Q-learning algorithm: learning the Action Value Function
The Action Value Function takes two inputs:state and action,it returns the expected future reward of that action at that state.
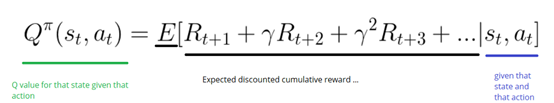
Before exploring,the Q-table gives the same arbitrary fixed value(most of time 0).As we explore the environment,the Q-table will give us a better and better approximation by iteratively updating Q(s,a) using Bellman Equation.


Step1: Initialize Q-values
We build a Q-table, with m cols (m= number of actions), and n rows (n = number of states). We initialize the values at 0.
Step 2: For life (or until learning is stopped)
{步骤3-5 会持续进行,直到循环次数停止,或者手动停止
Step 3: Choose an action
我们基于当前的状态和当前状态的Q值估计选择Action
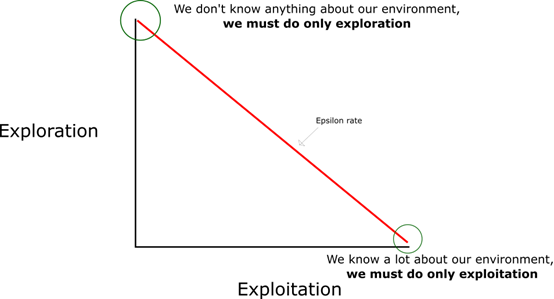
对于开始(All of values are 0),我们用到了探索利用权衡的方法:
在开始,我们使用了epsilon的贪婪策略。
我们设置epsilon的值,初始值为1,其含义是我们随机操作(探索)的概率。在开始的时候,这个概率一定是最高的值,因为我们不知道关于Q-table的任何值的信息,这意味着我们需要通过随机选择我们的action来做大量的探索。
我们生产一个随机数,如果这个数字大于epsilon,我们将利用,即选择我们已知的最好的action,否则我们探索。我们必须保证探索的概率逐渐降低,如图所示:
Steps 4–5: Evaluate!
执行动作action a(上一步得到),观察结果state s 和 reward r。用Bellman公式更新Q function表格。

}