一、基本信息
标题:基于数据分析的高考志愿决策模型研究
时间:2017
来源:山东师范大学
关键词:数据分析; 位次转换; 概率模型; 选择倾向; 决策模型;
二、研究内容
1.论文主要内容
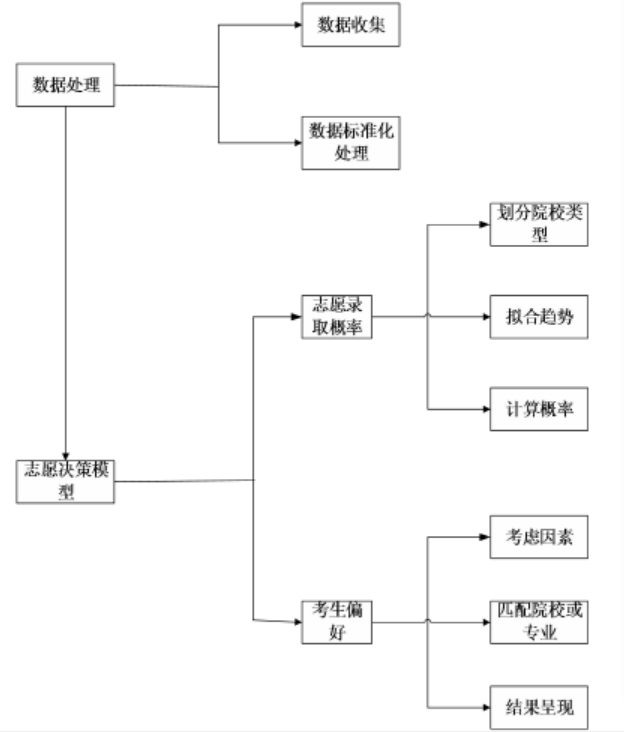
(1)提出了新的标准分概念。本文在对历年高考成绩分析后发现,因受考生水平、招生人数变动、试题难易程度等的影响,每年的分数都会有所变动。用教育统计学或者高考中常用的标准分能够在一定程度上解决分数不一的情况。论文提出位次代替分数的方法相比标准分具有更好的代表性,和更广泛的使用性。提出的新的标准分转换方法是通过位次信息进行转化,将历年分数通过位次进行统一转化为同一年的数据,将历年的成绩放在同一年份比较,大大提升了历年成绩的参考性。将通过位次转化后的统一标准分代替以往研究中的教育统计学中的标准分,解决了数据不一致的问题,更具有直观性。
(2)提升了录取概率模型的准确性。通过对院校进行波动类型划分,综合考虑院校招生人数以及历年波动趋势确定院校的安全分。对现有录取概率模型中存在的未充分考虑院校波动特点的问题进行改进,对影响院校或专业录取分数线的因素进行分析,并利用二次指数平滑预测,对录取分数线进行预测,提出一种更加准确的录取概率模型。本问提出的录取概率模型,对原有的概率分段函数的节点进行调整,有效提升了计算的准确度。
(3)体现了考生的偏好程度。论文通过获取考生关注因素及对该因素关注程度的信息,在获取考生真实偏好的基础上,将考生偏好与院校特征进行匹配,为考生推荐符合考生偏好的院校。
2.论文结构
第一章:绪论。主要介绍课题的研究背景及意义,即志愿填报对于高考考生是必不可少的环节,对考生有着重要的意义,在填报过程中考生及家长对信息掌握不全面及对信息的不合理利用造成考生在志愿填报中不能被理想院校录取。同时对国内外关于志愿填报方面的研究进行了归纳总结,并借鉴前人研究成果,对前人研究中的不足之处加以改进,最后对本文的主要内容进行了概括总结。
第二章:介绍本文的总体架构。对数据不统一带来的研究困扰进行分析;并介绍了志愿决策模型的主要内容进行阐述,其包括院校的波动类型划分,院校和专业录取趋势预测及考生偏好的选取、匹配等。本章就志愿填报过程中的问题进行分析的基础上提出本文的总体框架。
第三章:提出新的标准分概念。通过对原有标准分及原有高考标准分的分析发现,在现有的高考分数下,原标准分仍然无法解决数据不统一带来的问题。本文在对历年数据分析的基础上提出了新的标准分概念。新标准分的核心是将不同年份的成绩转化为统一年份的高考成绩,用以解决不同年份的成绩无法进行有效比较的问题。并将本文提出的新标准分的概念与原有的教育统计学中的标准分比较,验证了本文提出的标准分相比原有标准分的优越性。
第四章:提出了本文的高考志愿决策模型。首先对考生高考志愿招生提档规则进行简单介绍;然后在第三章提出的标准分处理后的数据基础上,根据历年高考志愿填报数据进行分析,确定院校类型,根据招生计划确定研究范围;根据院校类型确定平滑系数,进一步利用二次指数平预测对院校录取分数波动情况进行预测,并对原有的录取概率模型进行改进,进一步提升了概率计算的准确度;最后以问卷方式获取考生对院校或专业的偏好,将考生偏好与院校进行匹配,确定所要推荐的院校。
第五章:对实验相关工作进行介绍和分析。首先介绍了实验方法和评价标准,然后对实验结果进行了展示和分析。此外,将用户对该模型的推荐结果的满意度进行评测,评估了该模型用户的认可度。
3.高考志愿决策模型主要包含部分
三、结论
通过对本篇论文的仔细阅读,主要了解到了志愿填报决策模型,意在为考生提供志愿填报时的分析方法,为报考志愿提供参考。我觉得本篇论文值得我们去学习的地方在于数据标准化处理。作者通过对考生在高考志愿填报中历年高校录取分数变动情况的分析后将院校分为四种类型,即平稳型、上升型、下降型和波动型,并根据四种情况分别确定平滑系数。通过这种数据标准化的处理方式,便能够达到利用二次指数平滑预测,对院校录取分数趋势进行预测。这为我对自己项目的数据标准化处理提供了一个很好的借鉴作用。
四、参考文献
[1]周井芝.基于数据分析的高考志愿决策模型研究[D].山东师范大学,2017.