Storm 系列(二)实时平台介绍
本章中的实时平台是指针对大数据进行实时分析的一整套系统,包括数据的收集、处理、存储等。一般而言,大数据有 4 个特点: Volumn(大量)、 Velocity(高速)、 Variety(多样)、 Value(价值),因此针对大数据的实时平台有以下特点。
- 延退 :高延迟意味着实时性的缺失。
- 分布式 :互联网时代,大多数的系统都是部署在一套由多台廉价 Linux 服务器组成的集群上。
- 高性能 :高速产生的大量数据,通过计算分析获取其中的价值,这需要高性能可靠的处理模型。
- 高扩展性 :整个系统要有较强的扩展性,数据井喷时能够通过快速部署解决系统的实时需求。而事实上,随着业务的增长,数据量、计算量会呈指数级增长,所以系统的高扩展性是必须的。
- 容错性 :整个系统需要有较强的容错性,一个节点宕机不影响业务。
同时,对于应用开发者而言,平台上运行的应用程序容易开发和维护。各处理逻辑的分布、消息的分发以及消息分发的可靠性对于应用开发者是透明的。对于运维而言,平台还需要是可监控的。
结合互联网大数据应用的特点,我们基于 Storm 构建了实时平台。
2.1 实时平台架构介绍
当网站或者 APP 到达一定的用户量后,一般需要一套 Tracker 系统(如图 2-1 所示),收集用户行为(如用户 IP 地址、页面来源、城市名、浏览器版本、按钮位置等)、页面访问性能、异常出错等信息,然后根据一定的策略上报到日志服务器。搜索、推荐、广告选品中心等开发团队分析这些日志,可以调整和开发各种功能;产品经理、高级管理人员等通过这些日志及时优化营运并进行正确决策;运维和应用开发人员根据这些日志进行排错和迭代产品等。 Tracker 系统在一个成熟的应用中扮演着重要的角色,随着业务的发展,对它的实时性要求也越来越高。
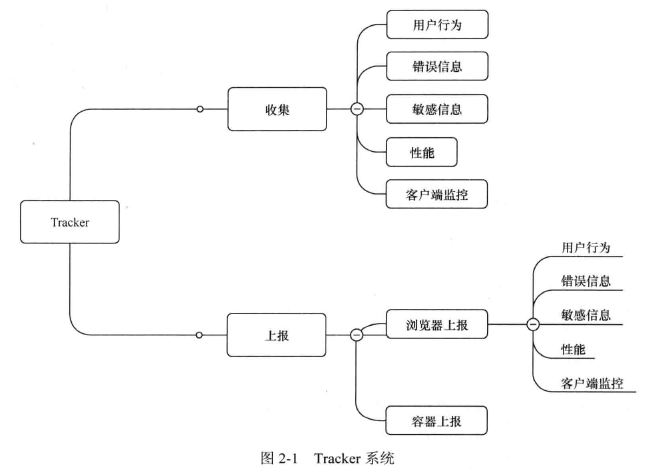
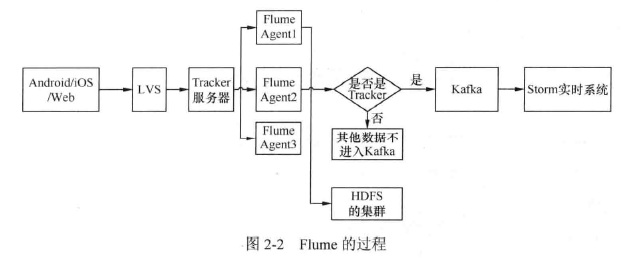
Tracker 系统一般采用 Javascript 语言开发,支持自动打点字段、自动扩展字段等,在网站或者应用的各个页面的事件中嵌入 Tracker 系统的 API,设置一定的策略发送到日志服务器,然后再同步到 Kafka 等消息队列。对于需要实时日志的应用,一般通过 Storm 等流式计算框架从消息队列中拉取消息,完成相关的过滤和计算,最后存到 Hbase、 MYSQL 等数据库中;对于实时性要求不高的应用,消息队列中的日志消息通过 Cloudera 的 Flume 系统 Sink 到 HDFS 中,然后后一般通过 ETL、Hive 或者批处理的 Hadoop 作业等抽取到 Hbase、MYSQL 等数据库中。如图 2-2 所示,日志服务器的数据也可以通过 Flume 系统 Sink 到 Kafka 等消息队列中,供 Storm 实时时处理消息。
2.2 Kafka 架构
在 Kafka 的官方介绍中, Kafka 定义为一个设计独特的消息系统。相比于一般的消息队列, Kafka 提供了一些独特的特性,非常高的吞吐能力,以及强大的扩展性。本小节将简单介绍 Kafka。
