-
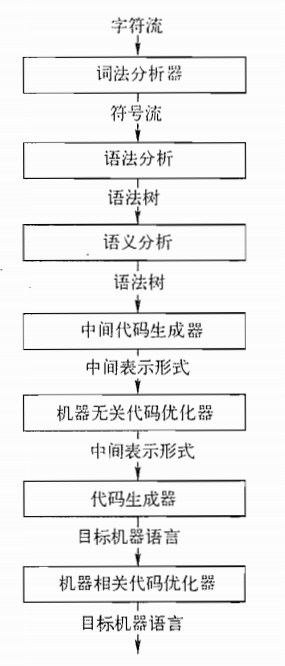
综合 :根据中间表示和符号表中的信息来构造用户期待的目标程序。
-
分析:把源程序,分解成多个要素,并在这些要素之上加上语法结构。然后,使用这个结构创建源程序的一个中间表示。如果分析部分检查出源程序没有按正确的语法构成,或者语义上不一致,就必须提供有用的信息。使用户可以按此来更改。还有收集有关源程序的信息,并把信息放在一个称为符号表的数据结构中。符号表和中间表示形式一起传送给综合部分。
-
词法分析:编译器的第一个步骤。词法分析器读入组成源程序的字符流,并将它们组织成有意义的词素的序列。对于每个词素,语法分析器产生如下形式的词法单元作为输出。
- <token-name,attribute-value>
-
这个词法单元被传送给下一个步骤,即语法分析。第一个分量token-name是一个由语法分析步骤使用的抽象符号,而第二个分量attribute-value指向符号表中关于这个词法单元的条目。符号表中关于这个词法单元的条目信息会被语义分析和代码生成使用。
-
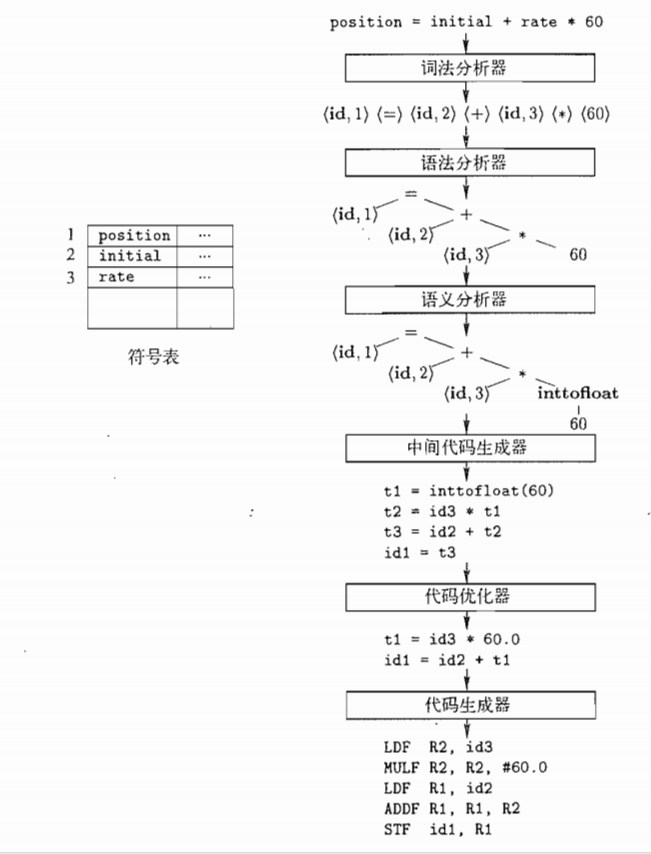
position=initial+rate*60
-
position是一个词素,被映射成词法单元<id,1>,其中id是表示标识符的抽象符号,1指向符号表中position对用的条目。一个标识符对应的符号表条目存放该标识符有关的信息,比如他的名字和类型。
-
赋值符号=是一个词素,被映射成词法单元。<=>.这个词法单元不需要属性值,所以省略第二个分量。也可以使用assign这样的抽象符号作为词法单元的名字。
-
分割词素的空格会被语法分析器忽略掉
-
语法分析:编译器的第二个步骤。语法分析器使用由词法分析器生成的各个词法单元第一个分量来创建树形的中间表示。该中间表示给出了词法分析产生的词法单元流的语法结构。一个常用的表示方法是语法树,树中的每个内部节点表示一个运算,而该节点的子节点表示该运算的分量。
-
语义分析:使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。同事也收集类型信息,并把这些信息存放到语法树或符号表中。语义分析一个重要的部分是类型检查。编译器检查每个运算符是否具有匹配的运算分量。
-
程序涉及语言,可能允许某些类型转换,被称为自动类型转换。
-
中间代码生成
- 把一个源程序,翻译成目标代码的过程中,一个编译器可能构造出一个或者多个中间表示。这些中间表示可以有多种形式。语法树是一种中间表示形式,他们通常在语法分析和语义分析中使用。
-
三地址指令
- 每个三地址赋值指令,右部最多只有一个运算符。这些指令确定了运算完成的顺序。
- 乘法应该在加法之前完成
- 编译器应该生成一个临时名字以存放一个三地址指令计算得到的值。
- 有些三地址指令的运算分量少于三个
- 每个三地址赋值指令,右部最多只有一个运算符。这些指令确定了运算完成的顺序。
-
代码生成
- 代码生成器,以源程序的中间表示形式作为输入,并把它映射到目标语言。如果目标语言是机器代码。必须为程序使用的每个变量选择寄存器或内存位置,然后中间指令被翻译成,能够完成相同任务的及其指令序列。
-
符号表管理
- 编译器的重要功能之一是记录源程序中使用变量的名字。并收集每个名字的各种属性有关的信息。这些属性可以提供一个名字的存储分配、他的类型、作用域(程序在哪些地方可以使用这个这个名字的值)。他的参数数量和类型、每个参数的传递方式(值传递或引用传递)以及返回类型。
- 符号表数据结构,为每个变量名字创建了一个记录条目。记录的字段就是名字的各个属性。这个数据结构允许编译器快速查找每个名字的记录,并向纪录中快速存放和获取记录中的数据。