一、概述
大数据体系概述
1.1、什么是zookeeper
是Google的Chubby一个开源的实现,是Hadoop的分布式协调服务
它包含一个简单的原语集,分布式应用程序可以基于他实现同步服务,配置维护和命名服务等。
是保证分布式数据一致性的一种手段
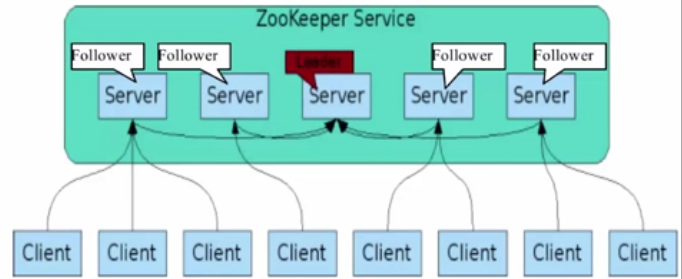
Zookeeper默认采用FastLeaderElection算法,然而FastLeaderElection对于Zookeeper来讲只是相当于paxos中的leader选举。
下面我们用最简单的方式加以描述并建立起Paxos和ZKServer的对应关系。
1.2、paxos算法理解
Paxos描述了这样一个场景:
1、有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。
2、议员的总数(SenatorCount)是确定的,不能更改。
3、岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID),这个编号是一直增长的,不能倒退。
4、每个提议都需要超过半数((SenatorCount)/2+1)的议员同意才能生效。
5、每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。
6、如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保证所有议员记事本上的编号总是相同的。
现在议会有一个目标:保证所有的议员对于提议都能达成一致的看法。
好,现在议会开始运作,所有议员一开始记事本上面记录的编号都是0。
有一个议员发了一个提议:
将电费设定为1元/度。他首先看了一下记事本,嗯,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本,哦,当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1好提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。
现在看冲突的解决:
假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度,S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议:1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。
好,我觉得Paxos的精华就这么多内容。现在让我们来对号入座,看看在ZKServer里面Paxos是如何得以贯彻实施的。
小岛(Island)——ZKServerCluster
议员(Senator)——ZKServer
提议(Proposal)——ZNodeChange(Create/Delete/SetData…)
提议编号(PID)——Zxid(ZooKeeperTransactionId)
正式法令——所有ZNode及其数据:
貌似关键的概念都能一一对应上,但是等一下,Paxos岛上的议员应该是人人平等的吧,而ZKServer好像有一个Leader的概念。没错,其实Leader的概念也应该属于Paxos范畴的。如果议员人人平等,在某种情况下会由于提议的冲突而产生一个“活锁”(所谓活锁我的理解是大家都没有死,都在动,但是一直解决不了冲突问题)。Paxos的作者Lamport在他的文章”ThePart-TimeParliament“中阐述了这个问题并给出了解决方案——在所有议员中设立一个总统,只有总统有权发出提议,如果议员有自己的提议,必须发给总统并由总统来提出。好,我们又多了一个角色:总统。
总统——ZKServerLeader
又一个问题产生了,总统怎么选出来的?
现在我们假设总统已经选好了,下面看看ZKServer是怎么实施的。
情况一:
屁民甲(Client)到某个议员(ZKServer)那里询问(Get)某条法令的情况(ZNode的数据),议员毫不犹豫的拿出他的记事本(localstorage),查阅法令并告诉他结果,同时声明:我的数据不一定是最新的。你想要最新的数据?没问题,等着,等我找总统Sync一下再告诉你。
情况二:
屁民乙(Client)到某个议员(ZKServer)那里要求政府归还欠他的一万元钱,议员让他在办公室等着,自己将问题反映给了总统,总统询问所有议员的意见,多数议员表示欠屁民的钱一定要还,于是总统发表声明,从国库中拿出一万元还债,国库总资产由100万变成99万。屁民乙拿到钱回去了(Client函数返回)。
情况三:
总统突然挂了,议员接二连三的发现联系不上总统,于是各自发表声明,推选新的总统,总统大选期间政府停业,拒绝屁民的请求。 一般都是推举自己。
呵呵,到此为止吧,当然还有很多其他的情况,但这些情况总是能在Paxos的算法中找到原型并加以解决。这也正是我们认为Paxos是Zookeeper的灵魂的原因。当然ZKServer还有很多属于自己特性的东西:Session,Watcher,Version等等,需要我们花更多的时间去研究和学习。
1.3、为什么使用zookeeper
大部分分布式应用需要一个主控、协调器或控制器来管理物理分布的子进程(如资源、任务分配等)
目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
提供通用的分布式锁服务,用以协调分布式应用
keepalived监控节点不好管理
keepalive采用优先级监控【没有协同工作、功能单一】
keepalive可扩展性差
1.4、zookeeper优点
| 特点 | 说明 |
| 最终一致性 | 为客户端展示同一个视图 |
| 可靠性 | 如果消息被到一台服务器接受,那么他将被所有的服务器接受 |
| 实时性 |
zk不能保证两个客户端能同时得到刚更新的数据,如果需要 最新数据,应该在读数据之前调用sync接口 |
| 独立性 | 各个client之间不干预 |
| 原子性 | 更新只能成功或者失败,没有中间状态 |
| 顺序性 | 所有server,同一消息发布顺序一致 |
1.5、zookeeper的工作原理
1、每个server在内存中存储了一份数据;定期落地
2、zookeeper启动时,将从实例中选举一个leader(Paxos协议)
3、leader负责处理数据更新等操作
4、一个更新操作成功,当且仅当大多数Server在内存中成功修改数据
1.6、zookeeper能作什么
Hadoop中使用zk的事件处理确保整个集群只有一个NameNode,存储配置信息等
Hbase中使用zk的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等。