TreeSet底层原理
TreeSet底层数据结构是红黑树(一种自平衡的二叉树,自平衡是指如果有空的左/右子树,元素会先入空的左/右子树,而不会一直往一个方方向添加元素出现不平衡现象)。
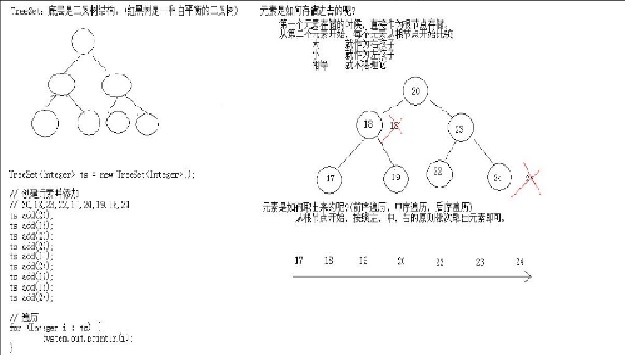
该自平衡二叉树保证了元素的有序性(存储逻辑顺序),因为按照前、中、后三种顺序都可以有序的读取到集合中的元素。
下面是关键底层源码:
发现add方法中调用了TreeSet中的一个成员变量m.put()方法。
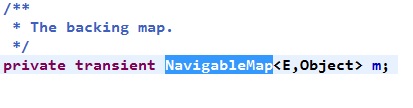

而NavigableMap是一个接口,但是它有一个实现类是TreeMap:

那么,就应该看看TreeSet中该m变量的初始化到底是哪个实现类了:
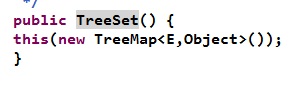
看到默认构造器中为TreeMap,则可以知道m.put()方法实际调用的是TreeMap中的put()方法,跟踪进入源码:


总结:通过观察TreeSet的底层源码发现,TreeSet的add(E e)方法,底层是根据实现Comparable的方式来实现的唯一性,通过compare(Object o)的返回值是否为0来判断是否为同一元素。
compare() == 0,元素不入集合。
compare() > 0 ,元素入右子树。
compare() < 0,元素入左子树。
而对其数据结构:自平衡二叉树做前(常用)、中、后序遍历即可保证TreeSet的有序性。