图解Attention
Seq2Seq模型
Seq2Seq模型接受一个序列(单词、字母、图像特征),输出另一个序列。
组成
-
编码器(Encoder)
处理输入序列中的每个元素,将其转换为一个向量(上下文 context)
-
解码器(Decoder)
逐项生成输出序列中的元素
Context的长度可在编写Seq2Seq模型的时候设置,该长度基于编码器RNN的隐藏层的神经元的数量。
RNN在每个时间步接受两个输入:输入序列中的一个元素、一个隐藏层状态。
使用"word embedding"技术将单词转换到一个向量空间。它还可以捕捉到大量的语义信息。比如king - man + woman = queen。通常embedding向量的大小是200或者300。

Attention讲解
上下文向量使得该模型在处理长文本时面临非常大的挑战。通过注意力机制可以使模型可以根据需要关注到输入序列的相关部分。
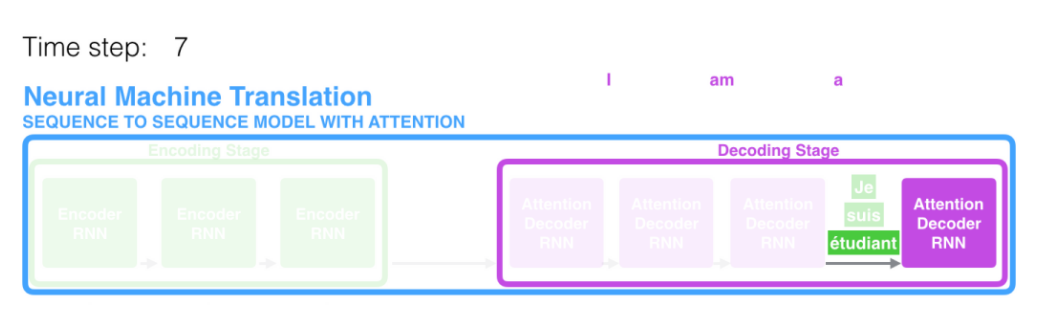
在上图执行到第七步的时候,注意力机制可以使注意力集中在“etudiant”这个词中(法语中是student的意思),从而产生更好的结果。
注意力模型于Seq2Seq模型的主要区别:
- 编码器会将所有时间步的hidden state传递给解码器,而不只是传递最后一个。
- 解码器会做额外的处理来把注意力集中在与该时间步相关的部分
- 查看所有接受到的编码器的hidden state,其中每个hidden state都对应到输入句子中的一个单词。
- 给每个hidden state一个分数
- 将每个hidden state乘以它自己的经过softmax的分数。从而放大高分、缩小低分的hidden state。
注意力模型的整个过程
- 解码器RNN的输入:一个embedding向量,一个初始化好的解码器hidden state
- 产生一个输出和新的hidden state(H4