2.2.1 Kafka 的基本术语和概念
Kafka 中有以下一些概念。
- Broker :任何正在运行中的 Kafka 示例都称为 Broker。
- Topic :Topic 其实就是一个传统意义上的消息队列。
- Partition:即分区。一个 Topic 将由多个分区组成,每个分区将存在独立的持久化文件,任何一个 Consumer 在分区上的消费一定是顺序的;当一个 Consumer 同时在多个分区上消费时, Kafka 不能保证总体上的强顺序性(对于强顺序性的一个实现是 Exclusive Consumer,即独占消费,一个队列列同时只能被一个 Consumer 消费并且从该消费开始消费某个消息到其确认才算消费完成,在此期间任何 Consumer 不能再消费)。
- Producer :消息的生产者。
- Consumer :消息的消费者。
- Consumer Group :即消费组。一个消费组是由一个或者多个 Consumer 组成的,对于同一个 Topic,不同的消费组都将能消费到全量的消息,而同一个消费组中的 Consumer 将竞争每个消息(在多个 Consumer消 费同一个 Topic 时, Topic 的任何个分区将同时只能被一个 Consumer 消费)。
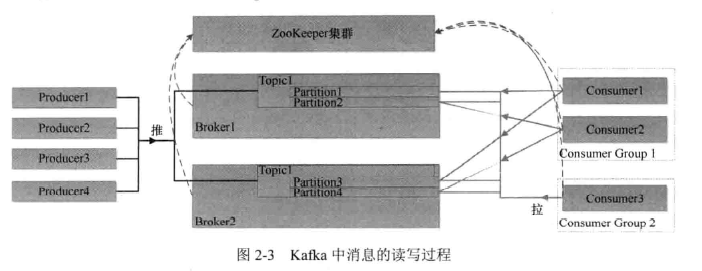
如图 2-3 所示,在 Kafka 中,消息将被生产者“推”(push)到 Kafka 中, Consumer 会不停地轮询从 Kafka 中“拉”(pull)数据。
2.2.2 Kafka 在实时平台中的应用
在工作环境中,流式计算平台架构如图 2-4 所示。
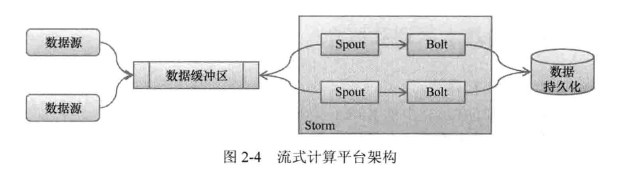
用户访问会源源不断地产生数据,数据要么存储在本地并在需要时发送到相关的应用,要么存储到一个统一的中央存储区中。产生的数据会被 Storm 中的 Spout 抓取、过滤并进行相关处理(例如应用之间协议解析、格式分析、数据据校验等),然后发送到 Bolt 中进行数据分析,最终形成可用数据并存储到持久化介质(如 DB)中,供其他应用获取。
数据暂存区的意义在于,首先数据是随着用户的访问而产生的,一般的平台在数据产生后要向其他分析程序“推”数据,而 Storm 是主动抓取数据并进行分析处理,是“拉”;其次即便在 Storm 中实现一个能够接受“推”的模型(如在 Spout 中增加内存队列等),当数据源突然增加时有可能导致 Storm 上应用并发度不足而引起其他状况,此时相当于对 Storm 发起一次 DoS 攻击。因此,去掉数据暂存区对 Storm 的维护、整个平台的运维而言都不是非常好的选择。
很多大数据实时平台的数据暂存区选用了 Kafka,是基于 Kaka 的以下优点。
- 高性能 :每秒钟能处理数以千计生产者生产的消息,详尽的数据请参考官网的压力测试结果。
- 高扩展性 :当 Kafka 容量不够时可以通过简单增加服务器横向扩展 Kafka 集群的容量。
- 分布式 :消息来自数以千计的服务,数据量比较巨大,单机显然不能处理这个量级的数据,为解决容量不足、性能不够等状况,分布式是必需的。
- 持久性 : Kafka 会将数据持久化到硬盘上,以防止数据的丢失。
- Kafka相对比较活跃 : 在 Storm 0.9.2 中, Kafka 已经是 Storm Spout 中的可选 Spout。
本节将简单描述 Kafka,关于其更详尽的信息请直接参考 Kafka 官方文档: http://Kafka.apache.org/documentation.html
Kafka 是由 LinkedIn 开源的高效的持久化的日志型消息队列,利用用磁盘高效的顺序读写特性使得在很多场景下,瓶颈甚至不在于磁盘读写而在于网络的传输上。与 Amazon 的 Dynamo 引领了一批 NOSQL 类似, Kafka 的设计哲学很值得借鉴,在国内很多公司内部的消息队列中均能够看到 Kafka 的身影,如 makfa、 metaq、 queue 等。以下将简单介绍 Kafka,关于 Kafka 更多的内容详见附录 A 或者请查阅官方文档。
2.2.3 消息的持久化和顺序读写
Kafka 没有使用内存作为缓存,而是直接将数据顺序地持久化到硬盘上(事实上数据是以块的方式持久化的),同时 Kafka 中的每个队列可以包含多个区并分别持久化到不同的文件中。关于顺序读写的分析,在 Kafka 的官方介绍中有这样的描述:“在一个 6 * 7200rpm SATA RAIL-5 的磁盘阵列上线性写的速度大概是 300MB/S,但是随机写的速度只有50KB/s。”
2.2.4 sendfile 系统调用和零复制
在数据发送端, Kafka 使用 sendfile 调用减少了数据从硬盘读取到发送之间内核态和用户态之间的数据复制。
传统上,当用户需要读取磁盘上的数据并发送到客户端时,会经历这样的步骤:打开文件磁盘上的文件准备读取,创建远端套接字(socket)的连接,循环从磁盘上读取数据将读取到的数据发送出去,发送完成后关闭文件和远端连接。仔细分析其中的步骤,我们会发现,在这个过程中,一份数据的发送需要多次复制。首先,通过 read 调用每次从磁盘上读取文件,数据会被从磁盘上复制到内核空间,然后再被复制到读取进程所在的用户空间。其次,通过 write 调用将数据从进程所在的用户空间发送出去时,数据会被从用户空间复制到内核空间,再被复制到对应的网卡缓冲区,最终发送出去。期间数据经历了多次复制以及在用户态和内核态之间的多次转换,每一次都将产生一个非常昂贵的上下文切换,当有大量的数据仅仅需要从文件读出并被发送时代价会非常大。
sendfile 系统调用优化了上述流程:数据将首先从磁盘复制到内核空间,再从内核空间复制到发送缓冲区,最终被发送出去。在 Linux 系统中, sendfi1e 可以支持将数据发送到文件、网络设备(网卡)或者其他设备上。 sendfile 是 Kernel2.2 提供的新特性(从 glibc 2.1 开始提供头文件 <Sys/sendfile.h>)
