前言:
前面两篇文章介绍了关于串联(Concatenation)和断言(Assert)操作符,本文介绍第三个常见的操作符计算标量(Compute Scalar)。这个操作符的名字比较直观——进行一个标量计算并返回计算值。官方说明:Compute Scalar 运算符通过对表达式求值来生成计算标量值。该值可以返回给用户、在查询中的其他位置引用或二者皆可。例如,在筛选谓词或联接谓词中就会出现二者皆可的情况。
该操作符的图标为:
,它既是一个逻辑操作符,也是一个物理操作符。这个操作符可能不容易引起用户注意,因为一般我们看执行计划是因为语句有问题,而有问题的语句又通常是比较复杂或混乱的,这些语句生成的执行计划往往也非常复杂。相对于整个执行计划来说,这个操作符通常是比较小开销的。
但是这个操作符之所以重要或常见,是因为它通常是由于游标处理或其他一些大范围查找引起的,这些操作可能在CPU存在压力时变得雪上加霜。
演示:
使用TempDB做测试是一个不错的选择,简单重启一下SQL 服务即可清空过去的操作,不过如果你发现重启后还在,那不妨检查一下是否建到Model数据库或者设置为启动时运行。下面代码在TempDB中创建一个表,插入10000行数据后,循环100次进行数据检查:
USE tempdb
GO
CREATE TABLE test(ID Int Identity(1,1) PRIMARY KEY,
Name VarChar(250) DEFAULT NewID())
GO
SET NOCOUNT ON
GO
INSERT INTO test DEFAULT VALUES
GO 10000 --循环插入行数据
GO
--下面代码循环次,判断是否存在某个ID
DECLARE @I Int
SET @I = 0
WHILE @I < 100
BEGIN
IF EXISTS(SELECT ID FROM test WHERE ID = @I)
BEGIN
PRINT '存在这个ID'
END
SET @I = @I + 1;
END
看一下图形化执行计划:
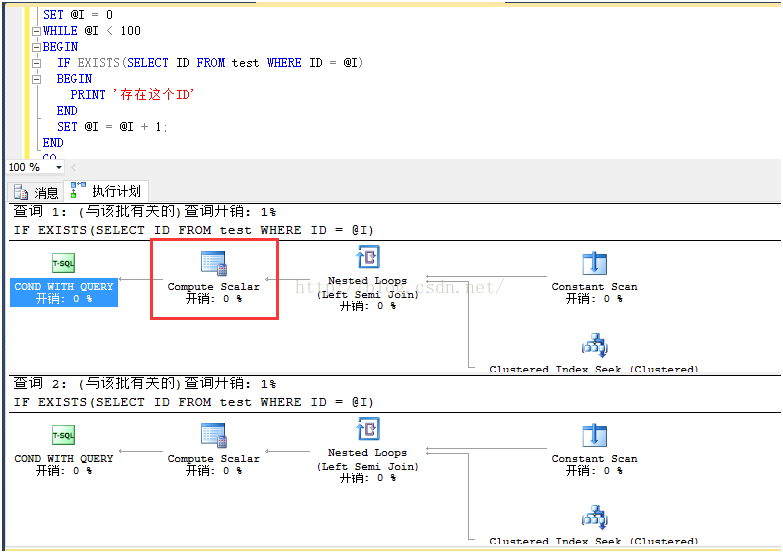
截图中红框部分表明使用了计算标量操作符,使用前面的方法,检查文本化执行计划:
SET SHOWPLAN_TEXT ON
GO
DECLARE @I Int
SET @I = 0
WHILE @I < 100
BEGIN
IF EXISTS(SELECT ID FROM test WHERE ID = @I)
BEGIN
PRINT '存在这个ID'
END
SET @I = @I + 1;
END

可以看到执行计划使用计算标量操作符来检查嵌套循环(Nested Loop)是否返回了值,也就是说用于实现IF EXISTS操作。
如果使用Profiler来抓取信息,记住一下CPU开销:

下面改写一下语句来避免这个操作符:
DECLARE @I Int, @Var Int
SET @I = 0
WHILE @I < 100
BEGIN
SELECT @Var = ID FROM test WHERE ID = @I
IF @@ROWCOUNT > 0
BEGIN
PRINT '存在这个ID'
END
SET @I = @I + 1;
END
GO
再看看图形化执行计划:

及Profiler信息:

如果再检查文本化执行计划就可以看到只有一个操作符:
[plain] view plain copy
1. |--Clustered Index Seek(OBJECT:([tempdb].[dbo].[test].[PK__test__3214EC27D8827737]), SEEK:([tempdb].[dbo].[test].[ID]=[@I]) ORDERED FORWARD)
对比Profiler中的数据,没有使用计算标量的执行计划消耗更少的CPU和运行时间去完成结果,这里主要是演示计算标量,所以不对写法做更深入的研究。但是从写法上看,使用了@@rowcount函数替代IF EXISTS,有时候会有一定的帮助,当然,并不是绝对的。
如果你觉得是数据量的原因,不妨再看看下面的脚本:
DECLARE @Tab TABLE(ID SmallInt PRIMARY KEY)
SELECT 'A' + ' - ' + 'B' FROM @Tab
然后看看图形化执行计划:

和文本化执行计划:
[plain] view plain copy
1. |--Compute Scalar(DEFINE:([Expr1002]='A - B'))
- 2. |--Clustered Index Scan(OBJECT:(@Tab))
这个语句只是简单地进行字符串拼接,但是也使用了计算标量运算符,原因可以查看执行计划的解释:
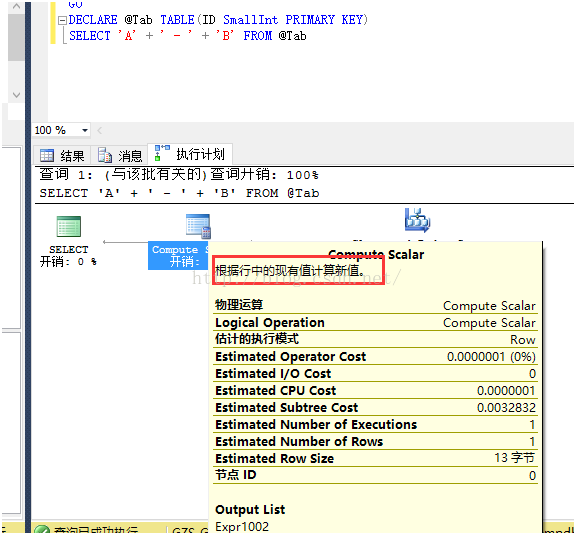
总结:
正如一直以来的解释,每个操作符的出现都有其原因和作用,并不能简单地下定论这个操作符是好还是坏,但是某些操作符确实意味着性能问题,所以如果精力允许,也应该对常见的操作符进行一定程度的研究。当发现某个低效查询中出现这个操作符时,不妨想想其原因,并尝试是否能进行优化,优化的原则则是根据其含义而定,既然这个操作符是根据现有值计算新值,那么我们的核心方案应该是减少这种操作的数据量或者预先计算新值。总的而言,具体情况具体分析。