- where在查询数据库结果返回之前对查询条件进行约束,就是结果返回之前起作用,而having是查询数据库,已经得到返回的结果了,再对结果进行过滤。(结果返回前,结果返回后)
- where条件不能使用聚合函数,想想也能明白因为聚合函数是已经返回的结果,having后面可以使用聚合函数;
- where后面接的必须是表中有的字段,查询结果中可以没有;但是having后面接的字段必须是返回的结果中有的,查询的表中有没有无关;(不理解这句话可以参考:原文)
- 使用where子句,可以对条件中用到的字段创建索引,提高查询效率。
-
当在Where子句和Having子句中都可以使用的条件,从语句的执行效率来看,最好使用Where子句。
在使用Count函数等对表中的数据进行聚合操作时,DBMS内部会进行排序处理,而排序操作会增加机器的负担,减少排序的行数,可以增加处理速度。
使用Where子句指定条件时,由于排序之前就对数据进行了过滤,所以能够减少排序的数据量。但是Having子句是在排序之后才对数据进行分组的,因此与前者相比,需要排序的数据量就要多得多。
- 做了一个测试,建了一个学生分数表。
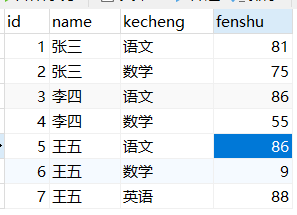
然后查询所有科目都大于80分的学生姓名,我先用的这条语句:select name,fenshu from stu group by name having fenshu > 80; 查询结果如图:
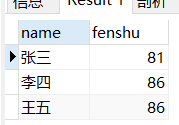
和预期结果不一样,having是对查询出来的结果进行过滤,而且我这里还根据名字分组了,本以为having是在每个分组内逐行比较,当所有行都满足条件的时候才返回。现在看来并不是这样的,having应该是只比较每个分组内的第一条数据,如果满足条件就返回。至于分组内的其他记录不比较了。所以上面的语句执行结果返回的是三个学生都满足。我把王五的语文改成70分,数学改成90,结果是没有王五,也说明了having确实只比较分组内的第一条数据,其他的不比较。 那么正确语句是select name from stu group by name having name not in ( select name from stu where fenshu <80);
这个是查询到所有分数大于80的学生姓名。 又测试了一下select name from stu group by name having name in ( select name from stu where fenshu >80); 把not去掉,fenshu>80 结果和前两条语句都不一样,这个是只要有至少一门大于80分就可以返回。