图 2-5 中简单对比了使用一般 read/write 和使用 sendfile 将数据从硬盘中读出并发送的过程。
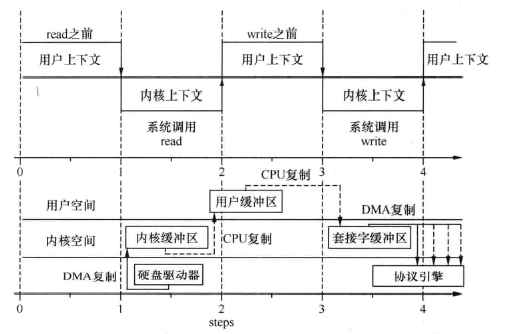
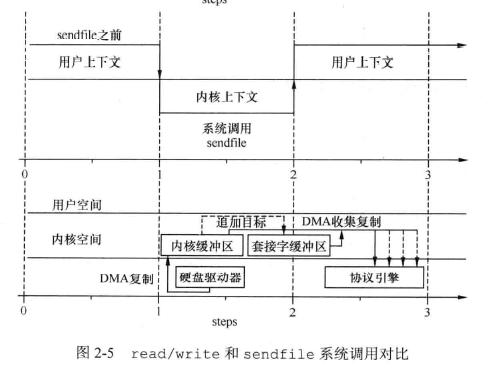
通过分析,我们可以发现,通过简单 的read/ rite 读取并发送数据,需要 4 次系统调用以及 4 次数据复制;而使用 sendfile 只产生 2 次系统调用及数据复制。由于每一次空间切换内核将产生中断、保护现场(堆栈、寄存器的值需要保护以备执行完成后切换回来)等动作,每一次数据复制消耗大量 CPU。 sendfile 对这两个优化带来的变化是数据发送吞吐量提高,同时减少了对CPU 资源的消耗。当存在大量需要从硬盘上发送的数据时,其优势将非常明显。也正因此,很多涉及文件下载、发送的服务都支持直接 sendfile 调用,如 Apache httpd、 Nginx、 Lighttpd 等。
2.2.5 Kafka的的客户端
Kafka 目前支持的客户端有 CC++、Java、.NET、 Python、Ruby、Perl、 Clojure、 Erlang、Scala 等,甚至还提供了 HTTP REST 的访问接口。
在消息生产端,可以预定义消息的投放规则,如某些消息该向哪个 Partition 发送(如可以按照消息中的某个字段,如用户字段,进行哈希,使得所有该用户的消息都发送到同个 Partition 上)。
在消息的消费端,客户端会将消息消费的偏移量记录到 Zookeeper 中。如果需要事务性的支持,可以将偏移量的存储放在事务中进行:除非消息被消费并被处理完成,否则事务的回滚将满足再次消费的目的。
2.2.6 Kafka 的扩展
Kafka依赖于 Zookeeper,集群的扩容非常方便,直接启动一个新的节点即可。对于已存在的消息队列, Kafka 提供了相关的工具(kafka-reassign partitions.sh)将数据迁移到新节点上。在 0.8.1 版本中,该工具尚不能在保证迁移的同时保证负载均衡。
2.3 大众点评
实时平台大众点评网于 2003 年 4 月成立于上海。大众点评网是中国领先的城市生活消费平台,也是全球最早建立的独立第三方消费点评网站。大众点评不仅为用户提供商户信息消费点评及消费优惠等信息服务,同时亦提供团购、餐厅预订、外卖及电子会员卡等 O2O( Online to Offline)交易服务。大众点评网是国内最早开发本地生活移动应用的企业业,目前己经成长为一家领先的移动互联网公司,大众点评移动客户端已成为本地生活必备工具。
2.3.1 相关数据
截止到 2014 年第三季度,大众点评网月活跃用户数超过 1.7 亿,点评数量超过 4200 万条,收录商户数量超过 1000 万家,覆盖全国 2300 多个城市及美国、日本、法国、澳大利韩国、新加坡、泰国、越南、马来西亚、印度尼西亚、柬埔寨、马尔代夫、毛里求斯等近百个热门旅游国家和地区。
