使用EXPLAIN查看mysql是如何处理sql语句的,查找性能问题点
生成随机字符
char(if(floor(rand()*2)=0,65+floor(rand()*26),48+floor(rand()*9)))
生成随机汉字
unhex(hex(19968+rand()*40868))
生成随机数字
RAND()*10000
循环操作
delimiter create procedure rantw() begin declare num int; set num=1; while num < 10000 do insert into test(name,title,count) values(char(if(floor(rand()*2)=0,65+floor(rand()*26),48+floor(rand()*9))),RAND()*10000,1) ; set num=num+1; end while; end
use ecommerce;
DROP PROCEDURE IF EXISTS ecommerce.BatchInsertCustomer;
delimiter
CREATE PROCEDURE BatchInsertCustomer(IN start INT,IN loop_time INT)
BEGIN
DECLARE Var INT;
DECLARE ID INT;
SET Var = 0;
SET ID= start;
WHILE Var < loop_time
DO
insert into test(`name`,title,count)
values(CONCAT('name_',rand(ID)*10000 mod 200),adddate('1995-01-01',(rand(ID)*36520) mod 3652),RAND()*100000);
SET Var = Var + 1;
SET ID= ID + 1;
END WHILE;
END;
delimiter ;
ALTER TABLE test DISABLE KEYS
CALL BatchInsertCustomer(100000,2000000);
ALTER TABLE test ENABLE KEYS;
MySql快速插入100w条数据方法
1、使用文件运行,通过程序,生成100w条数据至文件,利用mysql运行方式运行。
2、JAVA程序中使用多线程插入
3、通过事务控制,预处理sql,在达到指定数量的时候提交一次
SQL优化
统计表总数
-- 使用第二索引 -- 通过统计全表记录数时在where后面加一个有索引的字段作为条件来查询全表数据,如: -- 2-4s select count(*) from test; -- 4.650 select count(id) from test; -- 7.990 select count(1) from test; -- 3.860 select count(count) from test where count > 0; -- count 不为主键,count 有索引
索引
对于任何DBMS,索引都是进行优化的最主要的因素。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。
如果对多列进行索引(组合索引),列的顺序非常重要,MySQL仅能对索引最左边的前缀进行有效的查找。例如:
假设存在组合索引it1c1c2(c1,c2),查询语句select * from t1 where c1=1 and c2=2能够使用该索引。查询语句select * from t1 where c1=1也能够使用该索引。但是,查询语句select * from t1 where c2=2不能够使用该索引,因为没有组合索引的引导列,即,要想使用c2列进行查找,必需出现c1等于某值。
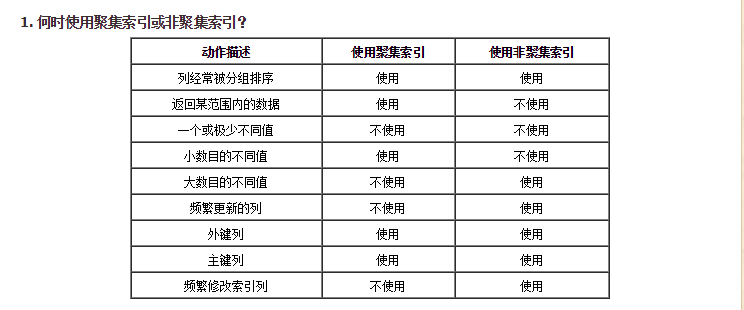
事实上,我们可以通过前面聚集索引和非聚集索引的定义的例子来理解上表。如:返回某范围内的数据一项。比如您的某个表有一个时间列,恰好您把聚合索引建立在了该列,这时您查询2004年1月1日至2004年10月1日之间的全部数据时,这个速度就将是很快的,因为您的这本字典正文是按日期进行排序的,聚类索引只需要找到要检索的所有数据中的开头和结尾数据即可;而不像非聚集索引,必须先查到目录中查到每一项数据对应的页码,然后再根据页码查到具体内容。其实这个具体用法我还不是很理解,只能等待后期的项目开发中慢慢学学了。
1、全文索引
表的存储引擎是MyISAM,默认存储引擎InnoDB不支持全文索引(新版本MYSQL5.6的InnoDB支持全文索引)
MySql自带的全文索引只能用于数据库引擎为MYISAM的数据表,如果是其他数据引擎,则全文索引不会生效。此外,MySql自带的全文索引只能对英文进行全文检索,目前无法对中文进行全文检索。如果需要对包含中文在内的文本数据进行全文检索,我们需要采用Sphinx(斯芬克斯)/Coreseek技术来处理中文。
注:目前,使用MySql自带的全文索引时,如果查询字符串的长度过短将无法得到期望的搜索结果。MySql全文索引所能找到的词默认最小长度为4个字符。另外,如果查询的字符串包含停止词,那么该停止词将会被忽略。
全文索引的缺陷:
数据表越大,全文索引效果好,比较小的数据表会返回一些难以理解的结果。
全文检索以整个单词作为匹配对象,单词变形(加上后缀,复数形式),就被认为另一个单词。
只有由字母,数字,单引号,下划线构成的字符串被认为是单词,带注音符号的字母仍是字母,像C++不再认为是单词
不区分大小写
只能在MyISAM上使用
全文索引创建速度慢,而且对有全文索引的各种数据修改操作也慢
乱七八糟的,真正吃透在整理吧