作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
本次作业是在期中大作业的基础上利用hadoop和hive技术进行大数据分析
1.将爬虫大作业产生的csv文件上传到HDFS
2.对CSV文件进行预处理生成无标题文本文件


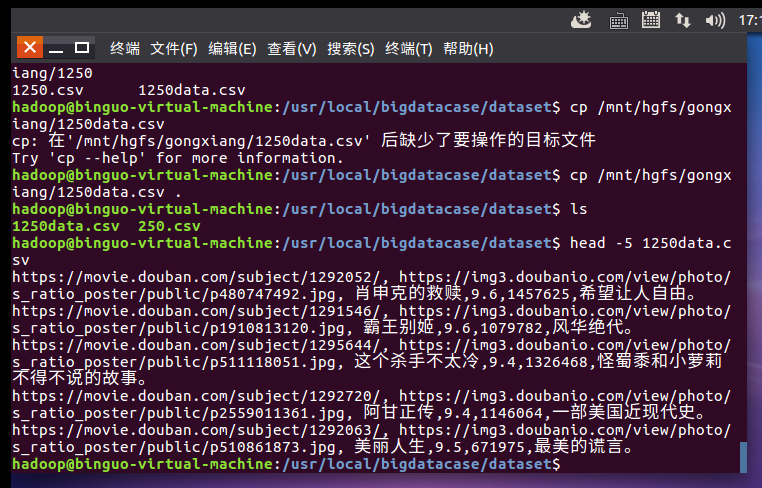
预处理:
使用awk脚本(com_pre_deal.sh)稍作处理,分隔开每一列
启动hdfs
在hdfs上建立/bigdatacase/dataset文件夹

把user_comment.txt上传到HDFS中,并查看前5条记录

3.把hdfs中的文本文件最终导入到数据仓库Hive中
4.在Hive中查看并分析数据
使用netstat -tunlp 查看端口 :3306 LISION确定已经启动了MySql数据库(否则使用$service mysql start启动)
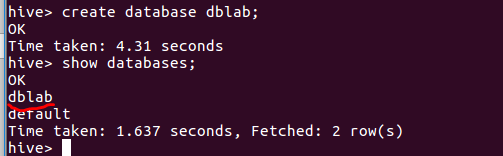
启动Hive,并创建一个数据库dblab
创建外部表,把HDFS中的“/bigdatacase/dataset”目录下的数据(注意要删除之前练习时的数据user_table.txt,只剩下目标数据,否则会把数据叠加在一起!)加载到了数据仓库Hive中


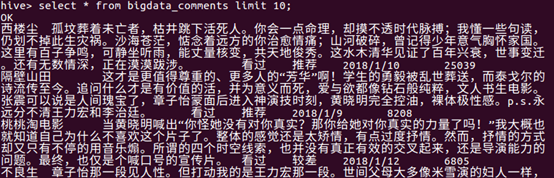
在Hive中查看数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(8条以上的查询分析)
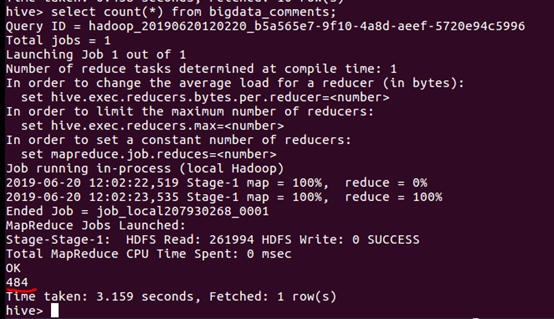
①查询统计总数据量

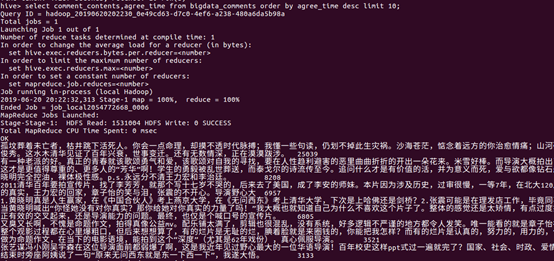
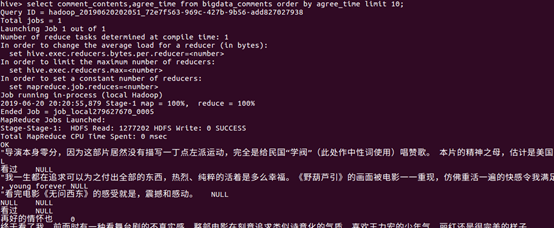
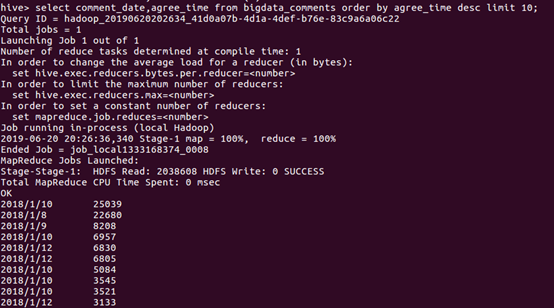
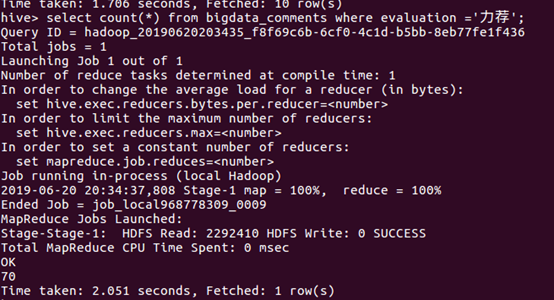
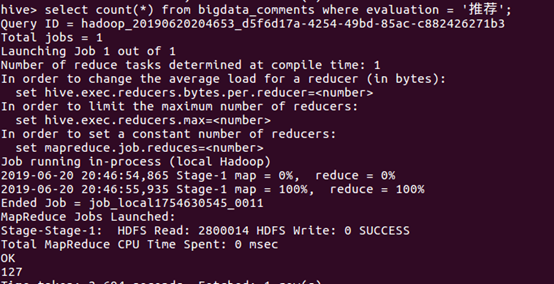
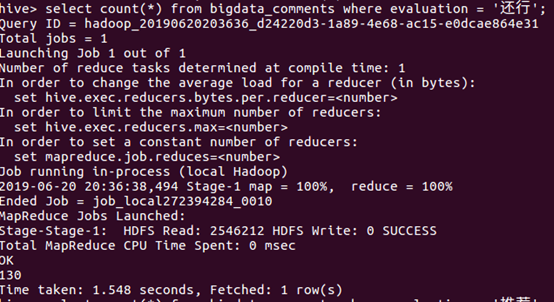
评分在超过9的有130部电影,证明高分电影占有比较低