截止到 2014 年第三季度,大众点评月综合浏览量(网站及移动设备)超过 8 0亿,其中移动客户端的浏览量超过 80%,移动客户端累计独立用户数超过 1.8 亿。目前,除上海总部之外,大众点评已经在北京、广州、天津、杭州、南京等130座城市设立分支机构。
2.3.2 实时平台简介
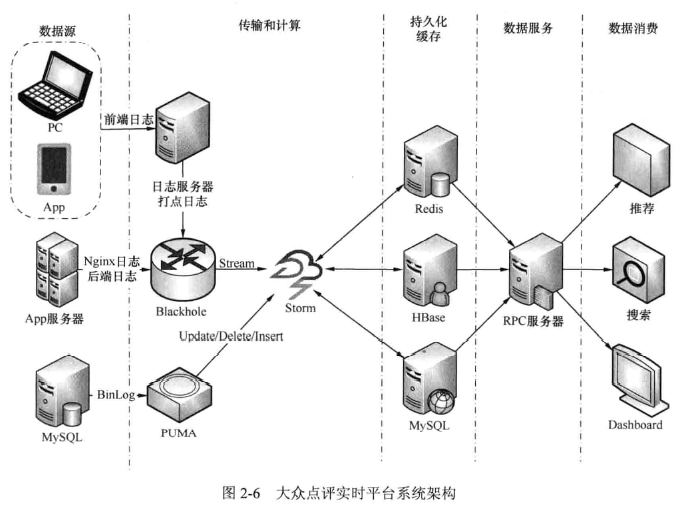
目前大众点评的实时数据平台经过一段时间的搭建已经基本成型。平台包括了一系列的工具和系统,大部分系统是在原有系统的基础上适当增加功能来完成。主要部分包括了日志打点和收集系统、数据传输和计算平台、持久化数据服务以及在线数据服务等部分。
(1) 日志的传输和收集,主要依赖 Blackhole 和 Puma 来完成。 Blackhole 是一个大众评自己开发的类似于 Kafka 的分布式消息系统,收集了除 MYSQL 日志以外的所有数据源的日志,并以流的形式提供了批量和实时两种数据消费方式。2.3.3 节将具体介绍 Blackhole。Puma 是以 MYSQL 从节点(slave node)的方式运行,接收 MYSQL 的 binlog 解析 binlog,然后以MQ 的形式提供数据服务。
日志打点和收集系统包括了以下几个日志数括源。
-
浏览器自助打点服务,供产品经理和运营人员,数据分析人员在页面上配置打点配置完成后,系统自动将需要打点的地方推送到前端网页上,用户浏览网页时候的点击行为以及鼠标悬停等就会触发相应的日志数据,实时传回后端的日志服务器。
-
在大众点评的 3 个主要 APP(大众点评、大众点评团和周边快查)的框架中内含了所有页面的按钮、页面滑动以及页面切换等的埋点,只要用户有相应的操作,就会记录日志,批量发送到日志服务器。
-
此外,同其他平台的合作(如微信、QQ 空间等)也有相应的埋点,记录对应的日志。
以上所有的用户浏览日志数据加上后端应用的日志、 Nginx 日志和数据库的增删改志等,一并通通日志收集系统实时地传输到日志的消费方(主要是 Storm 中的 Topology)。其他的数据源还包括 MQ 系统,由应用在执行过程中产生。
(2) Storm 是实时平台的核心组成部分,目前在 Storm 上运行了几十个业务 Topology,日处理数据量在百亿级,峰值的数据 TPS 在 10 万左右。随着大众点评业务的发展,数据处理量仍在快速增加。
(3) Topology 中 Bolt 计算的结果数据和中间交换数据根据业务需求存放在 Redis、 Hbase 或者 MYSQL 中。
(4) 数据持久化到相应的数据库中后,由 RPC 服务器提供对外统一的访问服务,用户不用关心数据存储的细节、位置和容错,直接获取数据。
整个平台的系统架构如图 2-6 所示
2.3.3 Blackhole
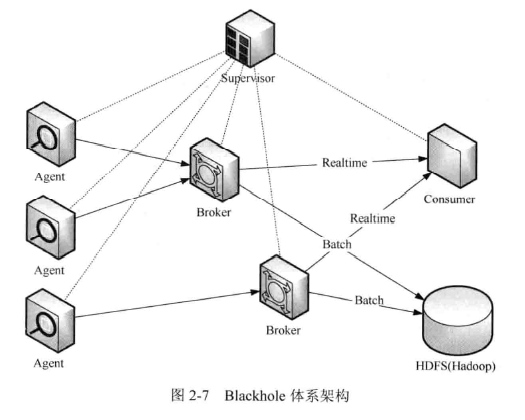
Blackhole 是类似于 Kafka 的的一个流式系统,是大众点评的数据收集和订阅消费的平台。数据仓库的所有日志数据都是由 Blackhole 来完成收集并存入HDFS 中的。 Blackhole 每天收集超过 2TB 的日志数据。 Blackhole 的 Agent 同其他平台工具一起部署在所有的几千台线上机器中,批量日志收集保证数据无丢失,实时数据保证高实效性和高性能。
Blackhole 具有良好的水平扩展性和容错能力。内部基于行为(actor-based)的分布式系统实现系统的高性能:采用 Kafka 类似的提交日志(commit log)保证数据完整性。在 Blackhole 中,分为 4 类角色,即 Supervisor、 Broker、 Agent 和 Consumer。
- Supervisor: Supervisor 是管理者,负责所有的调度以及元数据管理。 Agent、 Broker 、 Consumer 都和 Supervisor 维持了心跳信息,如果某个 Broker 失败了, Supervisor 会让这个 Broker 连接的 Agent 和 Consumer 转移到其他 Broker 节点上。进行相应的动态扩容以后, Supervisor 会发起 rebalance 操作,保持负载均衡。
- Broker: Broker 是数据的管理者。 Agent 向 Broker 上报数据, Broker 会在本地磁盘缓存数据,用于可靠性保障。 Consumer 向 Broker 发送数据所在文件位置的偏移量,获取对应具体的数据。同一个数据源的数据会发送到多个 Broker 中以达到负载均衡的效果。同时 Broker 会批量地将日志文件上传到 HDFS 中,用于后续的作业和各种数据分析。
- Agent: Agent 监听相应的日志文件,是数据的生产者,它将日志发送到 Broker。
- Consumer: Consumer 实时地从 Broker 中获取日志数据。通常将 Storm 的 Spout 作为具体的 Consumer 来消费数据。
Blackhole 体系架构如图 2-7 所示。
2.4 1号店实时平台
1号店于 2008 年 7 月成立于上海,开创了中国电子商务行业“网上超市”的先河。至 2013 年底,覆盖了食品饮料、生鲜、进口食品、美容护理、服饰鞋靴、厨卫清洁用品母婴用品、数码手机、家居居用品、家电、保健器械、电脑办公、箱包珠宝手表、运动户外礼品等等 14 个品类。1 号店是中国第一家自营生鲜的综合性电商;在食品饮料尤其进口食品方面,牢牢占据中国 B2C 电商行业第一的市场份额;进口牛奶的销量占到全国海关进口总额的 37.29%;在洗护发、沐浴、女性护理、口腔护理产品等细分品类保持了中国 B2C 电商行业第一的市场份额;手机在线销售的市场份额跻身中国B2C电商行业前三名。
1号店拥有 9000 万注册用户,800多万的SKU,2013年实现了1154亿元的销售业绩,数据平台处理3亿多的独立用户ID(未登录用户和登录用户),100T 的数据量。
2013 年规划1号店实时平台时,主要的应用为个性化推荐、反爬虫、反欺诈分析、商铺订单、流量实时分析和BI实时报表统计。平台搭建之初,已上线的应用中每天需要实时分析的数据量峰值在450GB左右,秒级别延迟。基于 Storm 的流计算也同样适用于搜索实时索引、移动端流量分析、广告曝光数据分析、风险控制和移动端访问数据分析等应用场景。
和所有互联网公司大数据分析服务一样,1 号店的数据服务包括数据的采集、收集、分析、持久化、应用引擎、推送和展示等。数据的收集主要来自基于 Javascript 的内部实现的服务(如 Tracker、基于开源的 Haproxy 的日志等),数据收集后,部分要求准实时的服务会暂时持久化到硬盘上,后通过 Flume(这里使用的 Flume 是 Flume-ng 版本 1.4,以下不再赘述)、 syslogd 等推送到 Kafka 中, Storm 上的实时应用实时获取 Kafka 中的数据进行分析,并将结果持久化供相关业务使用和展示。
1 号店实时处理平台架构如图 2-8 所示。
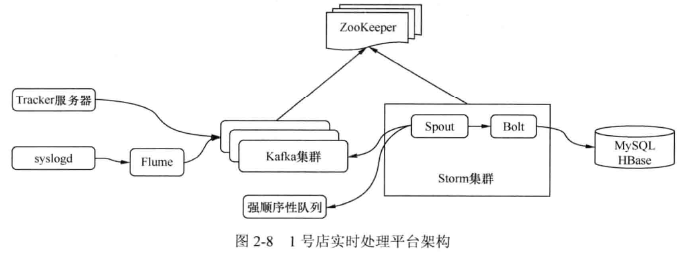
整个平台用于处理用户访问产生的数据,包括行为数据、 HALog、广告曝光数据和流量数据等,数据会在产生的第一时间被收集并发送到日志转发服务(如 Scribe、 Flume)上,然后由日志转发服务将其推到到 Kafka 对应的 Topic 中。如果需要通过 Hadoop 计算全量,也会推送到 HDFS 中。运行在 Storm 中的应用会读取 Kafka 中的数据进行分析,并将分析结果持久化到持久化层中。推送引擎主动获取持久化层中的数据,将处理结果推送到对应的业务系统并最终展示给用户。在整个平台中,使用 Flume 作为数据推送组件是基于以下几点考虑。
- Flume 能够接收多种数据源,包括获取控制台输出、tail、 syslogd、exec 等,支持 TCP 和 UDP 协议。
- Flume 支持基于内存、文件等通道,数据在转发到相关服务之前暂时存放于通道内。
- Flume 支打持多种数据推送,如将数据推送到 HDFS、 MYSQL、 Hbase、 Mongodb 中。
- Fume 有着非常优雅的实现,通过编写相应的 plugin,能够轻易扩展支持其他类型的数据源和推送
- Flume 具有高性能
使用 Kaka 作为数据的缓存主要是基于以下几点考虑。
- 某些数据会被多种业务使用,如访问日志,既用于反爬虫分析也用于反欺诈、反注入分析,一个同样的数据会被消费多次,而 Kafka 能够满足该需求。
- 从实时平台而言, Storm 中 Spout 的消息消费类型属于“拉”模式,而数据产生服务属于“推”模式(有访问就有数据),中间需要同时支持“推”和“拉”的消息平台。
- Kafka 在单台 6 块硬盘的服务器上实测峰值能够达到 600Mbit/s,数据的产生和消费是准实时的,性能上是可以接受的。对于互联网应用而言,数据的高峰可能是间歇性、井喷性的,如“大促”、“周年庆”、“双11”等日时段的流量可能是平时的 5 倍甚至 10 倍。从就成本而言,与其维打个容量为平时流量 10 倍的集群倒不如维护一个容量为平时 2~3 倍容量而数据井喷时允许一定的延迟的集群更划算些。
每天用心记录一点点。内容也许不重要,但习惯很重要!
本文来自 《Strom 技术内幕与大数据实践》 一书。