RCU(read-copy-update)同步机制。R(Read):读者不需要获得任何锁就可访问RCU保护的临界区;C(Copy):写者在访问临界区时,写者“自己”将先拷贝一个临界区副本,然后对副本进行修改;U(Update):RCU机制将在适当时机使用一个回调函数把指向原来临界区的指针重新指向新的被修改的临界区,锁机制中的垃圾收集器负责回调函数的调用。
读者在访问被RCU保护的共享数据期间不能被阻塞,这是RCU机制得以实现的一个基本前提,也就说当读者在引用被RCU保护的共享数据期间,读者所在的CPU不能发生上下文切换,spinlock和rwlock都需要这样的前提。写者在访问被RCU保护的共享数据时不需要和读者竞争任何锁,只有在有多于一个写者的情况下需要获得某种锁以与其他写者同步。写者修改数据前首先拷贝一个被修改元素的副本,然后在副本上进行修改,修改完毕后它向垃圾回收器注册一个回调函数以便在适当的时机执行真正的修改操作。等待适当时机的这一时期称为grace period,而CPU发生了上下文切换称为经历一个quiescent state,grace period就是所有CPU都经历一次quiescent state所需要的等待的时间。垃圾收集器就是在grace period之后调用写者注册的回调函数来完成真正的数据修改或数据释放操作的。
quiescent state(静默状态过程),它表示为CPU发生上下文切换的过程;grace period(即本节内容一开始提及的“适当时机”),它表示为所有CPU都经历一次quiescent state所需要的等待的时间,也即系统中所有的读者完成对共享临界区的访问。其中当一个进程在执行时,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下文。当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,也就是保存当前进程的上下文,以便再次执行该进程时,能够得到进程切换时的状态,从而使该进程能够执行下去。
"适当时机":所有引用该共享临界区的CPU都退出对临界区的操作。即没有CPU再去操作这段临界区后,这段临界区即可回收了,此时回调函数即被调用。
这种机制允许读写并发进行,对于读者来说,读者间没有任何同步开销,因为可随时读取临界区,和其他读者没有相互影响;但对于不同的写者来说,它们之间如果存在同步开销,则写者间的同步开销则取决于写者间的采用同步机制,和RCU并没有直接的关系。尽管RCU能保护读访问不受写访问的干扰,但他不对写访问之间的相互干扰提供防护!那么必须使用普通的同步原语防止并发的写操作,如自旋锁。
以链表元素删除为例详细说明这一过程:
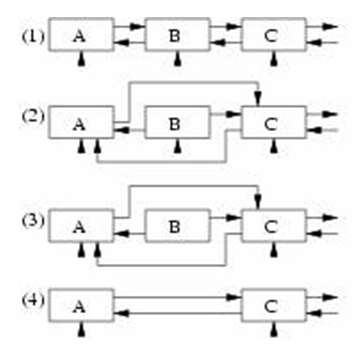
写者要从链表中删除元素 B,它首先遍历该链表得到指向元素 B 的指针,然后修改元素 B 的前一个元素的 next 指针指向元素 B 的 next 指针指向的元素C,修改元素 B 的 next 指针指向的元素 C 的 prep 指针指向元素 B 的 prep指针指向的元素 A,在这期间可能有读者访问该链表,修改指针指向的操作是原子的,所以不需要同步,而元素 B 的指针并没有去修改,因为读者可能正在使用 B 元素来得到下一个或前一个元素。写者完成这些操作后注册一个回调函数以便在 grace period 之后删除元素 B,然后就认为已经完成删除操作。垃圾收集器在检测到所有的CPU不在引用该链表后,即所有的 CPU 已经经历了 quiescent state,grace period 已经过去后,就调用刚才写者注册的回调函数删除了元素 B。
假定指针ptr指向一个被RCU保护的数据结构。直接反引用指针是禁止的,首先必须调用rcu_dereference(ptr),然后反引用返回的结果。反引用指针并使用其结果的代码,需要用rcu_read_lock和rcu_read_unlock调用保护。被反引用的指针不能再rcu_read_lock()和rcu_read_unlock()保护的代码范围之外使用,也不能用于写访问。
示例代码:
1 rcu_read_lock(); 2 3 p = rcu_dereference(ptr); 4 5 if (p != NULL) 6 { 7 awesome_function(p); 8 } 9 10 rcu_read_unlock();
如果必须修改ptr指向的对象,则需要使用rcu_assign_pointer.按RCU的术语,该操纵公布了这个指针,后续的读取操作将看到新的结构,而不是原来的。
示例代码:
1 struct super_dumper *new_ptr = kmalloc(...); 2 3 new_ptr->meaning = xyz; 4 new_ptr->of = 42; 5 new_ptr->life = 23; 6 7 rcu_assign_pointer(ptr, new_ptr);
在新值公布之后,旧的结构实例会怎么样呢?在所有的读访问完成之后,内核可以释放该内存,但它需要知道何时释放内存是安全的。因此,RCU提供了另外两个函数。
- synchronize_rcu()等待所有现存的读访问完成。在该函数返回之后,释放与原指针关联的内存是安全的。
- call_rcu()可用于注册回调函数,在所有针对共享资源的读访问完成之后调用。这要求将一个rcu_head实例嵌入(不能通过指针)到RCU保护的数据结构。
1 struct super_duper 2 { 3 struct rcu_head head; 4 int meaning, of, life; 5 };
该回调函数可通过参数访问对象的rcu_head成员,进而使用container_of机制访问对象本身。
/** * struct rcu_head - callback structure for use with RCU * @next: next update requests in a list * @func: actual update function to call after the grace period. */ struct rcu_head { struct rcu_head *next; void (*func)(struct rcu_head *head); }; static inline void synchronize_rcu(void) { synchronize_sched(); } /** * call_rcu() - Queue an RCU callback for invocation after a grace period. * @head: structure to be used for queueing the RCU updates. * @func: actual callback function to be invoked after the grace period * * The callback function will be invoked some time after a full grace * period elapses, in other words after all pre-existing RCU read-side * critical sections have completed. However, the callback function * might well execute concurrently with RCU read-side critical sections * that started after call_rcu() was invoked. RCU read-side critical * sections are delimited by rcu_read_lock() and rcu_read_unlock(), * and may be nested. */ extern void call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *head));
未完待续...
参考资料: