OUTLINE
pivot()的用途可以简单理解为:
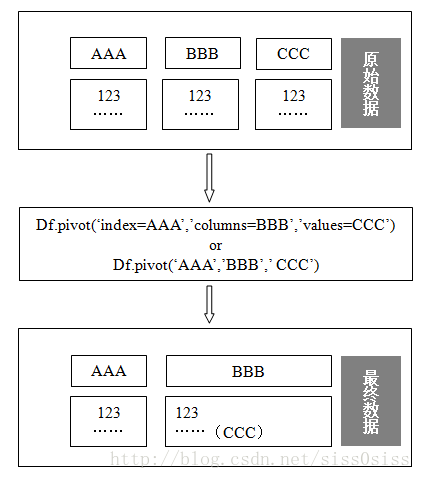
将一个DataFrame的记录数据整合成表格(类似Excel中的数据透视表功能),而且是按照pivot(‘index=xx’,’columns=xx’,’values=xx’)来整合的。
还有另外一种写法,但是官方貌似并没有给出来,就是pivot(‘索引列’,‘列名’,‘值’)。
数据变化图示:
官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pivot_table.html
(在数据分析的时候要记得将pivot结果reset_index())
函数说明
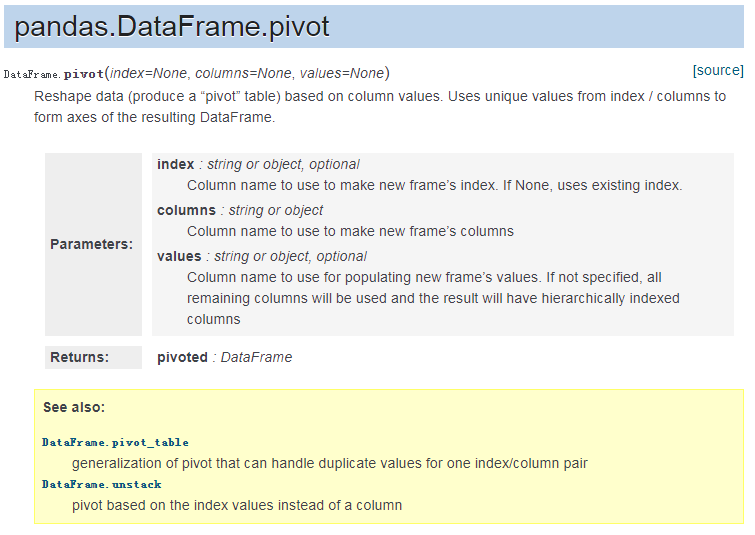
DataFrame.pivot(index=None, columns=None, values=None) 功能:重塑数据(产生一个“pivot”表格)以列值为标准。使用来自索引/列的唯一的值(去除重复值)为轴形成dataframe结果。 为了精细调节控制,可以看和stack/unstack方法有关的分层索引文件。 在数据分析的时候要记得将pivot结果reset_index()。 参数:index : string or object, optional 用于创建新框架索引的列名称。 如果没有,则使用现有的索引。 columns : string or object 用于创建新框架列的列名称 values : string or object, optional 用于填充新框架值的列名称。 如果未指定,则将使用所有剩余列,结果将具有分层索引列 返回:DataFrame
使用示例
下图是进行数据重塑之前的数据集,数据集包含三个字段的内容,分别是:name, year, gdp
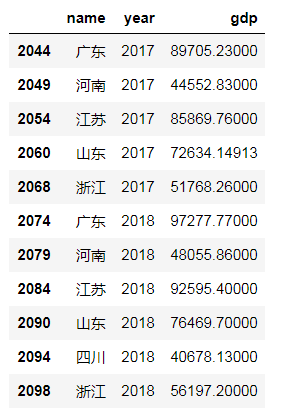
采用pivot函数对数据集进行重塑
#对数据进行重塑 df = df.pivot(index='name',columns='year',values='gdp') df = df.reset_index() df.fillna(1.0,inplace=True) df
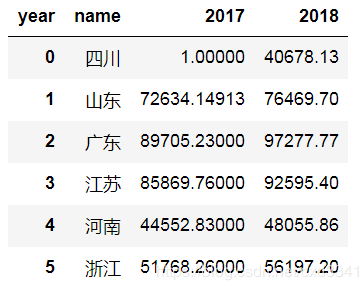
df = df.pivot(index='name',columns='year',values='gdp')的功能 新数据集索引列 = 原数据集'name'列中的值 新数据集列名 = 原数据集‘year’列中的值 新数据集数据 = 原数据集'gdp'列中的值
转换关系图示:

文章出处:https://blog.csdn.net/cxd3341/article/details/105016903