- 使用编码器的hidden state和H4来计算该时间步的上下文(C4
- 拼接H4和C4
- 将拼接后的向量输入到前馈神经网络
- 前馈神经网络的输出表示这个时间步输出的单词
- 在下一个时间步重复步骤
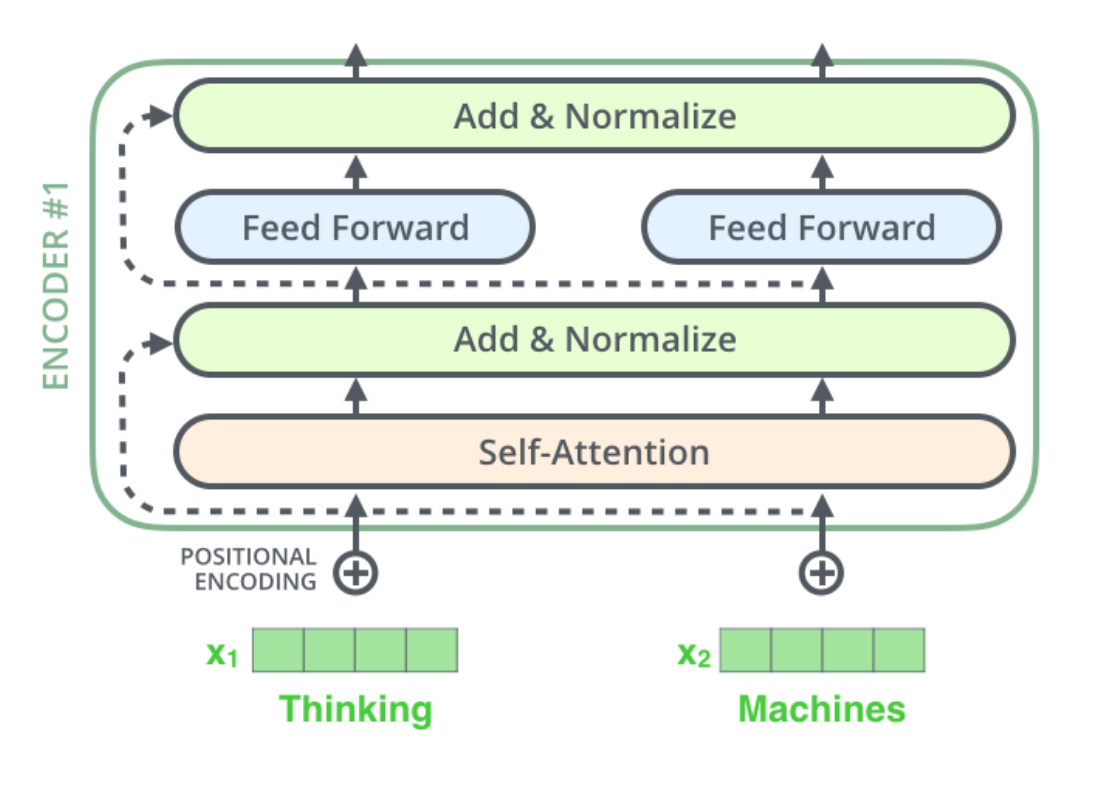
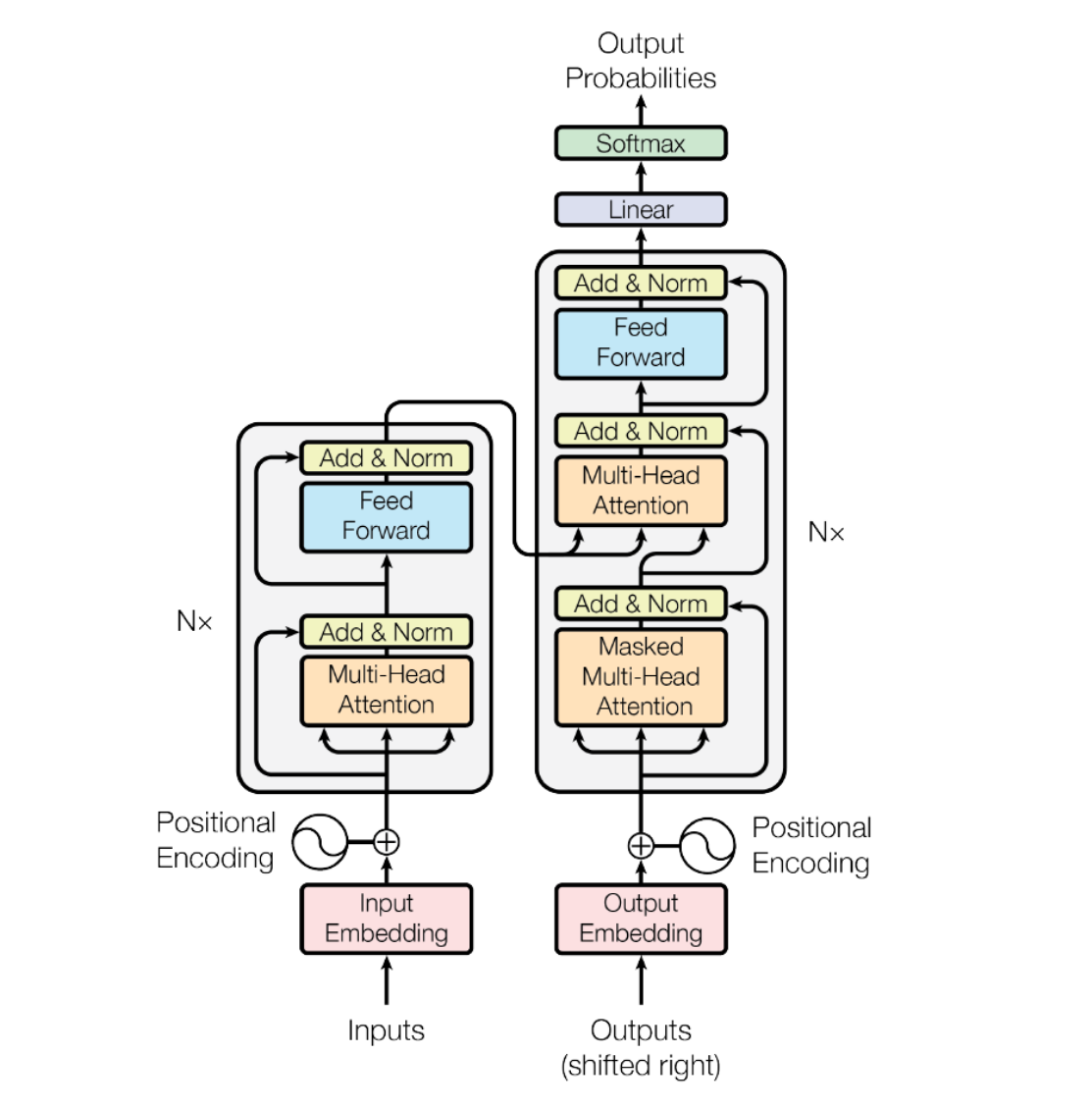
图解Transformer
在Transformer中,所有time step的数据都是经过Self Attention计算的,使得模型可以并行计算。
常用结构:Encoder和Decoder
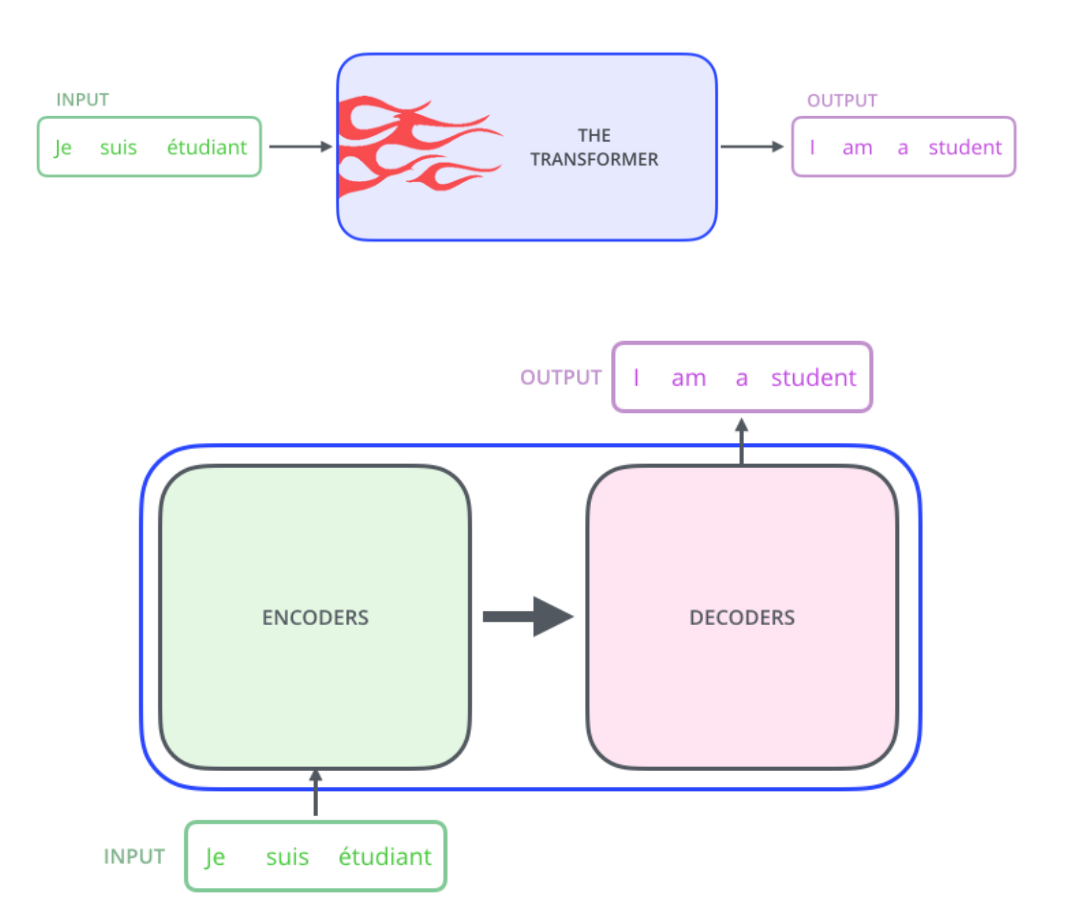
从整体宏观理解Transformer
- 编码部分
- 多层编码器
- Self-Attention Layer(处理一个词的时候还会关注该词的上下文)
