被保存的地方。
apis:这是一个 KafkaApis 类。如果说 KafkaRequestHandler 是真正处理请求的,那么,KafkaApis 类就是真正执行请求处理逻辑的地方。在第 10 节课,我会具体讲解 KafkaApis 的代码。目前,你需要知道的是,它有个 handle 方法,用于执行请求处理逻辑。
run 方法的主要运行逻辑。它的所有执行逻辑都在 while 循环之下,因此,只要标志线程关闭状态的 stopped 为 false,run 方法将一直循环执行 while 下的语句。第 1 步是从请求队列中获取下一个待处理的请求,同时更新一些相关的统计指标。如果本次循环没取到,那么本轮循环结束,进入到下一轮。如果是 ShutdownRequest 请求,则说明该 Broker 发起了关闭操作。而 Broker 关闭时会调用 KafkaRequestHandler 的 shutdown 方法,进而调用 initiateShutdown 方法,以及 RequestChannel 的 sendShutdownRequest 方法,而后者就是将 ShutdownRequest 写入到请求队列。一旦从请求队列中获取到 ShutdownRequest,run 方法代码会调用 shutdownComplete 的 countDown 方法,正式完成对 KafkaRequestHandler 线程的关闭操作。你看看 KafkaRequestHandlerPool 的 shutdown 方法代码,就能明白这是怎么回事了。
1 def shutdown(): Unit = synchronized { 2 info("shutting down") 3 for (handler <- runnables) 4 handler.initiateShutdown() // 调用initiateShutdown方法发起关闭 5 for (handler <- runnables) 6 // 调用awaitShutdown方法等待关闭完成 7 // run方法一旦调用countDown方法,这里将解除等待状态 8 handler.awaitShutdown() 9 info("shut down completely") 10 }
KafkaRequestHandlerPool从上面的分析来看,KafkaRequestHandler 逻辑大体上还是比较简单的。下面我们来看下 KafkaRequestHandlerPool 线程池的实现。它是管理 I/O 线程池的,实现逻辑也不复杂。它的 shutdown 方法前面我讲过了,这里我们重点学习下,它是如何创建这些线程的,以及创建它们的时机。首先看它的定义:
1 // 关键字段说明 2 // brokerId:所属Broker的序号,即broker.id值 3 // requestChannel:SocketServer组件下的RequestChannel对象 4 // api:KafkaApis类,实际请求处理逻辑类 5 // numThreads:I/O线程池初始大小 6 class KafkaRequestHandlerPool( 7 val brokerId: Int, 8 val requestChannel: RequestChannel, 9 val apis: KafkaApis, 10 time: Time, 11 numThreads: Int, 12 requestHandlerAvgIdleMetricName: String, 13 logAndThreadNamePrefix : String) 14 extends Logging with KafkaMetricsGroup { 15 // I/O线程池大小 16 private val threadPoolSize: AtomicInteger = new AtomicInteger(numThreads) 17 // I/O线程池 18 val runnables = new mutable.ArrayBuffer[KafkaRequestHandler](numThreads) 19 ...... 20 }
