一、集合
集合可以保存数量不确定的数据,以及保存具有映射关系的数据。集合和数组不一样,数组
既可以是基本类型的值,也可以是对象(实际上保存的是对象的引用变量),而集合里只能
保存对象。
Java的集合类主要由两个派生接口而出:Collection和Map
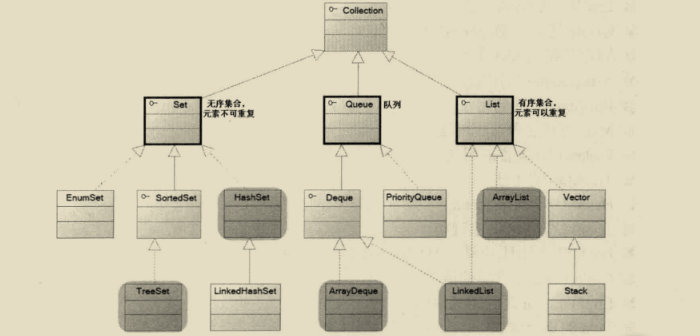
Collection集合体系的继承树
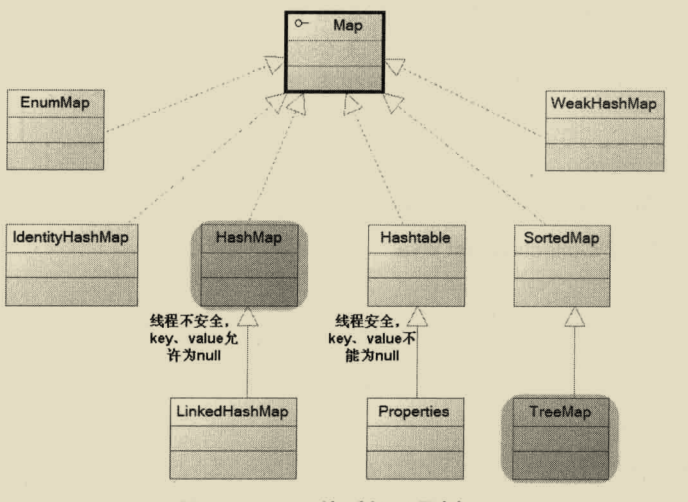
Map体系的继承树
二、Collection和Iterator接口
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法既可以用于操作Set集合,也可以
用于操作List和Queue集合。Collection接口里定义了如下操作集合元素的方法。
boolean add(Object o):该方法用于向集合里添加一个元素。如果集合对象被添加操作改变了,则返回true
boolean addAll(Collection c):该方法把集合c里的所有元素添加到指定集合里。如果集合对象被添加操作改变了,则返回true。
void clear():清除集合里的所有元素,将集合长度变为0.
boolean contains(Object o):返回集合里是否包含指定元素。
boolean containsAll(Collection c):返回集合里是否包含集合c里的所有元素。
boolean isEmpty():返回集合是否为空,当集合长度为0时返回true,否则返回false。
Iterator iterator():返回一个Iterator对象,用于遍历集合里的元素。
boolean removeAll(Collection c):从集合中删除集合c里不包含的元素(相当于把调用该方法的集合减集合c),
如果该操作改变了调用该方法的集合,则方法返回true。
int size():该方法返回集合里元素的个数。
Object[] toArray():该方法把集合转换成一个数组,所有的集合元素变成对应的数组元素。
import java.util.*; public class CollectionTest { public static void main(String[] args) { Collection<Object> c = new ArrayList<Object>(); //添加元素 c.add("哈利波特"); //虽然集合里不能放基本类型的值,但Java支持自动装箱 c.add(6); System.out.println("c集合的元素个数为:"+c.size()); //删除指定元素 c.remove(6); System.out.println("c集合的元素个数为:"+c.size()); //判断是否包含指定字符串 System.out.println("c集合是否包含"哈利波特"字符串:"+c.contains("哈利波特")); c.add("钢之炼金术师"); System.out.println("c集合的元素:"+c); Collection<Object> books = new HashSet<Object>(); books.add("棋魂"); books.add("哈利波特"); System.out.println("c集合是否完全包含books集合?"+c.containsAll(books)); //用c集合减去books集合里面的元素 c.removeAll(books); System.out.println("c集合里的元素:"+c); //删除c集合里的所有元素 c.clear(); System.out.println("c集合里的元素:"+c); System.out.println("books集合的元素:"+books); } }
结果:

当使用System.out.println()方法来输出集合对象时,将输出[ele1,ele2,...]的形式,这是因为所有的Collection实现类都重写了toString()方法,该方法可以一次性地输出集合中的所有元素。
如果想依次访问集合里的每一个元素,则需要使用某种方式来遍历集合元素,下面介绍遍历集合元素的两种方法。
三、遍历集合
1)使用Lambda表达式遍历集合
Java8为Iterable接口新增了一个forEach(Consumer action)默认方法,该方法的所需参数的类型是一个函数式接口,而Iterable接口是Collection接口的父接口,因此Collection和也可以直接调用该方法。
当程序调用Iterable的forEach(Consumer action)遍历集合元素时,程序会依次将集合元素传给Consumer的accept(T t)方法,正因为Consumer是函数式接口,因此可以使用Lambda表达式来遍历集合元素。
import java.util.*; public class CollectionEach { public static void main(String[] args) { //创建一个集合 Collection<String> books = new HashSet<String>(); books.add("钢之炼金术师"); books.add("火之炼金术师"); books.add("冰之炼金术师"); //调用forEach()方法遍历集合 books.forEach(obj -> System.out.println("迭代集合元素:" + obj)); } }
结果:

2.使用JAVA 8 增强的Iterator遍历集合元素。
Iterator接口也是Java集合框架的成员,但它与Collection系列,Map系列的集合不一样:Collection系列集合、Map系列集合主要用于盛装其他对象而Iterator则主要用于遍历(即迭代访问)Collection集合中的元素,Iterator对象也被称为迭代器。
Iterator接口隐藏了各种Collection实现类的底层细节,向应用程序提供了遍历Collection集合元素的统一编程接口。Iterator接口里定义了如下4个方法。
boolean hasNext():如果被迭代的集合元素还没有被遍历完,则返回true。
Object next():返回集合里的下一个元素
void remove():删除集合里的上一次next方法返回的元素
void forEachRemaining(Consumer action),这是Java8为Iterator新增的默认方法,该方法可以使用Lambda表达式来遍历集合元素。
import java.util.*; public class IteratorTest { public static void main(String[] args) { //创建集合、添加元素 Collection<String> c = new ArrayList<String>(); c.add("色欲"); c.add("暴食"); c.add("贪婪"); c.add("愤怒"); c.add("嫉妒"); c.add("懒惰"); c.add("傲慢"); //获取集合对应的迭代器 Iterator it = c.iterator(); System.out.println("人有七大罪:"); while(it.hasNext()) { //it.next()方法返回的数据类型是Object类型,因此需要强制类型转换 String str = (String)it.next(); System.out.println(str); if(str.equals("懒惰")) { //从集合中删除上一次next()方法返回的元素 it.remove(); } //对str变量赋值,不会改变集合元素本身 str = "测试字符串"; } System.out.println(c); } }
测试结果:

从上面程序可以看出,当使用Iterator对集合元素进行迭代时,Iterator并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量,所以修改迭代变量的值对集合元素本身没有任何影响。
3.使用Java8新增的Predicate操作集合
Java8 为 Collection集合新增了一个removeIf(Predicate filter)方法,该方法将会批量删除符合filter条件的所有元素。该方法需要一个Predicate(谓词)对象作为参数,Predicate也是函数式接口,因此可以使用Lambda表达式作为参数。
import java.util.*; public class PredicateTest{ public static void main(String[] args) { //创建一个集合 Collection<String> books = new HashSet<String>(); books.add(new String("七夜雪")); books.add(new String("听雪楼")); books.add(new String("大漠荒颜")); books.add(new String("镜")); books.add(new String("羽")); System.out.println(books); //使用Lambda表达式(目标类型是Predicate)过滤集合 books.removeIf(ele -> ((String)ele).length() < 2); System.out.println("过滤后:"); System.out.println(books); } }
测试结果:

使用Predicate可以充分简化集合的运算,假设依然由上面程序所示的books集合,如果程序有如下三个统计需求:
1)统计书名中出现"镜"字符串的图书数量。
2)统计书名中出现“听雪楼”字符串的图书数量
3)统计书名长度大于6的图书数量
此处只是一个假设,实际上还可能有更多的统计需求。如果采用传统的编程方式来完成这些需求,则需要执行三次循环,但采用Predicate只需要一个方法即可。
import java.util.*; import java.util.function.*; public class PredicateTest2{ public static void main(String[] args) { //创建books集合 Collection<String> books = new ArrayList<String>(); books.add("听雪楼-血薇"); books.add("听雪楼-护花铃"); books.add("听雪楼-荒原雪"); books.add("听雪楼-忘川"); books.add("镜-双城"); books.add("镜-破军"); books.add("镜-龙战"); books.add("鼎剑阁"); books.add("七夜雪"); //统计书名包含"镜"子串的图书数量 System.out.println(calAll(books, ele->((String)ele).contains("镜"))); //统计书名中包含“听雪楼”子串的图书数量 System.out.println(calAll(books, ele->((String)ele).contains("听雪楼"))); //统计书名字符串长度大于5的图书数量 System.out.println(calAll(books, ele->((String)ele).length() > 5)); } public static int calAll(Collection<String> books ,Predicate<String> p) { int total = 0; for (String book : books ) { //使用Predicate的test()方法判断对象是否满足Predicate指定的条件 if (p.test(book)){ total ++; } } return total; } }
测试结果:

上面程序先定义了一个calAll()方法,该方法会使用Predicate判断每个集合元素是否符合特定条件——该条件通过Predicate参数动态传入,从上面代码可以看到,程序传入了三个Lambda表达式(其目标类型都是Predicate),这样calAll()方法就只会统计满足Predicate条件的图书。
4.使用Java8新增的Stream操作集合
Java8还新增了Stream,IntStream,LongStream,DoubleStream等流式API,这些API代表多个支持串行和并行聚集操作的元素。上面四个接口中,Stream是一个通用的流接口,而IntStream,LongStream,DoubleStream则代表了元素类型为int,long,double的流。
Java8还未每个流式API提供了对应的Builder,例如Stream.Builder,IntStream.Builder,LongStream.Builder,DoubleStream.Builder,开发者可以通过这些Builder来创建对应的流。
独立s使用Stream的步骤如下:
1.使用Stream或XxxStream的builder()类方法创建该Stream对应的Builder
2.重复调用Builder的add()方法向该流中添加多个元素。
3.调用Builder的builde()方法获取对应的Stream。
4.调用Stream的聚集算法
在上面4个步骤中,第4步可以根据具体需求来调用不同的方法,Stream提供了大量的聚集方法用户调用,具体可参考Stream或XxxStream的API文档,对于大部分聚集方法而言,每个Stream只执行一次。
import java.util.stream.*; public class IntStreamTest{ public static void main(String[] args) { IntStream is = IntStream.builder() .add(20) .add(13) .add(-2) .add(18) .build(); //下面调用聚集方法的代码每次只能执行一行 //System.out.println("is所有元素的最大值:"+is.max().getAsInt()); //System.out.println("is所有元素的最小值:"+is.min().getAsInt()); //System.out.println("is所有元素的总和:"+is.sum()); //System.out.println("is所有元素的平均值:"+is.average()); //System.out.println("is所有元素的平方是否都大于20:"+is.allMatch(ele -> ele * ele > 20)); //System.out.println("is是否其中一个元素平方大于20:"+is.anyMatch(ele -> ele * ele > 20)); //将is映射成一个新Stream,新Stream的每个元素是原Stream元素的2倍+1 IntStream newIs = is.map(ele -> ele * 2 + 1); //使用方法引用的方式来遍历集合元素 newIs.forEach(System.out::println); } }
测试结果:

上面程序线创建了一个IntStream,接下来分别多次调用IntStream的聚集方法执行操作,这样即可获取该流的信息。注意:上面的聚集方法每次只能执行一行,因此需要把其他的给注释掉。
Stream提供了大量的方法进行聚集操作,这些方法既可以是中间的,也可以是末端的。
中间方法:中间操作允许流保持打开状态,兵允许直接调用后续方法。上面程序中的map()方法就是就是中间方法。中间方法返回值是另外一个流。
末端方法:末端方法是对流的最终操作,当对某个Stream执行末端方法以后,该流将会被“消耗”且不可再用,上面程序中的sum(),count(),average()等方法都是末端方法。
下面简单介绍一下Stream常用的中间方法:
filter(Predicate predicate):过滤Stream中所有不符合predicate的元素
mapToXxx(ToXxxFuntion mapper):使用ToXxxFunction对流中的元素执行一对一的转换,该方法返回的新流中包含了ToXxxFunction转换生成的所有元素。
peek(Consumer action):一次对每个元素执行一些操作,该方法返回的流与原有流包含相同的元素,主要用于调试。
distinct():该方法用于排序流中所有重复的元素
sorted():该方法用于保证流中的元素在后续的访问中处于有序状态。
limit(long maxSize):该方法用于保证对该流的后续访问中最大允许访问的元素个数。
下面介绍Stream常用的末端方法
forEach(Consumer action):遍历流中所有元素,对每个元素执行action
toArray():将流中所有元素转换成一个数组
reduce():通过某种操作来合并流中的元素
min();返回流中的所有元素的最小值
max():返回流中所有元素的最大值
count():返回流中所有元素的数量
anyMatch(Predicate predicate):判断是否至少包含一个元素满足Predicate条件
allMatch(Predicate predicate):判断流中是否每个元素都符合Predicate条件
nonMatch(Predicate predicate):判断流中是否所有元素都不符合Predicate条件
findFirst():返回流中第一个元素
findAny():返回流中任意一个元素
对于之前的示例程序,我们需要额外定义一个calAll()方法来遍历集合元素,然后依次对每个集合元素进行判断,这样比较麻烦,如果使用Stream,即可直接对集合中所有元素进行批量操作,下面使用Stream来改写这个程序
import java.util.*; import java.util.stream.*; public class CollectionStream{ public static void main(String[] args) { //创建集合 Collection<String> books = new ArrayList<String>(); books.add("听雪楼-血薇"); books.add("听雪楼-护花铃"); books.add("听雪楼-荒原雪"); books.add("听雪楼-忘川"); books.add("镜-双城"); books.add("镜-破军"); books.add("镜-龙战"); books.add("鼎剑阁"); books.add("七夜雪"); //统计书名中包含"听雪楼"子串的图书数量 System.out.println(books.stream().filter(ele->((String)ele).contains("听雪楼")).count()); //统计书名中包含"镜"子串的图书数量 System.out.println(books.stream().filter(ele->((String)ele).contains("镜")).count()); //统计书名长度大于4的图书数量 System.out.println(books.stream().filter(ele->((String)ele).length() >= 4).count()); //先调用Collection对象的stream()方法将集合转换成Stream //再调用Stream的mapToInt()方法获取原有的Stream对应的IntStream System.out.println("--------------------"); books.stream().mapToInt(ele -> ((String)ele).length()).forEach(System.out::println); } }
测试结果:

从上面程序可以看出,程序只要调用Collection的stream()方法即可返回该集合对应的Stream,接下来就可以通过Stream提供的方法对所有的集合元素进行处理,这样大大的简化了集合编程的代码,这也是Stream编程带来的优势。
上面程序中最后一段代码先将调用Collection对象的stream()方法将集合转换成Stream对象,然后调用Stream对象的mapToInt()方法将其转换为IntStream——这个mapToInt方法就是一个中间方法,因此程序可继续调用IntStream的forEach()方法来遍历流中的元素。