- Feed Forward Neural Netword (前馈神经网络,FFNN)
- 多层编码器
- 解码部分
- 多层解码器
- 相比编码器多了一个Encoder-Decoder Attention层
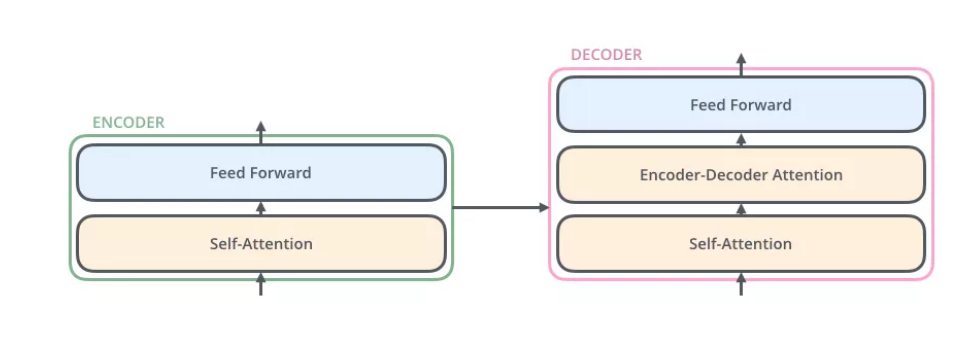
- 相比编码器多了一个Encoder-Decoder Attention层
- 多层解码器
从细节理解Transformer
Transformer的输入
首先使用词嵌入算法将每个词转换为一个词向量。实际一般向量是256或者512维。输入的句子则是一个向量列表。向量列表的长度是一个超参数,一般是训练集中句子的最大长度。不足则补0,超过则截断。
Encoder
第一个编码器接受向量列表,然后输出大小相同的向量列表
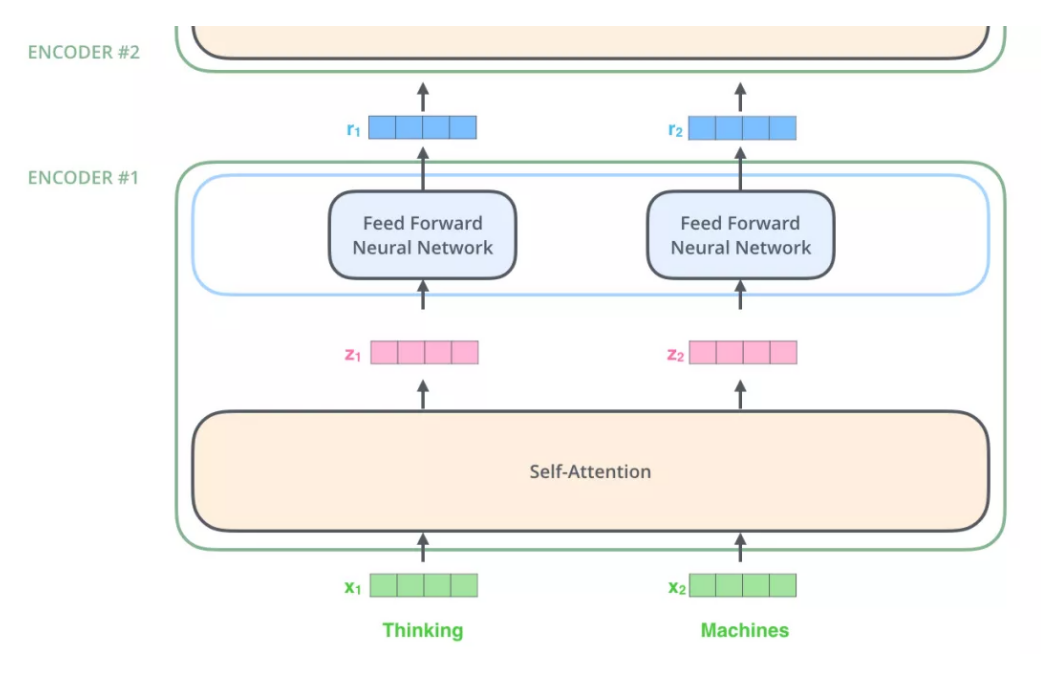
Self-Attention 整体理解
