一、概念
严格来说Map并不是一个集合,而是两个集合的映射关系,这两个集合每条数据通过映射关系,形成了Entry<key,value>,我们可以看成一条数据,key作为键,value作为值,称为键值对。一个Map由多个Entry组成。
因为Map不是Collection的子接口,所以没有Iterator,无法对其进行forEach遍历。
二、Map的部分实现类
HashMap
采用哈希表算法,不会保证key的添加顺序,不允许重复,允许null值作为key,线程不安全。判断重复的标准:两个Entry先使用equals方法比较key,如果相同再比较key的hashCode,当两次判断都相同的时候认为是相同元素。
TreeMap
采用红黑树算法,不会保证key的添加顺序,不允许重复,不允许null值作为key,线程不安全,集合中的元素按照key的自然排序或定制规则进行排序,判断重复的标准是:compareTo/compare方法的返回值为0。
LinkedHashMap
采用链表和哈希表算法,保证元素的添加顺序,不允许重复,允许null值作为key,线程不安全,判断重复的标准和HashMap相同。
HashTable
线程安全的HashMap,不可以存放NULL,性能低。
Properties
HashTable的子类,要求key和value都是String类型,用于加载资源文件
三、HashMap和HashSet的关系
首先我们来看一下HashSet的源码:


1 package collection; 2 3 import java.util.AbstractSet; 4 import java.util.HashMap; 5 import java.util.Iterator; 6 import java.util.Set; 7 8 public class HashSet<E> 9 extends AbstractSet<E> 10 implements Set<E>, Cloneable, java.io.Serializable 11 { 12 //HashSet里封装了一个HashMap 13 private HashMap<E,Object> map; 14 15 private static final Object PRESENT = new Object(); 16 17 //HashSet的构造方法初始化这个HashMap 18 public HashSet() { 19 map = new HashMap<E,Object>(); 20 } 21 22 //向HashSet中增加元素,其实就是把该元素作为key,增加到Map中 23 //value是PRESENT,静态,final的对象,所有的HashSet都使用这么同一个对象 24 public boolean add(E e) { 25 return map.put(e, PRESENT)==null; 26 } 27 28 //HashSet的size就是map的size 29 public int size() { 30 return map.size(); 31 } 32 33 //清空Set就是清空Map 34 public void clear() { 35 map.clear(); 36 } 37 38 //迭代Set,就是把Map的键拿出来迭代 39 public Iterator<E> iterator() { 40 return map.keySet().iterator(); 41 } 42 43 }
可以发现,HashSet实际上是一个HashMap。
只不过以存入的对象作为key值,所有的元素的value都是常量PRESENT。
四、浅谈hashcode原理,分析HashMap,HashSet查找效率高的原因
利用一种空间换时间的思维,存入时计算对象的hashcode值,然后存储到对应该值的位置,查找时通过对象的hashcode值直接定位获取,达到惊人的O(1)时间复杂度。
简单的类比一下:
-----hashcode概念-----
所有的对象,都有一个对应的hashcode(散列值)
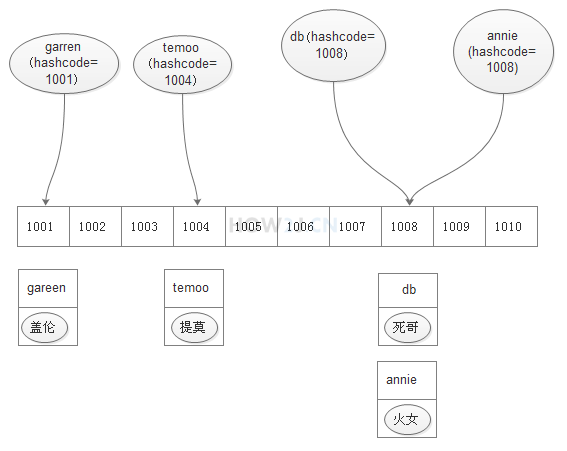
比如字符串“gareen”对应的是1001 (实际上不是,这里是方便理解,假设的值)
比如字符串“temoo”对应的是1004
比如字符串“db”对应的是1008
比如字符串“annie”对应的也是1008
-----保存数据-----
准备一个数组,其长度是2000,并且设定特殊的hashcode算法,使得所有字符串对应的hashcode,都会落在0-1999之间
要存放名字是"gareen"的英雄,就把该英雄和名称组成一个键值对,存放在数组的1001这个位置上
要存放名字是"temoo"的英雄,就把该英雄存放在数组的1004这个位置上
要存放名字是"db"的英雄,就把该英雄存放在数组的1008这个位置上
要存放名字是"annie"的英雄,然而 "annie"的hashcode 1008对应的位置已经有db英雄了,那么就在这里创建一个链表,接在db英雄后面存放annie
-----查找数据-----
比如要查找gareen,首先计算"gareen"的hashcode是1001,根据1001这个下标,到数组中进行定位,(根据数组下标进行定位,是非常快速的) 发现1001这个位置就只有一个英雄,那么该英雄就是gareen.
比如要查找annie,首先计算"annie"的hashcode是1008,根据1008这个下标,到数组中进行定位,发现1008这个位置有两个英雄,那么就对两个英雄的名字进行逐一比较(equals),因为此时需要比较的量就已经少很多了,很快也就可以找出目标英雄(但是我们需要尽量避免这种情况的发生,会影响到HashMap的性能)
这就是使用HashMap进行查询,非常快的原理。