正则化
1.1 过拟合问题 The problem of overfitting
继续使用预测房屋价格的例子,我们希望得到一个函数可以拟合数据点,可以在左图中看到,它的拟合效果是比较差的。那在中间这个图里就有一个不错的拟合效果
最后看一下右图,虽然它拟合了所有的数据点,但它的曲线上下波动较大,并不能算是一个好的模型,那我就称这样的问题叫过拟合问题
具体的概率就是,如果我们有很多特征并且经过训练的假设能够很好的拟合训练集(它的代价函数几乎是等于0),但是它没有办法能够泛化一个新的样本(在一个新的样本中去预测房价)
泛化:一个假设模型运用到新样本中的能力,新样本:训练集中没出现过的数据集

同样在逻辑回归中,也有三个假设模型,分别对应以下三个图。同理再一次的表示了过拟合在数据集中的样子
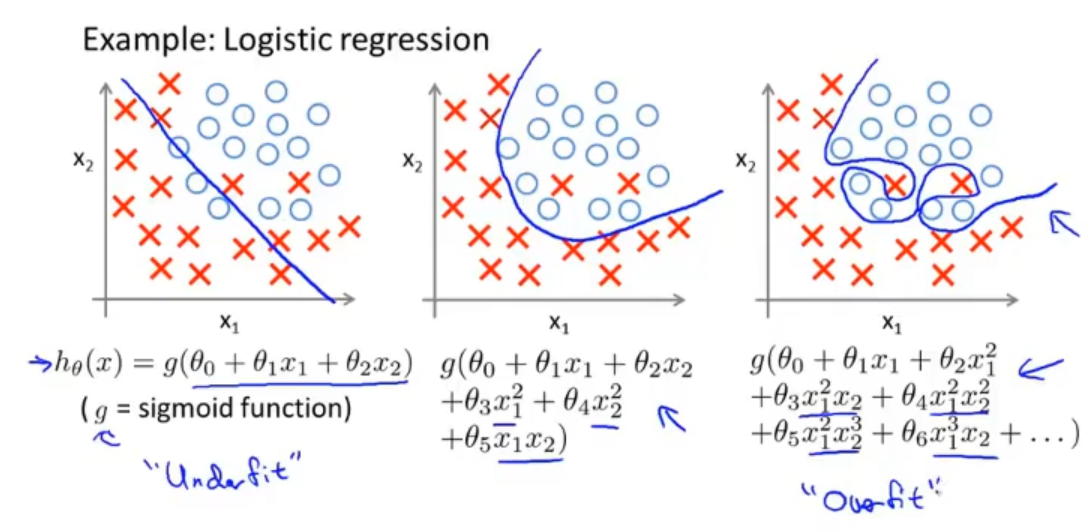
那遇到过拟合时我们应该怎么办?
1.减少特征的数量,这个需要我们去选择哪些特征保留,哪些去掉
2.正则化,这个也是我们重点要介绍的,它是通过减少量级或者参数的值来保留全部的特征

1.2 代价函数 Cost function
对于之前那个图中的假设模型,我们不希望减少特征的数量,那就需要使用正则化。假设θ3和θ4是1000(随机一个比较大的数),那在修改代价函数的时候,我们就希望正则化可以把这两个参数减小,让他们接近于0,就好像我们把他们去掉一样,这样我们就可以得到一个和左图类似的假设模型了,那其实这个就是正则化的思路
这样我们就可以得到一个不错假设模型

那我们就可以让所有的参数使用正则化,就可以得到一个简单的假设模型,也不容易出现过拟合的现象
在一个新的预测房屋例子中有一百个特征,在一开始我们并不知道哪些的特征需要缩小,哪些不要,所以我们在代价函数中增加一个正则项(惩罚项)来对每一个参数进行缩小

其中λ是正则系数,来控制两个目标,一个目标是更好的去拟合训练集,另一个目标是将参数控制的更小
然后最小化代价函数就可以使之前的曲线更加平滑,得到一个更好的假设模型
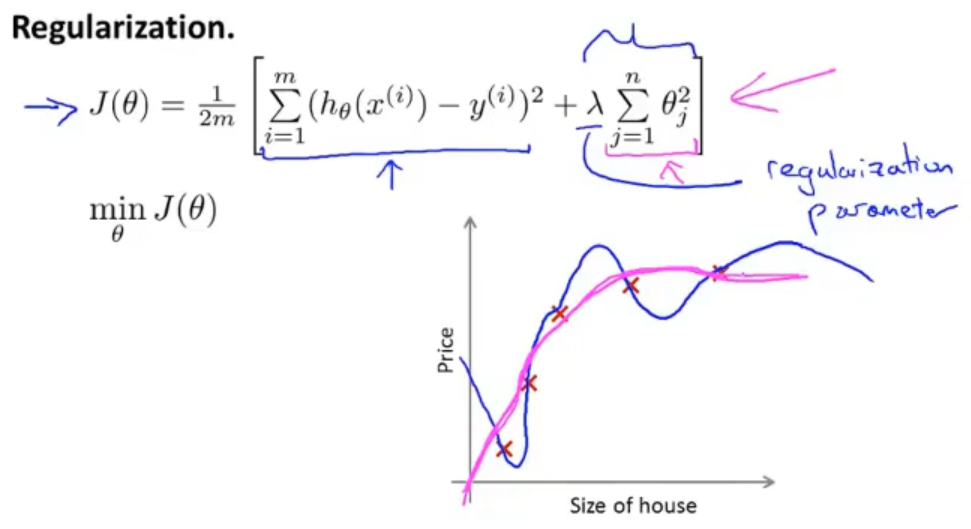
选择参数λ也是十分重要的,如果我们的惩罚项比较大的话,在极端情况下,我们的假设函数就变成一条直线了,那我们得到的是一个比较差的假设模型
之后会介绍如何自动的去选择一个比较合适的参数λ

1.3 线性回归的正则化 Regularized linear regression
线性回归的正则化,在其代价函数中增加了正则项,最后的目标是为了最小化代价函数来获得参数θ

在梯度下降中,我们单独把θ0分离出来,因为在之前有说过,我们加入正则项是不对θ0进行惩罚的,所以在下面的前两个式子中,θ0的更新是不加入正则项,其余的θ是加入正则项的
我们可以对第二式子进行整理合并把θ提取出来,最后得到第三个式子
分析一下第三个式子的意义,我们可以发现式子的前半部分是θ乘一个十分接近1的数(由于学习率α小,样本数m很大),那就可以理解为把θ缩小一点点,后半部分则是和原来更新方法的后半部分一样的

在线性回归中除了使用梯度下降,我们运用到了正规方程,如果加入正则化的话,我们需要对原来的正规方程进行稍微的修改一下
在n个特征的情况下,需要在原来正规方程中加入一个(n+1)*(n+1)的特殊矩阵(在单位矩阵的基础上把(0,0)改为0),具体如下图式子

1.4 逻辑回归的正则化 Regularized logistics regression
在逻辑回归中由于过大增加参数的个数导致了过拟合,会得到蓝色的决策边界,如果在代价函数中加入正则项的话,就会得到一个不错的决策边界(洋红)
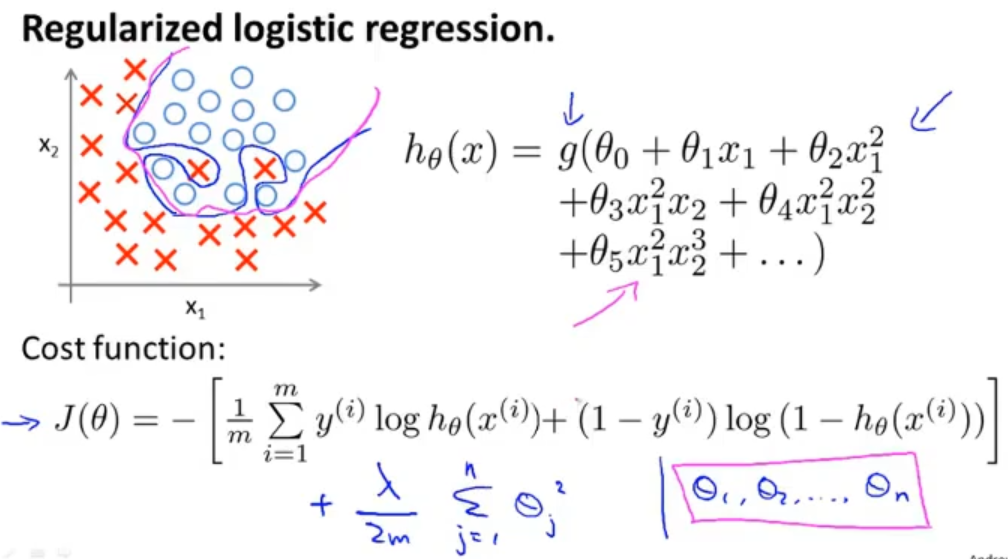
同样在逻辑回归的梯度下降中也需要稍微修改一下参数θ的更新方式,式子看起里与线性回归的差不多,但是假设函数是不一样的,所以这两个是不同的两个东西