当我们翻译句子:
The animal didn't cross the street because it was too tired
算法不能轻易的分清it指的是street还是animal,但是如果有Self Attention机制就能让模型把it和animal关联起来。
Self-Attention机制可以使得模型在处理某个词的时候还能够关注到句子中其他位置的词作为辅助线索。
RNN在处理当前词的时候会参考前面传来的hidden state。

如图所示,在编码it的时候,有一部分注意力集中在“The animal”上了。
Self-Attention的细节
1.计算Query、Key、Value向量
矩阵运算使得Self Attention的计算得以并行化
第一步:对输入编码器的每个词向量都创建3个向量,Query、Key、Value向量。这三个向量是词向量分别和3个矩阵相乘得到的,而该矩阵是我们要学习的参数。
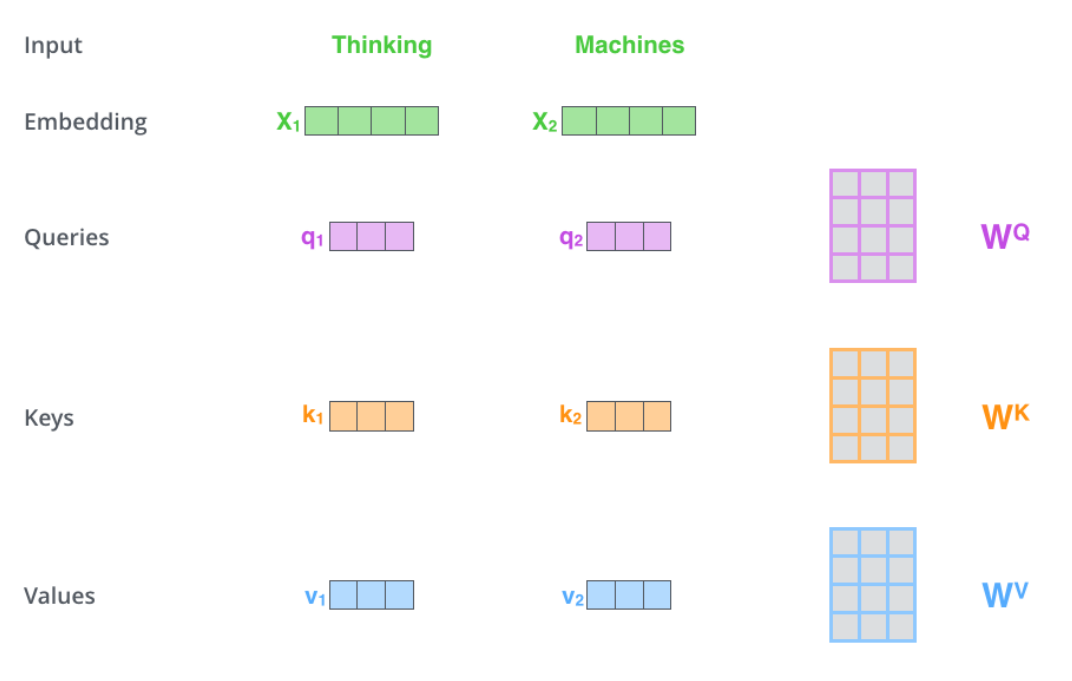
计算后的向量一般会比原来的词向量长度更小。
2.计算Attention Score(注意力分数)
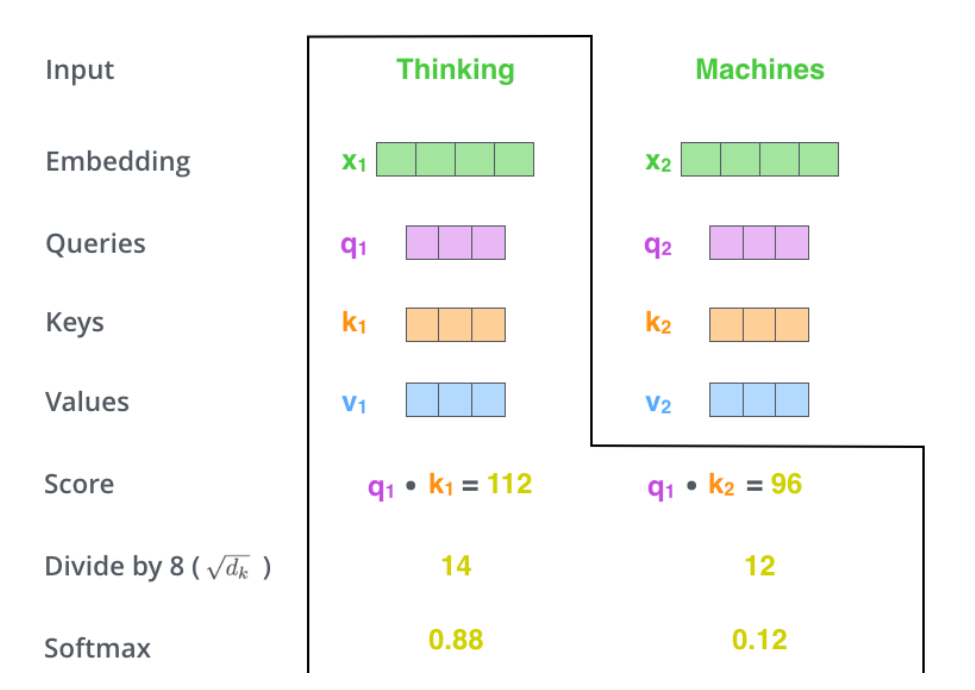
第二步:假设我们现在要计算Thinking的注意力分数,则需要根据Thinking来对句子中的每个词计算一个分数,来决定在编码Thinking的时候对句子中的其他词放置多少注意力。

分数是由该词的Query向量和其他位置的每个词的Key向量点积求得。当求与自己的注意力分数的时候则采用内积。
第三步:把每个分数除以Key向量的长度。这样在反向传播的时候求取梯度会更加稳定。
第四步:将这些分数经过一个Softmax层,可以将其归一化。
经过上面的步骤可以知道在编码某一个词的时候,对其他位置的词要放置多大的注意力。
第五步:将每个位置的分数分别与每个Value向量相乘。这样相乘之后,分数高的位置的值就更大,分数低的值就更小,得到的注意力的更低。
第六步:把上一步得到的向量相加。
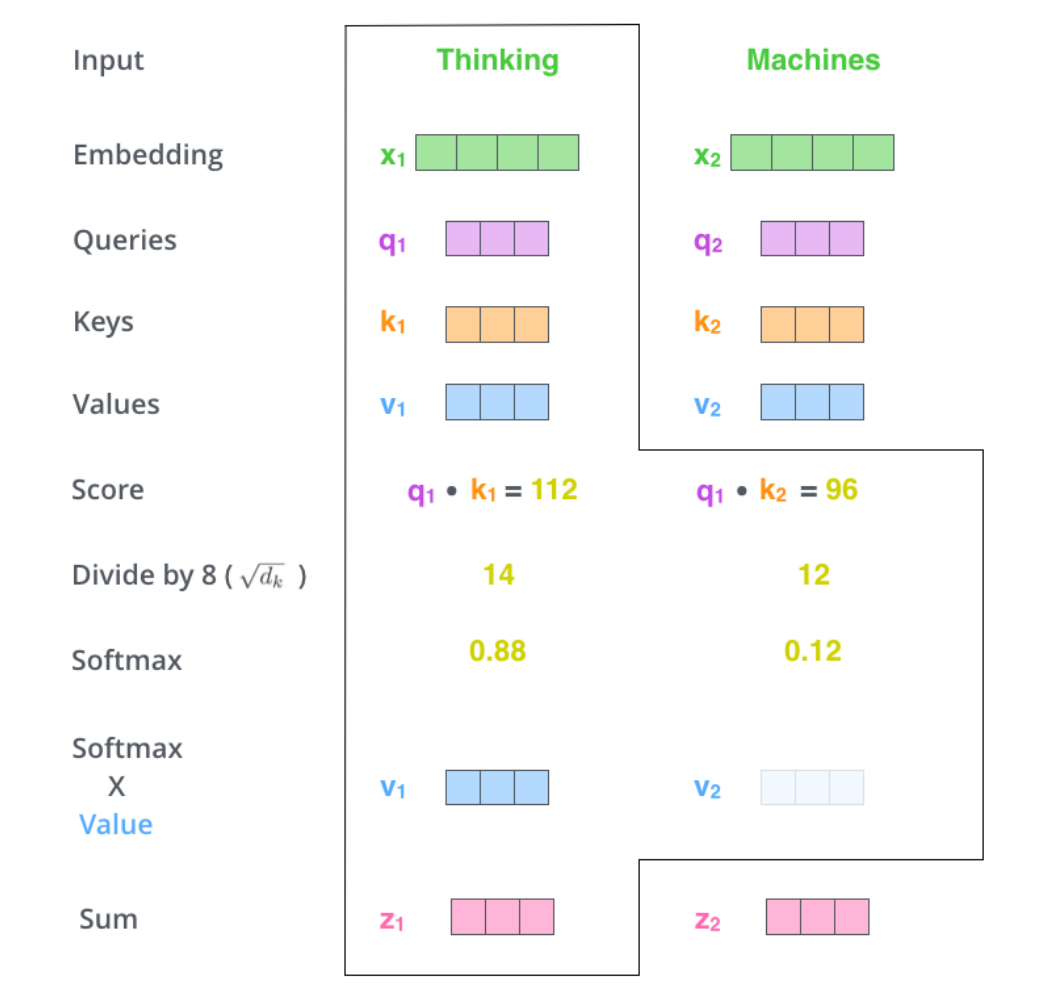
上面一次只能计算一个位置的输出向量,但在实际计算时是使用矩阵的,所以可以一次得到所有位置的输出向量。
使用矩阵计算Self-Attention
第一步:计算Query、Key、Value矩阵。
将所有词向量放入到矩阵X中,然后分别和三个权重矩阵相乘,得到Q,K,V矩阵。
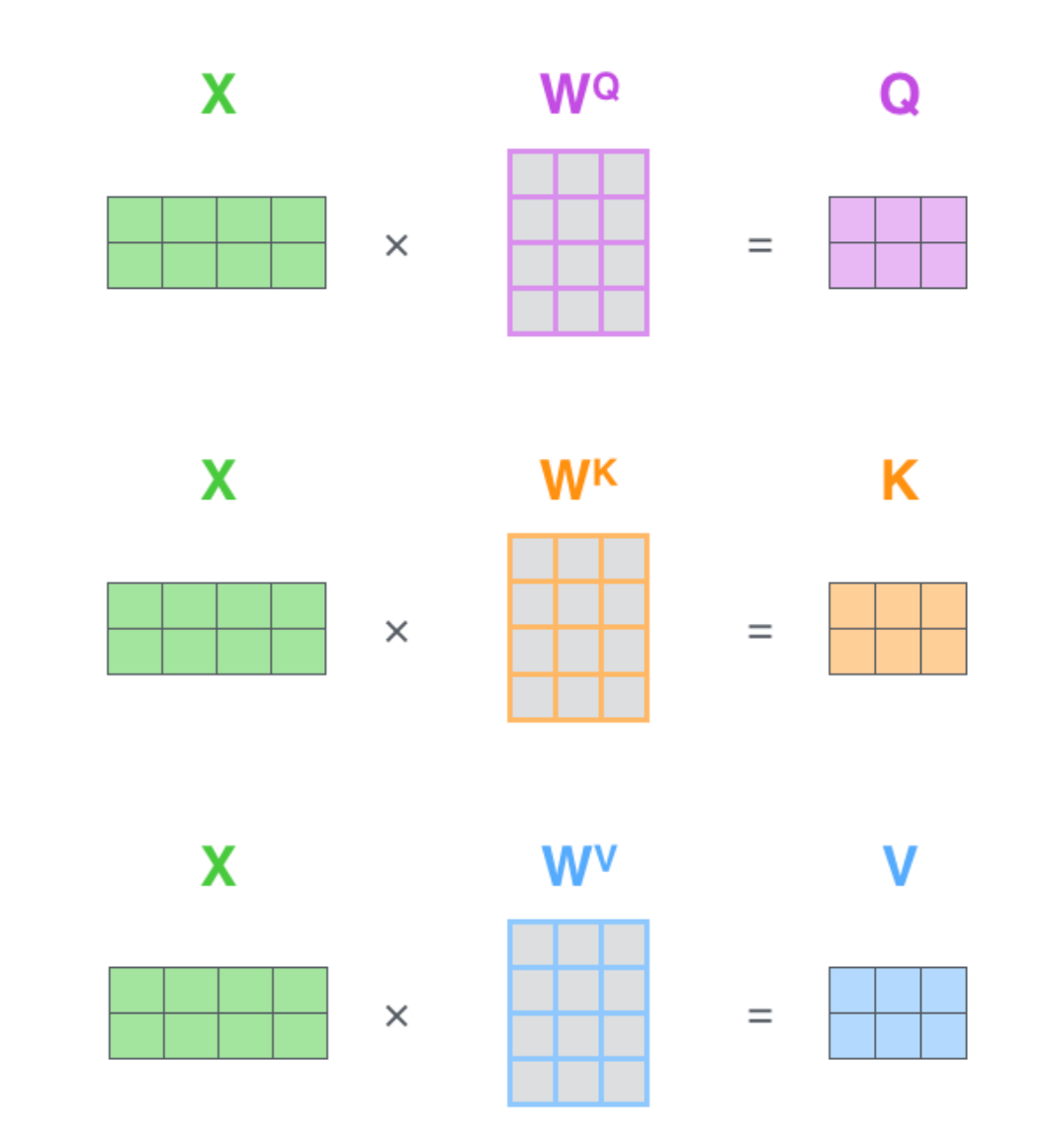
X中的每一行表示句子中的每一个词的词向量。
使用矩阵运算将上面的6步进行压缩
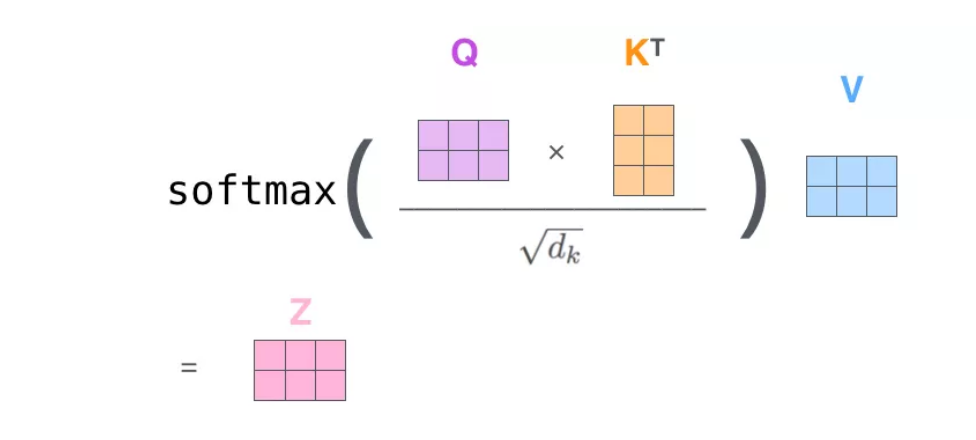
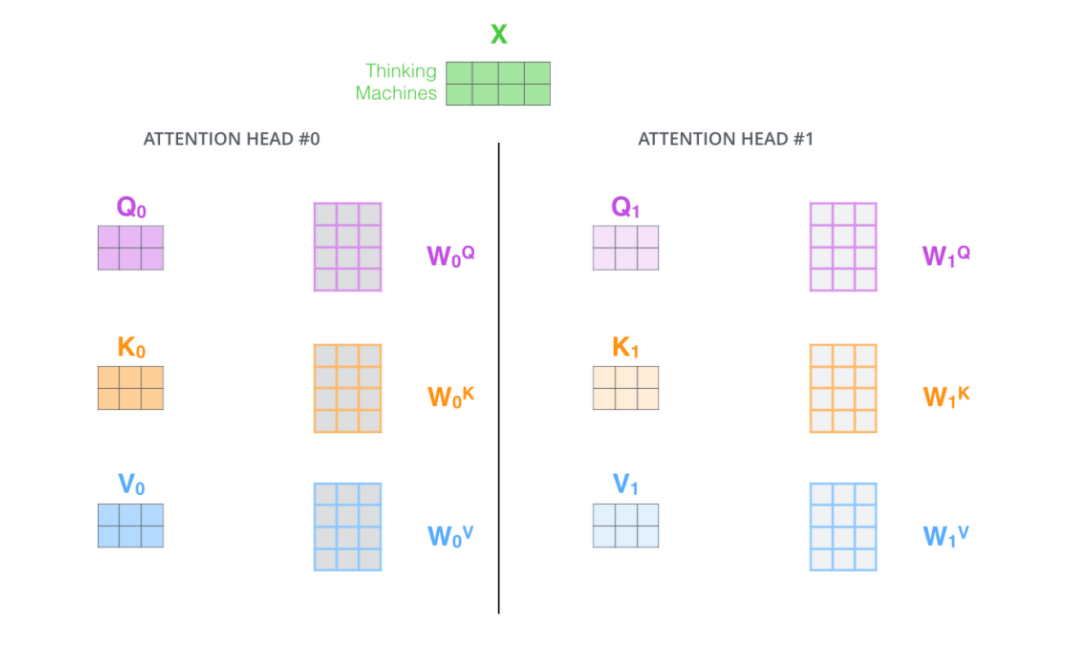
多头注意力机制(multi-head attention)