KafkaRequestHandlerPool 对象定义了 7 个属性,其中比较关键的有 4 个,我分别来解释下。
brokerId:和 KafkaRequestHandler 中的一样,保存 Broker 的序号。
requestChannel:SocketServer 的请求处理通道,它下辖的请求队列为所有 I/O 线程所共享。requestChannel 字段也是 KafkaRequestHandler 类的一个重要属性。
apis:KafkaApis 实例,执行实际的请求处理逻辑。它同时也是 KafkaRequestHandler 类的一个重要属性。
numThreads:线程池中的初始线程数量。它是 Broker 端参数 num.io.threads 的值。目前,Kafka 支持动态修改 I/O 线程池的大小,因此,这里的 numThreads 是初始线程数,调整后的 I/O 线程池的实际大小可以和 numThreads 不一致。
全处理流程
比较熟悉的图形如下图:
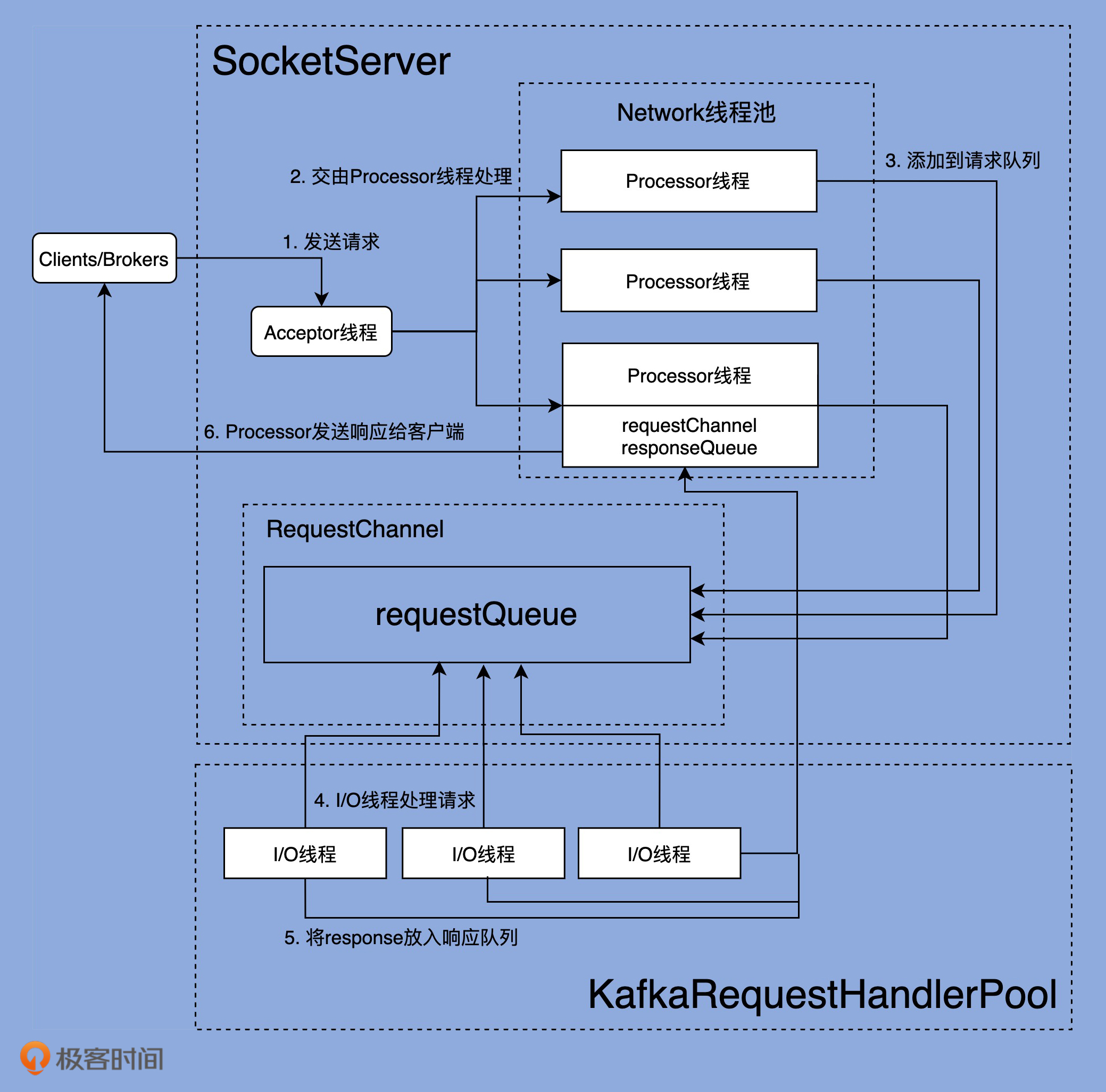
第 1 步:Clients 或其他 Broker 发送请求给 Acceptor 线程我在第 7 节课讲过,Acceptor 线程实时接收来自外部的发送请求。一旦接收到了之后,就会创建对应的 Socket 通道。可以看到,Acceptor 线程通过调用 accept 方法,创建对应的 SocketChannel,然后将该 Channel 实例传给 assignNewConnection 方法,等待 Processor 线程将该 Socket 连接请求,放入到它维护的待处理连接队列中。后续 Processor 线程的 run 方法会不断地从该队列中取出这些 Socket 连接请求,然后创建对应的 Socket 连接。assignNewConnection 方法的主要作用是,将这个新建的 SocketChannel 对象存入 Processors 线程的 newConnections 队列中。之后,Processor 线程会不断轮询这个队列中的待处理 Channel(可以参考第 7 讲的 configureNewConnections 方法),并向这些 Channel 注册基于 Java NIO 的 Selector,用于真正的请求获取和响应发送 I/O 操作。严格来说,Acceptor 线程处理的这一步并非真正意义上的获取请求,仅仅是 Acceptor 线程为后续 Processor 线程获取请求铺路而已,也就是把需要用到的 Socket 通道创建出来,传给下面的 Processor 线程使用。
第 2 & 3 步:Processor 线程处理请求,并放入请求队列一旦 Processor 线程成功地向 SocketChannel 注册了 Selector,Clients 端或其他 Broker 端发送的请求就能通过该 SocketChannel 被获取到,具体的方法是 Processor 的 processCompleteReceives。因为代码很多,我进行了精简,只保留了最关键的逻辑。该方法会将 Selector 获取到的所有 Receive 对象转换成对应的 Request 对象,然后将这些 Request 实例放置到请求队列中,就像上图中第 2、3 步展示的那样。所谓的 Processor 线程处理请求,就是指它从底层 I/O 获取到发送数据,将其转换成 Request 对象实例,并最终添加到请求队列的过程。
第 4 步:I/O 线程处理请求所谓的 I/O 线程,就是我们开头提到的 KafkaRequestHandler 线程,它的处理逻辑就在 KafkaRequestHandler 类的 run 方法中。
第 5 步:KafkaRequestHandler 线程将 Response 放入 Processor 线程的 Response 队列这一步的工作由 KafkaApis 类完成。当然,这依然是由 KafkaRequestHandler 线程来完成的。KafkaApis.scala 中有个 sendResponse 方法,将 Request 的处理结果 Response 发送出去。本质上,它就是调用了 RequestChannel 的 sendResponse 方法。
第 6 步:Processor 线程发送 Response 给 Request 发送方最后一步是,Processor 线程取出 Response 队列中的 Response,返还给 Request 发送方。具体代码位于 Processor 线程的 processNewResponses 方法中。
KafkaApis
KafkaApis 类的定义代码如下:
1 class KafkaApis( 2 val requestChannel: RequestChannel, // 请求通道 3 val replicaManager: ReplicaManager, // 副本管理器 4 val adminManager: AdminManager, // 主题、分区、配置等方面的管理器 5 val groupCoordinator: GroupCoordinator, // 消费者组协调器组件 6 val txnCoordinator: TransactionCoordinator, // 事务管理器组件 7 val controller: KafkaController, // 控制器组件 8 val zkClient: KafkaZkClient, // ZooKeeper客户端程序,Kafka依赖于该类实现与ZooKeeper交互 9 val brokerId: Int, // broker.id参数值 10 val config: KafkaConfig, // Kafka配置类 11 val metadataCache: MetadataCache, // 元数据缓存类 12 val metrics: Metrics, 13 val authorizer: Option[Authorizer], 14 val quotas: QuotaManagers, // 配额管理器组件 15 val fetchManager: FetchManager, 16 brokerTopicStats: BrokerTopicStats, 17 val clusterId: String, 18 time: Time, 19 val tokenManager: DelegationTokenManager) extends Logging { 20 type FetchResponseStats = Map[TopicPartition, RecordConversionStats] 21 this.logIdent = "[KafkaApi-%d] ".format(brokerId) 22 val adminZkClient = new AdminZkClient(zkClient) 23 private val alterAclsPurgatory = new DelayedFuturePurgatory(purgatoryName = "AlterAcls", brokerId = config.brokerId) 24 ...... 25 }
KafkaApis 是 Broker 端所有功能的入口,同时关联了超多的 Kafka 组件。它绝对是你学习源码的第一入口。面对庞大的源码工程,如果你不知道从何下手,那就先从 KafkaApis.scala 这个文件开始吧。
handle 方法封装了所有 RPC 请求的具体处理逻辑。每当社区新增 RPC 协议时,增加对应的 handle×××Request 方法和 case 分支都是首要的。
sendResponse 系列方法负责发送 Response 给请求发送方。发送 Response 的逻辑是将 Response 对象放置在 Processor 线程的 Response 队列中,然后交由 Processor 线程实现网络发送。
authorize 方法是请求处理前权限校验层的主要逻辑实现。你可以查看一下官方文档,了解一下当前都有哪些权限,然后对照着具体的方法,找出每类 RPC 协议都要求 Clients 端具备什么权限。
总结
以后关于kafka系列的总结大部分来自Geek Time的课件,大家可以自行关键字搜索。