最近面试中都遇到了这样一个数据库题:
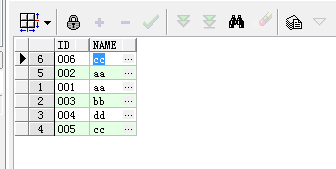
删除表中的重复数据,有且只保留一条重复数据。
思路:
1)这个题需要用到rowid,首先找到重复数据的rowid,并找出rowid最大或最小值,作为删除的条件;
select min(rowid) from aa group by Name having count(Name) > 1
2)根据name找出数量大于1的name
select name from aa group by name having count(name) > 1
3)根据上两个条件进行执行删除操作
delete from aa t where t.name in (select name from aa group by name having count(name) > 1)
and rowid not in (select min(rowid) from aa group by Name having count(Name) > 1);