一、Map概述
Map:“键值”对映射的抽象接口。该映射不包括重复的键,一个键对应一个值。
1.1、HashTable【不常用】
基于“拉链法”实现的散列表。
底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
初始size为11,扩容:newsize = olesize*2+1
计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
1.2、HashMap和ConcurrentHashMap【推荐常用】
参看:020-并发编程-java.util.concurrent之-jdk6/7/8中ConcurrentHashMap、HashMap分析
1.3、HashMap和HashTable有什么区别
1、HashMap是非线程安全的,HashTable是线程安全的。
2、HashMap的键和值都允许有null值存在,而HashTable则不行。
3、因为线程安全的问题,HashMap效率比HashTable的要高。
1.4、HashTable、Collections.synchronizedMap()、 ConcurrentHashMap线程同步上有什么区别,如何线程安全的使用 HashMap
Hashtable源码中是使用 synchronized 来保证线程安全的
Collections.synchronizedMap()
源码,synchronizedMap()的实现


// synchronizedMap方法 public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) { return new SynchronizedMap<>(m); } // SynchronizedMap类 private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable { private static final long serialVersionUID = 1978198479659022715L; private final Map<K,V> m; // Backing Map final Object mutex; // Object on which to synchronize SynchronizedMap(Map<K,V> m) { this.m = Objects.requireNonNull(m); mutex = this; } SynchronizedMap(Map<K,V> m, Object mutex) { this.m = m; this.mutex = mutex; } public int size() { synchronized (mutex) {return m.size();} } public boolean isEmpty() { synchronized (mutex) {return m.isEmpty();} } public boolean containsKey(Object key) { synchronized (mutex) {return m.containsKey(key);} } public boolean containsValue(Object value) { synchronized (mutex) {return m.containsValue(value);} } public V get(Object key) { synchronized (mutex) {return m.get(key);} } public V put(K key, V value) { synchronized (mutex) {return m.put(key, value);} } public V remove(Object key) { synchronized (mutex) {return m.remove(key);} } // 省略其他方法 }
从源码中可以看出调用 synchronizedMap() 方法后会返回一个 SynchronizedMap 类的对象,而在 SynchronizedMap 类中使用了 synchronized 同步关键字来保证对 Map 的操作是线程安全的。
ConcurrentHashMap 在JDK7 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
ConcurrentHashMap 在JDK8 CHM 摒弃了 Segment(锁段)的概念,而是启用了一种全新的方式实现,利用CAS算法。
ConcurrentHashMap性能是明显优于Hashtable和SynchronizedMap
1.5、TreeMap
支持对键有序地遍历,使用时建议先用HashMap增加和删除成员,最后从HashMap生成TreeMap;附加实现了SortedMap接口,支持子Map等要求顺序的操作
Map hashMap = new HashMap<String, String>(); TreeMap<String, String> treeMap = new TreeMap<String, String>(hashMap);
1.6、LinkedHashMap
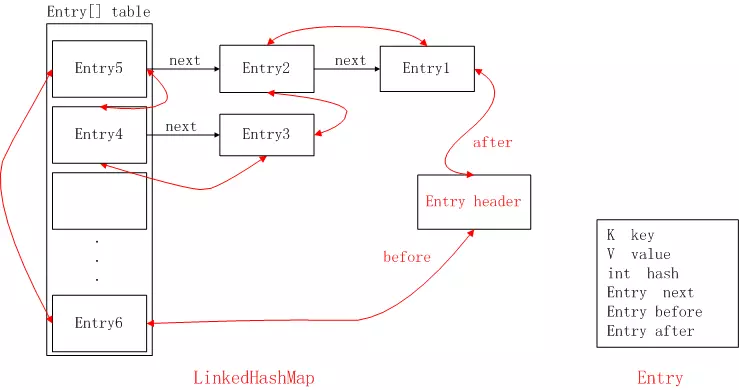
简图
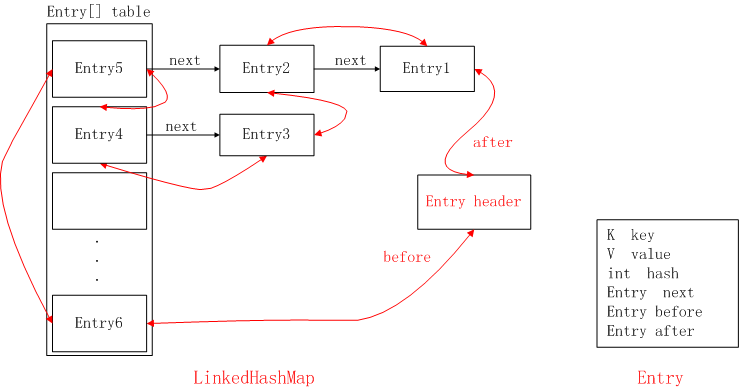
跟HashMap一样,它也是提供了key-value的存储方式,并提供了put和get方法来进行数据存取。
LinkedHashMap继承了HashMap,所以它们有很多相似的地方。
把accessOrder设置为false,这就跟存储的顺序有关了,LinkedHashMap存储数据是有序的,而且分为两种:插入顺序和访问顺序。
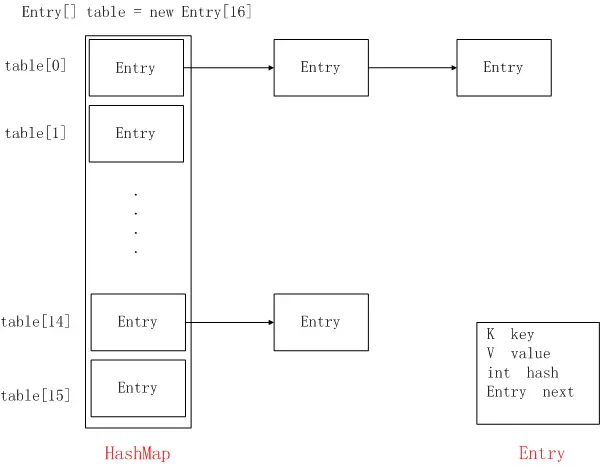
1.6.1、HashMap与LinkedHashMap的结构对比
LinkedHashMap其实就是可以看成HashMap的基础上,多了一个双向链表来维持顺序。
1.6.2、小结
LinkedHashMap是继承于HashMap,是基于HashMap和双向链表来实现的。
HashMap无序;LinkedHashMap有序,可分为插入顺序和访问顺序两种。如果是访问顺序,那put和get操作已存在的Entry时,都会把Entry移动到双向链表的表尾(其实是先删除再插入)。
LinkedHashMap存取数据,还是跟HashMap一样使用的Entry[]的方式,双向链表只是为了保证顺序。
LinkedHashMap是线程不安全的。
二、Set
Set与List的区别在于,Set中存储的元素是经过了去重的(即如果a.equals(b),则Set中只可能存在一个)。
Set的典型实现是HashSet,其主要方法add,remove,contains,均是通过内置的HashMap来进行实现的。
比如add方法,本质上是调用了HashMap的put方法,以传入的object为Key,并以dummy value(private static final Object PRESENT = new Object();)为Value。
remove方法,也是在内部调用了HashMap的remove方法,将传入的object作为key,从而对HashSet中保存的object进行删除