通过增加多头注意力机制可以增强Attention层的能力:
- 扩展了模型关注不同位置的能力
- 赋予attention层多个“子表示空间”。因为有多组WQ,WK,W^V权重矩阵,所以每一组可以看作把输入的向量映射到一个“子表示空间”
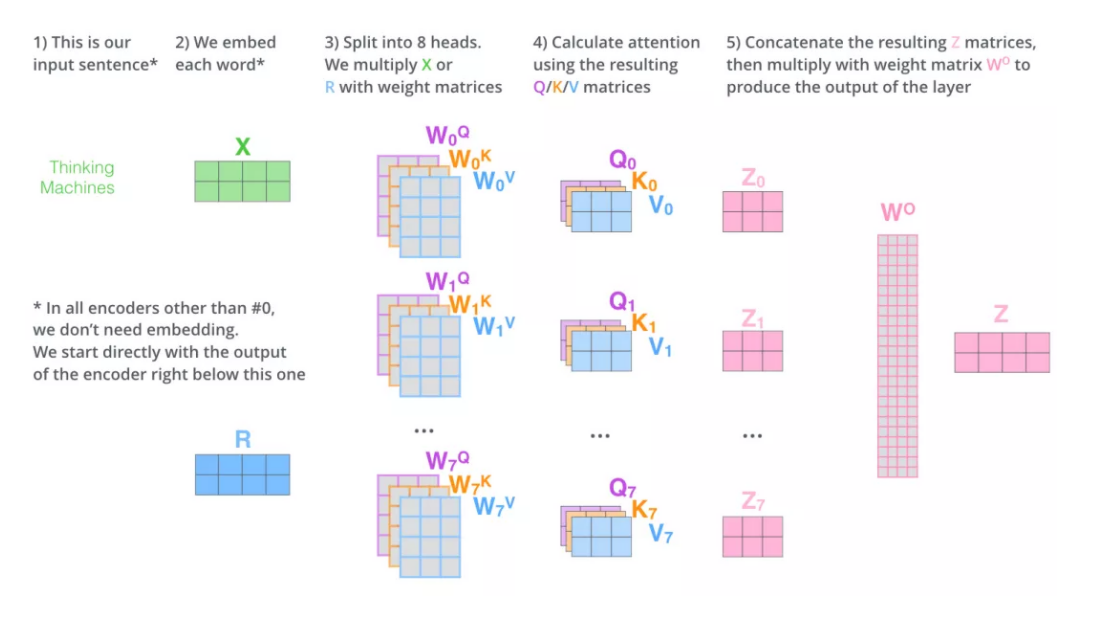
最后会得到多个Z矩阵,我们再将其整合为一个矩阵。
代码实现矩阵计算Attention
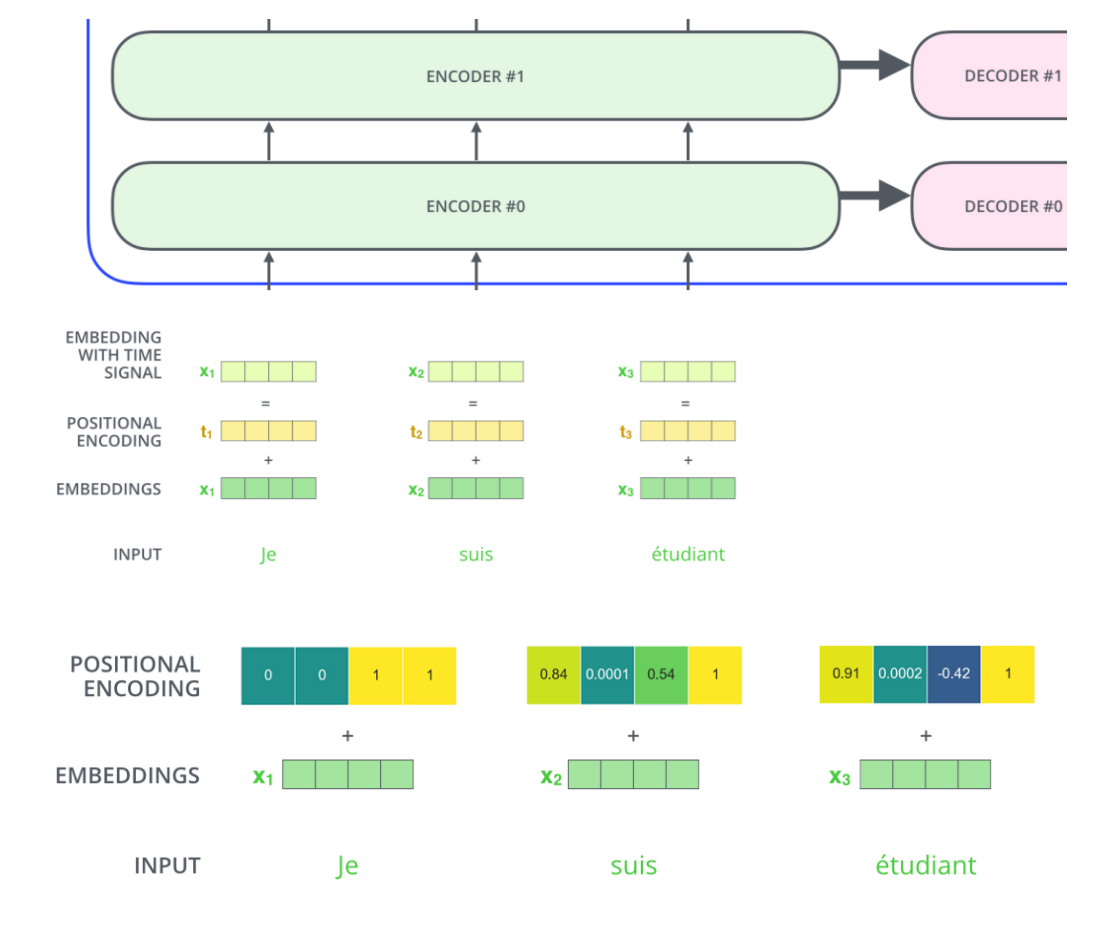
使用位置编码来表示序列的顺序
将表示位置的向量都添加到词向量中,得到新的向量。
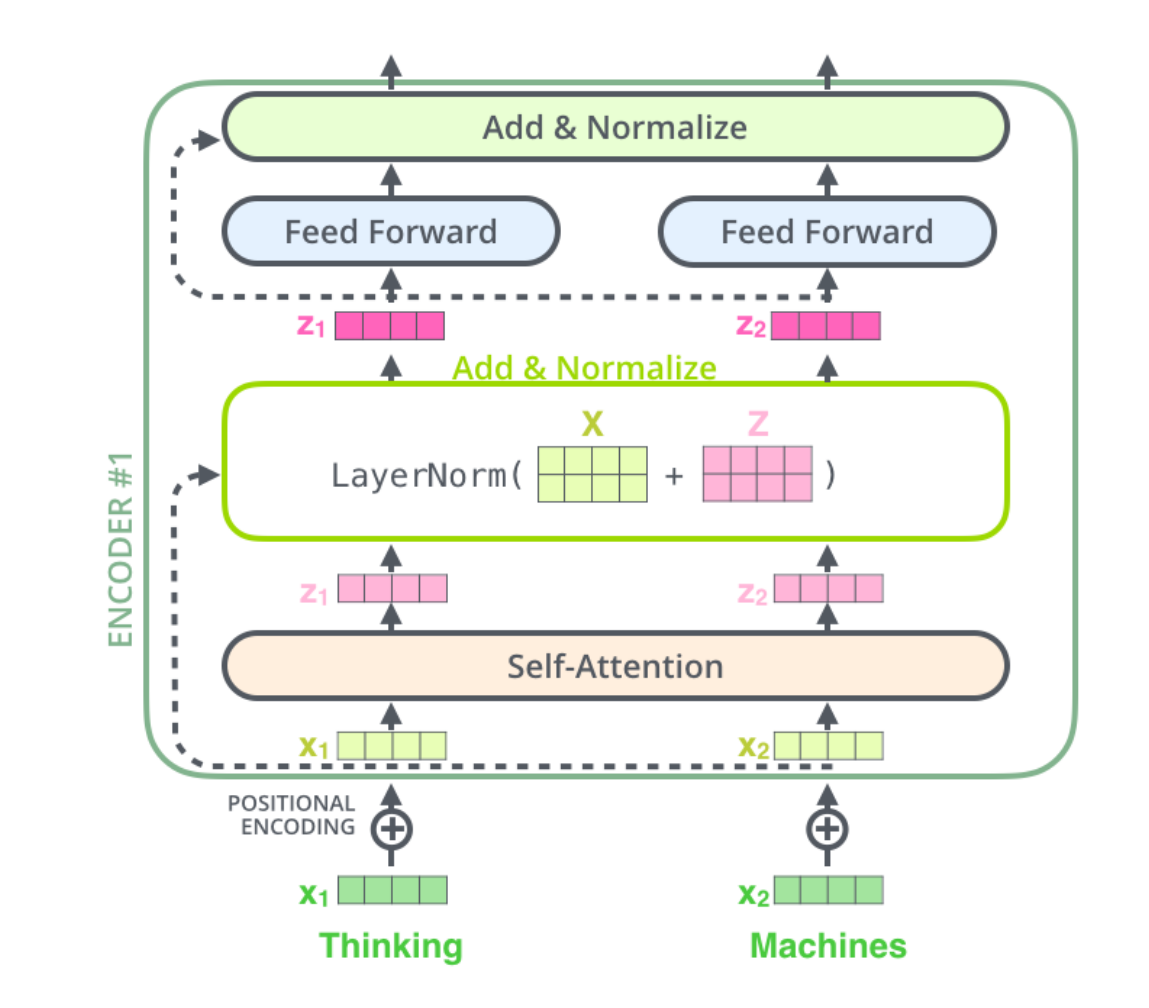
残差连接
编码器的每个子层(Self Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization)