前言: 索引对性能方面总是扮演着一个重要的角色,实际上,查询优化器首先检查谓词上的统计信息,然后才决定用什么索引。一般情况下,默认会在创建索引时,索引列上均创建统计信息。但是不代表在非索引键上的统计信息对性能没有用。 如果表上的所有列都有索引,那么将会是数据库负担不起,同时也不是一个好想法,包括谓词中用到的所有列加索引同样也不是好方法。因为索引会带来负载。因为需要空间存放索引,且每个DML语句都会需要更新索引。 一般来说,建议在where或者ON子句中出现的列上添加索引,但是由于某些情况,很难在所有的谓词上都创建索引,此时创建统计信息会是一个最起码的改进。如果Auto_Create_Statistics为ON,那么优化器会帮你做这一步。 准备工作: 默认情况下,Auto_Create_Statistics在数据库级别是设为ON的,但是为了下面需要这里先改成OFF: ALTER DATABASE AdventureWorks2012 SET AUTO_CREATE_STATISTICS OFF GO ALTER DATABASE AdventureWorks2012 SET AUTO_UPDATE_STATISTICS OFF GO 然后创建一个新表用于本文使用: SELECT * INTO SalesOrdDemo FROM Sales.SalesOrderHeader GO 步骤: 1、 对于新表,现在是没有统计信息在上面的,可以使下面语句来验证: SELECT object_id , OBJECT_NAME(object_id) AS TableName , name AS StatisticsName , auto_created FROM sys.stats WHERE object_id = OBJECT_ID('SalesOrdDemo') ORDER BY object_id DESC GO 因为没有统计信息,所以这个查询是没有数据的。 2、 现在在新表上创建一个聚集索引: CREATE CLUSTERED INDEX idx_SalesOrdDemo_SalesOrderID ON SalesOrdDemo(SalesOrderID) 3、 再次运行步骤一的脚本,可以看到已经有了数据,现在来执行下面的语句,并开启执行计划: SELECT s.salesorderid , so.SalesOrderDetailID FROM salesordDemo AS s INNER JOIN Sales.SalesOrderDetail AS so ON s.salesorderid = so.SalesOrderID WHERE s.duedate = '2005-09-19 00:00:00.000' 4、 下面截图是步骤3中的执行计划,关注一下SalesOrdDemo表上有聚集索引扫描,这是合理的,因为没有WHERE子句在使用SalesOrderID列。而SalesOrderDetails表有非聚集索引扫描。还可以看到实际行数和估计行数有很大差异。
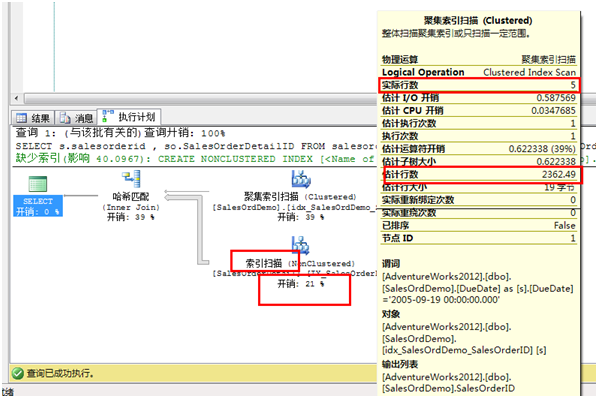
5、 现在是时候在新表的DueDate上创建统计信息,因为在查询中这个列并不包含在索引里面。 CREATE STATISTICS st_SaledOrdDemo_DueDate ON SalesOrdDemo(DueDate) GO 6、 再次执行步骤3的脚本,不需要任何改动: SELECT s.salesorderid , so.SalesOrderDetailID FROM salesordDemo AS s INNER JOIN Sales.SalesOrderDetail AS so ON s.salesorderid = so.SalesOrderID WHERE s.duedate = '2005-09-19 00:00:00.000' 7、 对比上面的执行计划,此时在SalesOrderDetails表上已经从非聚集索引扫描变成了聚集索引查找,且开销只有2%,更总要的是实际行数和预估行数相差无几:
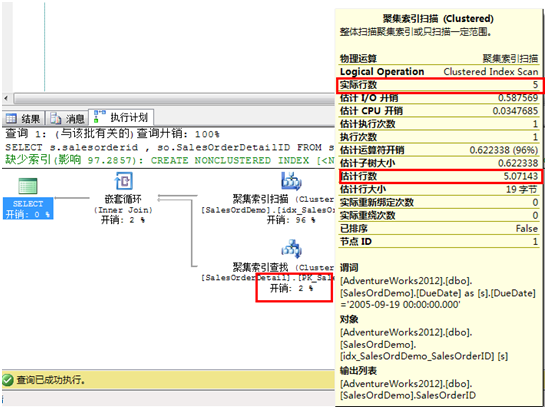
分析:
如果优化器可以获得谓词上列的统计信息,那么相会知道将要返回的行数,并且帮助优化器选择最佳的执行方式。